Numerical Analysis: A Linear Algebra Story
Shortcut to this page: ntrllog.netlify.app/linear
Notes provided by Professor Alex Cloninger (UCSD)
Linear algebra is all about solving `Ax = b,` where, usually, `A` is an `n xx n` matrix, `x` is an `n xx 1` matrix, and `b` is an `n xx 1` matrix. Specifically, given `A` and `b,` find `x`. In other words, if the problem is
`[[a_(1,1), a_(1,2), ..., a_(1,n)],[a_(2,1), a_(2,2), ..., a_(2,n)],[vdots, vdots, ddots, vdots],[a_(n,1), a_(n,2), ..., a_(n,n)]] [[x_1], [x_2], [vdots], [x_n]] = [[b_1], [b_2], [vdots], [b_n]]`
where we know all the `a` and `b` values, what values of `x` make that true?
Concretely, what values of `x_1, x_2,` and `x_3` make this equation true?
`[[1, 4, 1],[8, 2, 0],[5, 6, 2]][[x_1],[x_2],[x_3]] = [[24],[32],[49]]`
Of course, we could try plugging in random values for x and hope that they work. But that would take forever. Even if we did it with a computer, it would be impractical to do so all the time.
Finding `A^-1`
A slightly better approach would be to "isolate" the `x`. As from elementary algebra, we could solve for `x` in `5x = 10` by dividing both sides by `5`. So, for `Ax = b`, why not "divide" both sides by `A`? (More formally known as taking the inverse). There are some special cases in which it is impossible to take the inverse of `A`, so for simplicity, we avoid those cases and assume it is possible, i.e., `A` is "invertible".
In theory, the answer really is that simple. Multiply both sides (on the left) by the inverse of `A` (denoted by `A^-1`) to get `x = A^-1b`. Done. In practice, though, this process is actually pretty complicated and time-consuming, especially when done by hand. In fact, doing it by hand is so nightmarish, let's assume we have a computer program that inverts and multiplies matrices for us. It turns out that even with a computer doing millions of operations in mere milliseconds, inverting a matrix and then multiplying is relatively time-consuming.
It's natural to assume that if a program needs to do a lot of operations `(+,-,xx,//,sqrt())`, it will take longer than one that needs to do fewer operations. Inverting an `n xx n` matrix is complicated (for me to know), but it turns out that it generally takes `n^3` operations. This is quite a lot of operations. It also means that if you double the size of the matrix, you have to do `8` times more operations to find its inverse. (`2 xx 2` matrix: `8` operations, `4 xx 4` matrix: `64` operations) Most matrices in real life are really large. (`1,000,000 xx 1,000,000` is likely a conservative estimate. That would mean `1,000,000^3` operations.)
The story thus far: We're trying to solve `Ax = b`. (Given `A` and `b`, find `x`.) In theory, the simplest approach is to multiply both sides by `A^-1` to get `x = A^-1b`. In practice, this approach is not simple at all. Compared to other methods of solving this problem, finding `A^-1` is time-consuming.
Time complexity of finding `A^-1`: `n^3`
Assumptions about `A`: invertible
Triangular Systems
Let's assume `A` can be "split up" into two matrices: one lower-triangular matrix (denoted by `L`) and one upper-triangular matrix (denoted by `U`). So `A = LU:`
`[[a_(1,1), a_(1,2), ..., a_(1,n)],[a_(2,1), a_(2,2), ..., a_(2,n)],[vdots, vdots, ddots, vdots],[a_(n,1), a_(n,2), ..., a_(n,n)]] = [[l_(1,1), 0, ..., 0],[l_(2,1), l_(2,2), 0, vdots],[vdots, vdots, ddots, 0],[l_(n,1), l_(n,2), ..., l_(n,n)]] [[u_(1,1), u_(1,2), ..., u_(1,n)],[0, u_(2,2), ..., u_(2,n)],[vdots, 0, ddots, vdots],[0, ..., 0, u_(n,n)]]`.
Note: Lower-triangular means `0`s on top right and numbers on bottom left. Upper-triangular means numbers on top right and `0`s on bottom left.
For example,
`[[6, 4, 2, 2],[-3, 0, 3, 5],[9, 7, 7, 5],[12, 9, 12, 16]] = [[2, 0, 0, 0],[-1, 2, 0, 0],[3, 1, -1, 0],[4, 1, -3, 3]] [[3, 2, 1, 1],[0, 1, 2, 3],[0, 0, -2, 1],[0, 0, 0, 4]]`
The problem now becomes `(A)x = b => (LU)x = b.` Where do go from here? The answer lies in the special property of lower- and upper-triangular matrices. (Specifically, the zeros.)
First of all, it is quite easy to solve something like `Lx = b`. For example,
`[[color(red)(5), color(red)(0), color(red)(0)],[color(blue)(2), color(blue)(-4), color(blue)(0)],[color(green)(1), color(green)(2), color(green)(3)]] [[x_1],[x_2],[x_3]] = [[color(red)(15)],[color(blue)(-2)],[color(green)(10)]]`
`color(red)(5)x_1 + color(red)(0)x_2 + color(red)(0)x_3 = color(red)(15) => x_1 = 3`
`color(blue)(2)x_1 + color(blue)(-4)x_2 + color(blue)(0)x_3 = color(blue)(-2) => x_2 = 2` (plugging in `3` for `x_1`)
`color(green)(1)x_1 + color(green)(2)x_2 + color(green)(3)x_3 = color(green)(10) => x_3 = 1` (plugging in `3` for `x_1` and `2` for `x_2`)
(This process is known as forward substitution.)
We have `LUx = b`. To take advantage of the easiness of forward substitution, let's view the problem as: `L(y) = b`, where `y = Ux`. Solving `Ly = b` like in the previous example, we easily obtain values for `y`. But how do we get `x`?
It's also just as easy to solve something like `Ux = b`. For example,
`[[color(green)(3), color(green)(2), color(green)(4)],[color(blue)(0), color(blue)(1), color(blue)(2)],[color(red)(0), color(red)(0), color(red)(3)]] [[x_1],[x_2],[x_3]] = [[color(green)(19)],[color(blue)(8)],[color(red)(9)]]`
`color(red)(0)x_1 + color(red)(0)x_2 + color(red)(3)x_3 = color(red)(9) => x_3 = 3`
`color(blue)(0)x_1 + color(blue)(1)x_2 + color(blue)(2)x_3 = color(blue)(8) => x_2 = 2` (plugging in `3` for `x_3`)
`color(green)(3)x_1 + color(green)(2)x_2 + color(green)(4)x_3 = color(green)(19) => x_1 = 1` (plugging in `3` for `x_3` and `2` for `x_2`)
(This process is known as back substitution.)
Notice before, we defined `y = Ux`. We have `y` (from solving `Ly = b`), and we have `U` (from assuming it was possible to split `A = LU`). So like in the previous example, it is possible to solve for `x`.
Let `A = [[2, 1],[6, 5]]`, `b = [[4],[16]]`. Our goal is to find `x_1, x_2` such that `[[2, 1],[6, 5]] [[x_1],[x_2]] = [[4],[16]]`
Let's also say we knew exactly how to split up `A`:
`A = LU = [[1, 0],[3, 2]] [[2, 1],[0, 1]]`
The new problem becomes:
`[[1, 0],[3, 2]] [[2, 1],[0, 1]] [[x_1],[x_2]] = [[4],[16]]`
`(1)`
Let's let
`[[y_1],[y_2]] = [[2, 1],[0, 1]] [[x_1],[x_2]]`
`(2)`
so that
`[[1, 0],[3, 2]] [[y_1],[y_2]] = [[4],[16]]`
`1y_1 + 0y_2 = 4 => y_1 = 4`
`3y_1 + 2y_2 = 16 => y_2 = 2`
`(3)`
Now that we have our values for `y`, let's go back to `(2)`:
`[[4],[2]] = [[2, 1],[0, 1]] [[x_1],[x_2]]`
`0x_1 + 1x_2 = 2 => x_2 = 2`
`2x_1 + 1x_2 = 4 => x_1 = 1`
`(4)`
And we have our values for `x`, as desired.
The math equation for forward/back substitution:
`x_i = (1/a_(i,i))(b_i - sum_(j = 1)^(i-1) a_(i,j)*x_j)`
where `1 le i le n` is the row
To summarize: We assumed `A` could be "split up" into two parts `L` and `U` (i.e., `A = LU`). With that, the problem became `Ax = b => LUx = b`. We took advantage of the fact that solving something like `Lx = b` was easy. So by letting `y = Ux`, we could solve `Ly = b`. Doing that gave us `y`, so we could get `x` by solving `Ux = y`.
This process may look like it requires a lot of steps, but it actually takes less operations than inverting a matrix. Let's look at how many operations it takes to solve `Ly = b`. We'll count operations by counting how many numbers we have to perform operations on.
For the first row, there is `1` number. (By the nature of matrix multiplication, the `0`s don't count as numbers.)
`[[color(red)(5), 0, 0],[2, -4, 0],[1, 2, 3]] [[color(red)(x_1)],[x_2],[x_3]] = [[15],[-2],[10]]`
For the second row, there are `2` numbers.
`[[5, 0, 0],[color(red)(2), color(red)(-4), 0],[1, 2, 3]] [[color(red)(x_1)],[color(red)(x_2)],[x_3]] = [[15],[-2],[10]]`
This continues until the `n^(th)` row where there are `n` numbers.
`[[5, 0, 0],[2, -4, 0],[color(red)(1), color(red)(2), color(red)(3)]] [[color(red)(x_1)],[color(red)(x_2)],[color(red)(x_3)]] = [[15],[-2],[10]]`
So there are `1 + 2 + ... + n ~~ n^2` total numbers* we have to perform operations on.
*Per Big O notation, constants and lower power terms are dropped. It's actually `(n(n+1))/2 = (n^2 + n)/2` numbers.
A picture for the above statement:
`[[***,*,*,*,*],[***,***,*,*,*],[***,***,***,*,*],[***,***,***,***,*],[***,***,***,***,***]]`
Counting the stars, they take up about half of the area of the square. Hence, about `n^2/2` numbers.
This means we have to do about `n^2` operations to solve `Ly = b` (forward substitution). Now we have to solve `Ux = y` (back substitution). By similar reasoning, `U` also has `n^2/2` numbers, so it also takes about `n^2` operations. Altogether, the total number of operations to solve `LUx = b` is `n^2 + n^2 = 2n^2.` For simplicity, we can consider it as `n^2` operations.
This is definitely less than the `n^3` operations it took to find `A^-1.`
The story thus far: Finding `A^-1` simply takes too long `(n^3).` We found out that if we could split `A` into two parts, `L` and `U`, it would only take about `n^2` operations to solve for `x`.
Time complexity of forward and back substitution: `n^2`
Assumptions about `A`: invertible
Cholesky Decomposition
Splitting `A` into two different matrices is nice, but we currently don't know exactly how to do so. Fortunately, there's an easier way to split up `A` and still take advantage of forward and back sub. Let's assume that there exists an upper-triangular matrix `R` such that `A = R^TR.` So now, instead of finding two matrices `L` and `U` such that `A = LU,` we only need to find one matrix `R` such that `A = R^TR.` (`R` is called the "Cholesky factor". This process is called "Cholesky decomposition".) Since `R` is upper-triangular, `R^T` will be lower-triangular, so we can still apply the forward and back substitution methods as before.
Note: `T` means matrix transpose.
For example, `A = [[1, 1, 1],[1, 2, 2],[1, 2, 3]]` can be split up into:
`[[1, 1, 1],[1, 2, 2],[1, 2, 3]] = [[1, 0, 0],[1, 1, 0],[1, 1, 1]] [[1, 1, 1],[0, 1, 1],[0, 0, 1]]`
where `R = [[1, 1, 1],[0, 1, 1],[0, 0, 1]]`, and `R^T = [[1, 0, 0],[1, 1, 0],[1, 1, 1]]`
We made a lot of assumptions about `A`, so all of this looks like it'll only work for super specific cases. However, it turns out that most of the useful matrices used in real life can be written as `A = R^TR`. How convenient. (If `A` can be written as `R^TR`, then it is positive definite.)
The task now becomes finding a matrix `R` such that `A = R^TR.` (`A` has to be positive definite for this to work, so we'll assume `A` is positive definite.)
Let `A = [[1, -2, -1],[-2, 8, 8],[-1, 8, 19]]`

So `A = R^TR = [[1, -2, -1],[-2, 8, 8],[-1, 8, 19]] = [[1, 0, 0],[-2, 2, 0],[-1, 3, 3]] [[1, -2, -1],[0, 2, 3],[0, 0, 3]]`
The math equation for Cholesky decomposition:
`r_(i,i) = sqrt(a_(i,i) - sum_(k = 1)^(i-1) r_(k,i)^2)`
`r_(i,j) = (1/r_(i,i))(a_(i,j) - sum_(k = 1)^(i-1) r_(k,i)*r_(k,j))`
where `1 le i le n` is the row and `1 le j le n` is the column
To summarize: Finding two matrices `L` and `U` such that `A = LU` makes solving the problem fast, but an easier approach is to find only one matrix `R` such that `A = R^TR.` By the nature of `R` (being upper-triangular) and `R^T` (being lower-triangular), we can still do forward and back substitution like we did for triangular systems. Doing this allows us to decompose `A` easily and still achieve the `n^2` time of doing forward and back substitution.
Let's see long it takes to find `R`.

For the first column of `R`, we're doing operations on about `n^2/2` numbers in `R^T` (remember lower- and upper-triangular matrices have about `n^2/2` numbers).

For the second column of `R`, we're also doing operations on about `n^2/2` numbers in `R^T`.
This pattern repeats for all `n` columns of `R`. For each column, we're doing operations on about `n^2` numbers. Since there are `n` columns, we're doing operations on about `n*n^2 = n^3` numbers.
So finding the Cholesky factor `R` requires `n^3` operations. Wait. That sounds bad. Inverting a matrix took `n^3` operations and that was considered bad. So if finding `R` takes about as long as it does to find `A^-1`, why bother with Cholesky decomposition at all?
Well, so far, all of this was done to solve `Ax = b`. Just one problem. What if we changed `b`? What if we were trying to solve `Ax = c?` Or `Ax = d?` (All using the same matrix `A`.) If we had to solve multiple problems using the same matrix `A`, we would have to repeatedly do `n^3` operations to find the inverse for each problem. If we instead found the Cholesky decomposition first, we would have `R^T` and `R` stored in the computer ready to use for each problem and only have to do forward and back substitution for each problem. This means for one problem, it will take `n^3` operations. But for future, subsequent problems, it will only take `n^2` operations.
The story thus far: Finding `A^-1` takes too long `(n^3)`. Finding `L` and `U` such that `A = LU` is faster `(n^2)`, but we don't have a way of finding `L` and `U`. Finding `R` such that `A = R^TR` is easier, and potentially just as fast.
Time complexity of Cholesky decomposition: `n^3`
Assumptions about `A`: invertible, positive definite
Banded Matrices
Things get better if `A` has a bunch of `0`s (if `A` has a lot of `0`s, it is called "sparse".) Much like most matrices have a Cholesky factor, most matrices are also large and sparse. A specific type of sparse matrix — a banded matrix — actually allows us to perform Cholesky decomposition faster.
(For those keeping track, all the assumptions we've made about `A` up to this point are that `A` is invertible, `A` is positive definite (can be split into `R^TR`) and banded (sparseness is implied). Again, `A` sounds super specific, but these type of matrices show up a lot apparently.)
This is an example of a banded matrix: (notice the "band" of numbers across the diagonal and the `0`s)
`[[color(red)(2), color(red)(1), 0, 0, 0],[color(red)(1), color(red)(2), color(red)(1), 0, 0],[0, color(red)(1), color(red)(2), color(red)(1), 0],[0, 0, color(red)(1), color(red)(2), color(red)(1)],[0, 0, 0, color(red)(1), color(red)(2)]]`
It has bandwidth `3` (how wide the band is) and semiband `1` (half of the width of the band). In general, a banded matrix has semiband `s` and bandwidth `2s+1`.
It turns out that there's an important result involving banded matrices: if `A` is positive definite and banded with semiband `s`, then its Cholesky factor `R` is also banded with semiband `s`. This is important, because if `A` had a bunch of `0`s, then `R` will have a bunch of `0`s too. These `0`s mean there are fewer operations we have to do to find out what `R` is.
Recall the process for finding `R` if `A` is not banded:

Notice how we have to go through all the rows of `A` to calculate `r_(1,1), r_(1,2), r_(1,3), r_(1,4), r_(1,5)`
Now let's see what happens when `A` is banded:

We only need to go through the first two rows of `A`. Why is that? Let's look at the third row where we solve for the value of `r_(1,3)`. The equation is
`r_(1,3)*r_(1,1) = 0`
Regardless* of what `r_(1,1)` is, `r_(1,3)` has to be `0`. The same holds true for the rest of the rows below. We know those values are going to be `0`, so why bother calculating them?
*`r_(1,1)` will not be `0` because we assumed `A` was positive definite. This means the diagonal of `A` will be positive numbers. Solving for `r_(1,1)*r_(1,1) = #` cannot result in `r_(1,1) = 0`.
Recognizing those `0`s allows us to skip over numbers in each row. That means, in each row, we only have to perform operations on about `2s+1` (defined earlier as the width of the band) numbers. However, each number in that row requires about `s` numbers for the computation*. Therefore, for each row, we have a total of about `s^2` operations. With `n` rows, we have about `ns^2` total operations.
*A visual for the above statement:

There are `n` rows.
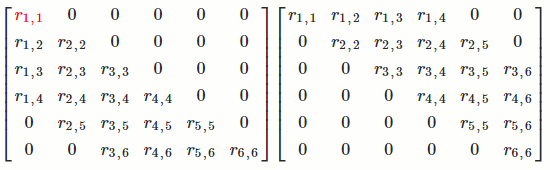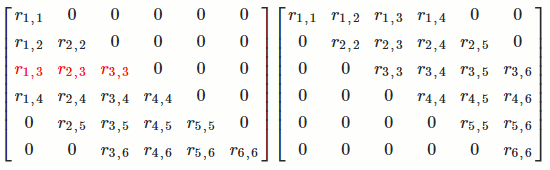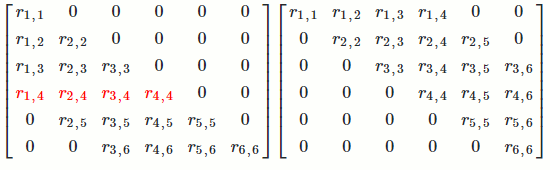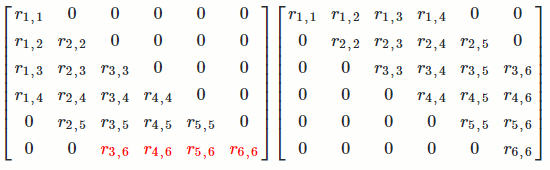
There are `s` numbers in each row.

Each number requires `s` previous numbers for the calculation
So it takes about `ns^2` operations to find `R`. Compared to non-banded matrices, it's faster than the `n^3` operations it took to find `R`. Even better is that because of all the `0`s, performing forward and back substitution is also very fast.
Recall the important fact mentioned earlier: if `A` is positive definite and banded with semiband `s`, then its Cholesky factor `R` is also banded with semiband `s`.
So solving `Rx = y` (back substitution) could look something like this: (remember `R` is upper-triangular)
`[[2, 1, 0, 0, 0],[0, 2, 1, 0, 0],[0, 0, 2, 1, 0],[0, 0, 0, 2, 1],[0, 0, 0, 0, 2]] [[x_1],[x_2],[x_3],[x_4],[x_5]] = [[4],[5],[6],[10],[4]]`
Each row only has about `s` numbers. With `n` rows, there are a total of `ns` numbers. This means back substitution only takes `ns` operations. The same reasoning holds for forward substitution.
All in all, it takes about `ns^2 + 2ns` (or simply, `ns^2`) operations to solve `Ax = b` if we know that `A` is positive definite and banded. That is significantly faster than the `n^3` operations to find `R` and the `n^2` operations to do forward and back substitution.
The story thus far: Cholesky decomposition was a powerful method, but it still took `n^3` operations to find `R`. If we know `A` will be banded (and positive definite), then we can take advantage of its unique structure. The result is that it only takes `ns^2` operations to find `R` and another `ns` operations to do forward and back substitution to solve `Ax = b`.
Time complexity of Cholesky decomposition with banded matrices: `ns^2`
Assumptions about `A`: invertible, positive definite, banded
Iterative Methods: Overview
Cholesky decomposition with banded matrices is nice. But it's only fast when the matrices are banded, which isn't always going to be the case. However, let's consider a different scenario. Let's suppose that we have such a giant matrix, that it takes a day or something to complete. If we stopped our program while it was in the middle of doing Cholesky, we would end up with nothing. It would be nice to be able to stop early and see if the answer we have so far is close to the real answer. That's what iterative methods allow us to do.
Iterative methods start with an initial guess, `x^((0))`. Then they modify the guess to get a new guess, `x^((1)).` This repeats until the guess is (hopefully) close to the real answer.
This probably seems like an unusual way of solving `Ax = b.` We're starting with some random guess and we end up with something that's not exactly the answer. It's also possible that we just keep guessing and never actually get close to the answer. But there are some advantages of using iterative methods. As mentioned before, we can stop early and get some sort of answer. More importantly, iterative methods become fast when matrices are really large and sparse. And they don't need to be banded for this to work.
The story thus far: One way of approaching the `Ax = b` problem is to solve for the exact solution (e.g. by Cholesky decomposition). Another way of approaching the problem is to approximate the solution instead of getting the exact solution. This is sometimes faster and more applicable to general matrices.
Iterative Methods: Jacobi
So we start with an initial guess — either a random guess or an educated one — and get a new guess. How do we get the new guess?
Let's look at `Ax = b`.
`[[a_(1,1), a_(1,2), a_(1,3)],[a_(2,1), a_(2,2), a_(2,3)],[a_(3,1), a_(3,2), a_(3,3)]] [[x_1],[x_2],[x_3]] = [[b_1],[b_2],[b_3]]`
If we wanted to get `x_1`, we would do:
`a_(1,1)*x_1 + a_(1,2)*x_2 + a_(1,3)*x_3 = b_1`
`a_(1,1)*x_1 = b_1 - a_(1,2)*x_2 - a_(1,3)*x_3`
`x_1 = (b_1 - a_(1,2)*x_2 - a_(1,3)*x_3) / a_(1,1)`
By similar reasoning, `x_2` and `x_3` would be:
`x_2 = (b_2 - a_(2,1)*x_1 - a_(2,3)*x_3) / a_(2,2)`
`x_3 = (b_3 - a_(3,1)*x_1 - a_(3,2)*x_2) / a_(3,3)`
Generalizing this, we could say that to get `x_i`, we would do:
`x_i = (b_i - sum_(j != i) a_(i,j)*x_j) / a_(i,i)`
This is the equation to get the exact answer. Since we're working with guesses and not exact answers, we need to modify this equation slightly:
`x_i^((k+1)) = (b_i - sum_(j != i) a_(i,j)*x_j^((k))) / a_(i,i)`
On the `k^(th)` iteration, we have our `k^(th)` guess. We get our next guess (the `k+1^(st)` guess) by plugging in our `k^(th)` guess into that equation.
This is Jacobi's method. In equation form. This is Jacobi in matrix form:
`x^((k+1)) = D^(-1)((D-A)x^((k)) + b)`
where `D` is the matrix containing the diagonal of `A`
`D = [[a_(1,1), 0, ..., 0],[0, a_(2,2), 0, vdots],[vdots, 0, ddots, 0],[0, ..., 0, a_(n,n)]]`
A rough idea of why the equation form is equivalent to the matrix form:
`D^(-1)` is equivalent to taking each entry of `A` and "flipping it" `(1/a_(i,i))`
`D-A` is getting `A` and subtracting off the diagonals `a_(i,i)` so that they are all `0`, i.e., we're dealing with all `a_(i,j)` where `i != j` `(sum_(j != i) a_(i,j)*x_j^((k)))`
How long does it take? Let's first look at how it performs on a full matrix.
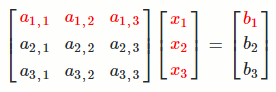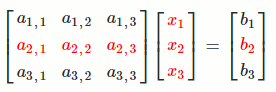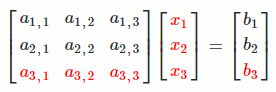
There are `n` rows. For each row, we have to multiply and add `n` numbers. So there are `n^2` operations in total.
Doesn't seem to be too great. But what about if `A` was sparse? (with about `s` nonzero numbers per row)
`[[0, a_(1,2), 0],[a_(2,1), 0, 0],[0, 0, a_(3,3)]] [[x_1],[x_2],[x_3]] = [[b_1],[b_2],[b_3]]`
Now, there are only `s` elements per row. So we only need to do `ns` operations in total. Recall that Cholesky decomposition on a banded matrix also took roughly `ns` operations (`ns^2` operations). But it was only that fast when the matrix was banded. Here, with iterative methods, we achieved `ns` time without needing the matrix to be banded.
Iterative Methods: Gauss-Seidel
The Gauss-Seidel method is pretty similar to the Jacobi method, but it is slightly smarter. Recall the equation for Jacobi:
`x_i^((k+1)) = (b_i - sum_(j != i) a_(i,j)*x_j^((k))) / a_(i,i)`
Another way to write this is:
`x_i^((k+1)) = (b_i - sum_(j lt i) a_(i,j)*x_j^((k)) - sum_(j > i) a_(i,j)*x_j^((k))) / a_(i,i)`
because `j != i` is the same as all the numbers less than `i` (`j lt i`) and all the numbers greater than `i` (`j > i`)
Notice the summation with `j lt i`. That sum is going through all the values for which we have already made guesses. (The whole equation is giving us the new guess for the `i^(th)` number on the `k+1^(st)` iteration. So surely, we had to have made guesses for all the numbers before `i` on the `k+1^(st)` iteration right?) So instead of using an old guess, why not use the new guesses we just recently obtained?
`x_i^((k+1)) = (b_i - sum_(j lt i) a_(i,j)*x_j^((k+1)) - sum_(j > i) a_(i,j)*x_j^((k))) / a_(i,i)`
This is the Gauss-Seidel method. And in matrix form:
`x^((k+1)) = D^(-1)(b + Ex^((k+1)) + Fx^((k)))`
where `E` is the negative of the lower-triangular part of `A` and `F` is the negative upper-triangular part of `A`.
`E = [[-a_(1,1), 0, ..., 0], [-a_(2,1), -a_(2,2), 0, vdots], [vdots, vdots, ddots, 0], [-a_(n,n), ..., ..., -a_(n,n)]]`
`F = [[-a_(1,1), -a_(1,2), ..., -a_(1,n)], [0, -a_(2,2), ..., vdots], [vdots, 0, ddots, vdots], [0, ..., 0, -a_(n,n)]]`
The Gauss-Seidel method should take about the same time as Jacobi's method since they are pretty much almost doing the same thing.
The story thus far: Two iterative methods that approximate the solution to `Ax = b` are Jacobi's method and the Gauss-Seidel method. Both of these start with an initial random guess and generate new guesses based on our old guesses.
Time complexity of Jacobi/Gauss-Seidel: `n^2` for full matrices, `n` for sparse matrices (`ns` if the sparseness depends on the size of the matrix)
Assumptions about `A`: invertible
Vector Norms
Since we're getting approximate answers, it's important to know how close our answer `x^((k))` is to the real answer `x`. Because `x^((k))` and `x` are vectors, we need to define a notion of distance between vectors.
Vector norms are used to measure lengths of vectors. `norm(x)` is the length of `x`. One example of a norm is the "`2`-norm" which is:
`norm(x)_2 = sqrt(x_1^2 + x_2^2 + ... + x_n^2)`
With this notion of length, we can come up with the notion of distance between two vectors:
`norm(x-y)_2 = sqrt((x_1-y_1)^2 + ... + (x_n-y_n)^2)`
Informally, that is saying, "how far apart are `x` and `y`? Those familiar with the distance formula might see some similarities.
Going back to our problem at hand, we want to know how far apart our answer `x^((k))` is to the real answer `x`. Now that we have a way of measuring distance between two vectors, we can represent that as:
`norm(x^((k)) - x)`
Another type of norm is the `1`-norm:
`norm(x)_1 = abs(x_1) + abs(x_2) + ... + abs(x_n)`
Convergence of Iterative Methods
Iterative methods (at least Jacobi and Gauss-Seidel anyway) can be summarized by the notion of "additive splitting". That is, we can rewrite `A` as `A = M - N` where `M` and `N` are two matrices (and `M` is invertible).
The problem then becomes:
`Ax = b`
`=> (M-N)x = b`
`=> Mx - Nx = b`
`=> Mx = Nx + b`
`=> x = M^(-1)(Nx + b)`
How does this relate to iterative methods? Well, that equation says: if we plug in `x` on the right and do some operations to it, we get back `x`. If we plug in `x` on one side, and get it back on the other side, then we've found our answer. That describes exactly what we're doing with iterative methods.
So `x^((k+1)) = M^(-1)(Nx^((k)) + b)` is the general formula for iterative methods. How do Jacobi and Gauss-Seidel fit into this formula? (Compare to the matrix form of each method mentioned earlier)
For Jacobi, let `M = D` and `N = (D-A)`
`x^((k+1)) = D^(-1)((D-A)x^((k)) + b)`
For Gauss-Seidel, let `M = D-E` and `N = F`
`x^((k+1)) = (D-E)^(-1)(Fx^((k)) + b)`
`(D-E)x^((k+1)) = Fx^((k)) + b`
`Dx^((k+1)) - Ex^((k+1)) = Fx^((k)) + b`
`Dx^((k+1)) = Ex^((k+1)) + Fx^((k)) + b`
`x^((k+1)) = D^(-1)(b + Ex^((k+1)) + Fx^((k)))`
Recall that `D` is the diagonal of `A`, `E` is the negative of the lower-triangular part of `A`, and `F` is the negative of the upper-triangular part of `A`.
Now that we've established that `Mx^((k+1)) = Nx^((k)) + b` really is the general formula for iterative methods, we can talk about looking at when (possibly if) iterative methods will give us an answer (i.e., converge).
If `Mx^((k+1)) = Nx^((k)) + b` is the equation we're using to approximate the solution and `Mx = Nx + b` is what we're trying to achieve, then subtracting them gives us how far away we are from the actual solution.
`Mx^((k+1)) = Nx^((k)) + b`
`-(Mx = Nx + b)`
`Mx^((k+1)) - Mx = Nx^((k)) - Nx`
`M(x^((k+1)) - x) = N(x^((k)) - x)`
Let's let `e^((k)) = x^((k)) - x` be how far away we are from the actual solution at the `k^(th)` step. That means `e^((k+1)) = x^((k+1)) - x` is how far away we are from the actual solution at the `k+1^(st)` step. With that, we have
`Me^((k+1)) = Ne^((k))`
`e^((k+1)) = (M^(-1)N)e^((k))`
Keeping in mind that `e` represents how far away we are from the actual solution (and that iterative methods don't always work), if we are to actually get a solution using iterative methods, then we need `norm(e^((k+1)))` to get closer and closer to `0` as `k` keeps increasing (The more we guess, the closer we get to the answer).
Let's let `G = M^(-1)N`. Then `e^((k+1)) = Ge^((k))`. We could recursively apply that formula to get:
`e^((k+1)) = G(Ge^(k-1)) = G(G(Ge^(k-2))) = ...`
`e^((k+1)) = G^(k+1)e^((0))`
`G^(k+1)` is `M^(-1)N` multiplied by itself `k+1` times and `e^((0))` is the distance away from our initial guess to the actual answer. If we want `e^((k+1))` to go to `0`, then `G^(k+1)` has to go to `0` and/or `e^((0))` has to go to `0`. We don't really have control over how far our initial guess is away from the actual answer so the only choice left is to hope that multiplying `G = M^(-1)N` a bunch of times results in it going to `0` (kind of like how multiplying `0.1` a bunch of times makes it closer to `0`).
There's a way to tell if multiplying `G` a bunch of times will make it go to `0` and it involves looking at the eigenvectors and eigenvalues of `G`.
`v_i` is an eigenvector of `G` if `Gv_i = lambda_i v_i` for some number `lambda_i`, which is then the eigenvalue of `G`.
Example:
`[[3, 2],[3, -2]] [[2],[1]] = [[8],[4]]`
`4[[2],[1]] = [[8],[4]]`
`=> [[3, 2],[3, -2]] = 4[[2],[1]]`
`v = [[2],[1]]` is the eigenvector and `lambda = 4` is the eigenvalue
Let's write* `e^((0))` in terms of the eigenvectors of `G`:
`e^((0)) = c_1v_1 + ... + c_nv_n`
Then multiply it by `G`:
`Ge^((0)) = c_1Gv_1 + ... + c_nGv_n`
Remember that `Gv_i = lambda_i v_i`:
`Ge^((0)) = c_1lambda_1v_1 + ... + c_nlambda_nv_n`
Generalizing this for `G^(k+1)`:
`G^(k+1)e^((0)) = c_1lambda_1^(k+1)v_1 + ... + c_nlambda_n^(k+1)v_n`
Now we're back to where we were before introducing all the eigen-stuff: we wanted to know if and how `e^((k+1)) = G^(k+1)e^((0))` would go to `0`. In this equation, that happens if `abs(lambda_i) lt 1` for all `i`, i.e., all the (aboslute values of the) eigenvalues of `G` are smaller than `1`. (Again, multiplying `0.1` a bunch of times makes it go to `0`).
*This is possible because `G` is invertible. `G` being an invertible (`n xx n`) matrix leads to the fact that any vector with `n` values can be written in terms of the eigenvectors of `G`. In math-speak: `{v_1, ..., v_n}` span `R^n`.
To summarize: Iterative methods don't always work. Sometimes, making more guesses causes our guess to go farther and farther away from the actual answer. We are approximating after all. It would be nice to know ahead of time if we are going to get close to our answer (if the iterative method will converge). It turns out that by looking at eigenvalues, we can determine if we will get close to our solution or not.
There's a term for this concept: spectral radius. The spectral radius, denoted by `rho(G)` is:
`rho(G) = max_i abs(lambda_i)`
In words, the spectral radius of a matrix is the largest eigenvalue of that matrix. Relating this back to the conclusion we got earlier, if the spectral radius of a matrix is less than `1`, then `G^(k)e^((0)) = e^((k+1))` will go to `0` (the distance from our guess to the actual answer will get closer to `0`; the iterative method will converge). We only need to look at the maximum eigenvalue - as opposed to all the eigenvalues - because if the maximum is less than `1`, then all the eigenvalues will be less than `1`.
What's remarkable about this fact is that this is true no matter what our initial guess is.
So we have a way of determining if the iterative method will converge. Just calculate all the eigenvalues of `G` and see if the largest eigenvalue is less than `1`. Well, it turns out that finding eigenvalues of a matrix is a slow process, so that's not going to help us much.
There's an easier criterion for determining the spectral radius: for any matrix `G = M^(-1)N` with `0`s along the diagonal (`g_(i,i) = 0`), let `R_i = sum_(j != i) abs(g_(i,j))` (the sum of the numbers in each row). If `R_i lt 1` for all `i`, then `rho(G) le max_i R_i lt 1` (Gershgorin Theorem).
Does Jacobi converge for:
`A = [[3, -1, 0, 0, 0],[-1, 3, -1, 0, 0],[0, -1, 3, -1, 0],[0, 0, -1, 3, -1],[0, 0, 0, -1, 3]]`?
Letting `M = D`, `N = D-A`, `G = M^(-1)N` we have:
`M = [[3, 0, 0, 0, 0],[0, 3, 0, 0, 0],[0, 0, 3, 0, 0],[0, 0, 0, 3, 0],[0, 0, 0, 0, 3]]`
`N = [[0, 1, 0, 0, 0],[1, 0, 1, 0, 0],[0, 1, 0, 1, 0],[0, 0, 1, 0, 1],[0, 0, 0, 1, 0]]`
`G = [[0, 1/3, 0, 0, 0],[1/3, 0, 1/3, 0, 0],[0, 1/3, 0, 1/3, 0],[0, 0, 1/3, 0, 1/3],[0, 0, 0, 1/3, 0]]`
To know if Jacobi will converge, we need to know if the spectral radius of `A` is less than `1`. We can find that out easily by taking each row sum and looking at the max (Gershgorin Theorem).
`R_1 = R_5 = 1/3`
`R_2 = R_3 = R_4 = 2/3`
Since `2/3` is the max row sum, `rho(A) le 2/3`. Since `rho(A) lt 1`, Jacobi will converge no matter what guess we choose as our initial guess.
Now we know when our iterative methods will converge. In addition, we can also look at how many steps it will take to converge.
Let's look at `e^((k+1))` and `e^((k))`, both of which we defined as `e^((k+1)) = G^(k+1)e^((0))` and `e^((k)) = G^(k)e^((0))`. Remember that these can be written in terms of the eigenvectors of `G` (which are `{v_1, ..., v_n}`) since they span `R^n`.
`e^((k+1)) = c_1lambda_1^(k+1)v_1 + ... + c_nlambda_n^(k+1)v_n`
`e^((k)) = c_1lambda_1^(k)v_1 + ... + c_nlambda_n^(k)v_n`
Let's look at those two in terms of the largest eigenvalue `lambda_i`:
`e^((k+1)) ~~ c_ilambda_i^(k+1)v_i`
`e^((k)) ~~ c_ilambda_i^(k)v_i`
`norm(e^((k+1))) ~~ abs(c_i)*abs(lambda_i^(k+1))*norm(v_i)`
`norm(e^((k))) ~~ abs(c_i)*abs(lambda_i^(k))*norm(v_i)`
Dividing those last two equations results in everything canceling out except for `abs(lambda_i)`.
`norm(e^((k+1)))/norm(e^((k))) ~~ abs(lambda_i)`
Well, `abs(lambda_i)` is the spectral radius. Also, since `norm(e^((k+1)))` and `norm(e^((k)))` differed by `k+1 - k = 1` eigenvalue, `norm(e^((k)))/norm(e^((0)))` differ by `k - 0 = k` eigenvalues.
`norm(e^((k)))/norm(e^((0))) ~~ (rho(G))^k`
This tells us that if the spectral radius is small, then the iterative method will converge fairly quickly. If the spectral radius is big — but still less than `1` — it won't converge as quickly (`0.1^100` goes to `0` faster than `0.9^100` does). Knowing the spectral radius lets us determine for how many iterations we should let our iterative method run.
The story thus far: Iterative methods can be written in matrix form as `x = (M^(-1)N)x + b`. From that equation, we derived the equation representing how far away our current guess is to the real answer: `e^((k+1)) = (M^(-1)N)e^((k))`. If `e^((k+1))` goes to `0` as we keep guessing, then that means we're getting closer to the real answer. One way to find out if `e^((k+1))` will go to `0` is to look at the spectral radius of `G = M^(-1)N`. If it is less than `1`, then `e^((k+1))` will eventually go to `0`. One way to find out if the spectral radius is less than `1` is to look at each row sum of `G` and see if the maximum row sum is less than `1`.
Matrix Norms
Matrix norms allow us to measure the "length" of a matrix, much like vector norms measure the "length" of a vector.
One type of matrix norm is the Frobenius norm:
`norm(A)_F = sqrt(sum_(i,j) abs(A_(i,j))^2)`
The Frobenius norm basically adds up all the squares of each element. In this way, a matrix is "small" if all the elements are small. It takes `n^2` operations to compute the Frobenius norm (there are `n^2` numbers in a matrix).
Another way to think about the size of a matrix is to think about how much `A` changes `x` when we do `Ax`. If `x` is a vector of size `1` and then multiplying it by `A` results in a vector of size `100`, then `A` was a big matrix. This leads to another type of norm known as an induced or operator norm:
`norm(A)_p = max_(x != 0) norm(Ax)_p/norm(x)_p`
where `1 le p le oo`
These norms are usually more useful than the Frobenius norm, but they take longer to compute (`n^3`). (However, a (relatively) fast way to estimate `norm(A)_p` is to take a bunch of random vectors `x` and compute `norm(Ax)_p/norm(x)_p`. Whichever answer is largest, will be approximately equal to `norm(A)_p`).
`norm(A)_1` is the largest `1`-norm of the columns of `A`: `(max_j sum_i abs(a_(i,j)))`
`norm(A)_oo` is the largest `1`-norm of the rows of `A`: `(max_i sum_j abs(a_(i,j)))`
One useful result that will be used is `norm(Ax)_p le norm(A)_pnorm(x)_p`.
From this point on, matrix norms without a subscript are assumed to be the induced norm.
Condition Numbers
And now, back to our regularly scheduled programming: solving `Ax = b`. Except with a few changes (pun prematurely intended).
In real life, `b` is usually obtained by some measurement. In other words, `b` is a vector that contains measured quantities. As a result, there is the possibility that we have measurement error. For example, you might record something as `5.25` miles when it is really `5.250432` miles. So we really don't have `b`; we have `hat(b)` where:
`hat(b) = b + deltab`
where `deltab` is how much we are off by from `b`
This changes the problem quite a bit. Instead of `Ax = b`, we now have `Ax = b + deltab`. This is a problem because if we don't know `b` exactly, then we won't get `x` exactly. This means that the answer we get is actually `hat x` where:
`hat(x) = x + deltax`
where `deltax` is how much we are off by from `x`
So the real* problem we are trying to solve is:
`A(x + deltax) = b + deltab`
*Right now, we're assuming we know `A` perfectly.
With all these errors, the question isn't how to find `x` anymore. What's more important is knowing if the error in `b` greatly affects the error in our answer.
The error in `b` can be measured by `norm(deltab)/norm(b)` (the size of the error in `b` relative to `b`) and the error in `x` can be measured by `norm(deltax)/norm(x)` (the size of the error in `x` relative to `x`). What we hope is that if `norm(deltab)/norm(b)` is small, then `norm(deltax)/norm(x)` is also small.
We could derive a bound for `norm(deltax)/norm(x)`. Looking back at the "real" problem:
`A(x + deltax) = b + deltab`
`Ax + Adeltax = b + deltab`
Here, `Ax = b`
`Adeltax = deltab`
`deltax = A^(-1)deltab`
`norm(deltax) = norm(A^(-1)deltab)`
Using the useful result from the previous section:
`norm(deltax) le norm(A^(-1))*norm(deltab)`
`(1)`
To get `1/norm(x)` we look at `Ax = b`:
`norm(b) = norm(Ax)`
`norm(b) le norm(A)*norm(x)`
`1/norm(x) le norm(A)1/norm(b)`
`(2)`
Multiplying `(1)` and `(2)`, we get:
`norm(deltax)/norm(x) le norm(A)*norm(A^(-1))norm(deltab)/norm(b)`
`norm(A)*norm(A^(-1))` is called the condition number of `A`, denoted by `kappa(A)`
`kappa(A) = norm(A)*norm(A^-1)`
So our equation becomes:
`norm(deltax)/norm(x) le kappa(A)norm(deltab)/norm(b)`
The condition number is really important: if it is small, then a small error in `b`, will lead to a small error in `x`. In this case, `A` is "well conditioned". If the condition number is large, then even if the error in `b` is small, the error in `x` could still be large. In this case, `A` is "ill conditioned".
This is an example of a well conditioned system:
`[[1, 2],[3, 4]][[x_1],[x_2]] = [[b_1],[b_2]]`
`x_1 + 2x_2 = b_1`
`3x_1 + 4x_2 = b_2`
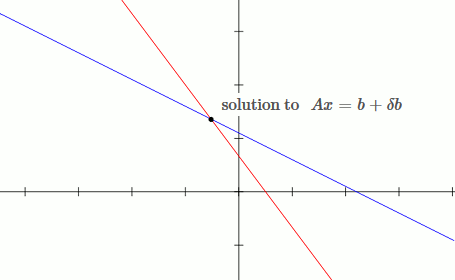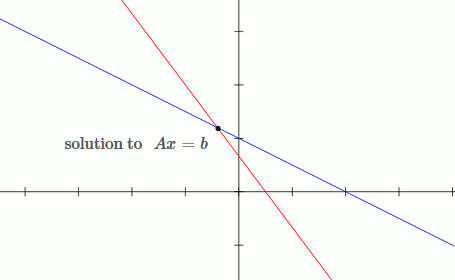
Notice that by moving the blue line up slightly (adding `deltab` to `b`), the solution only changes slightly.
This is an example of an ill conditioned system:
`[[1, 2],[3, 5.6]][[x_1],[x_2]] = [[b_1],[b_2]]`
`x_1 + 2x_2 = b_1`
`3x_1 + 5.6x_2 = b_2`
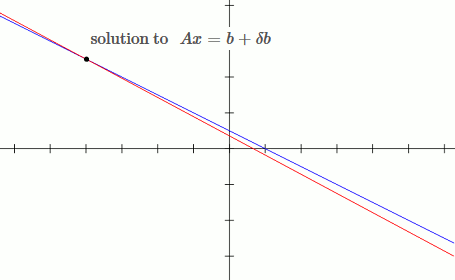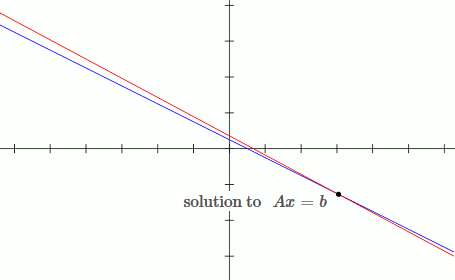
Notice that by moving the blue line up slightly (adding `deltab` to `b`), the solution changes drastically.
Note that the system was ill conditioned because the lines were almost parallel to each other. In linear algebra terms, the columns of `A` were almost linearly dependent. In linear algebra, that also means that `A` is almost not invertible. So the condition number is a way of measuring how close `A` is to not being invertible.
Here's an example of an ill conditioned system with numbers:
Consider `A = [[1000, 999],[999, 998]]`, `b = [[1999],[1997]]`
Solving for `x`, we get `x = [[1],[1]]`
`(1000*1 + 999*1 = 1999` and `999*1 + 998*1 = 1997)`
Now, let's perturb `b` by a very small amount, say `[[-0.01],[0.01]]`, so that `b = [[1998.99],[1997.01]]`
Solving for `x`, we get `x = [[20.97],[-18.99]]`
`(1000*20.97 + 999*-18.99 = 1998.99` and `999*20.97 + 998*-18.99 = 1997.01)`
So we have `kappa(A) = norm(A)*norm(A^(-1))`. Let's look at `norm(A)`.
`norm(A) = max_(x != 0) norm(Ax)/norm(x)`
This is like saying that we're looking for a vector `x`, such that when it is multiplied by `A`, the result is the largest vector out of all the choices we could've picked for `x`. (There are many choices as to what `x` could be. Different choices of `x` will give us different results of `Ax`. But there is one `x` that will give us the largest `Ax`. That is the `x` we're looking for here.)
This introduces the "maximum magnification of `A`":
`norm(A) = max_(x != 0) norm(Ax)/norm(x) = text(maxmag)(A)`
Now let's look at `norm(A^(-1))`:
`norm(A^(-1)) = max_(x != 0) norm(A^(-1)x)/norm(x)`
Let's let `y = A^(-1)x`
`norm(A^(-1)) = max_(y != 0) norm(y)/norm(Ay)`
Thinking back to fractions, if we want to make `a/b` a big number, then we pick `a` to be big `(10000/3)`. If we want to make `b/a` a really big number, then we pick `a` to be small `(3/.00001)`. The idea of big and small and flipping the order of the fractions leads to the next result:
`norm(A^(-1)) = max_(y != 0) norm(y)/norm(Ay) = (min_(y != 0) norm(Ay)/norm(y))^(-1)`
This is like saying that we're looking for a vector `y`, such that when it is multiplied by `A`, the result is the smallest vector out of all the choices we could've picked for `y`. (There are many choices as to what `y` could be. Different choices of `y` will give us different results of `Ay`. But there is one `y` that will give us the smallest `Ay`. That is the `y` we're looking for here.)
This introduces the "minimum magnification of `A`":
`norm(A^(-1)) = (min_(x != 0) norm(Ax)/norm(x))^(-1) = (text(minmag)(A))^(-1)`
Combining these two magnifications, we have:
`kappa(A) = norm(A)norm(A^(-1)) = (text(maxmag)(A))/(text(minmag)(A))`
So we can calculate the condition number by "the largest we can stretch a vector" divided by "the smallest we can stretch a vector". It turns out that if we look at this in terms of the `2`-norm*, we get:
`kappa_2(A) = norm(A)_2norm(A^(-1))_2 = (text(maximum eigenvalue of )A)/(text(minimum eigenvalue of )A)`
*It also turns out that we can only say "eigenvalue" when dealing with the `2`-norm.
The notion of "stretching" a vector is related to eigenvalues.
`[[3, 2], [3, -2]] [[2],[1]] = 4[[2],[1]]`
`4` is an eigenvalue of `[[3, 2], [3, -2]]` and it is stretching the vector `[[2],[1]]` to be `4` times bigger.
Another way in which the condition number is an indicator of how invertible a matrix is:
If `A` is not (or close to not being) invertible, then there exists a `0` (or some really small number close to `0`) eigenvalue. Getting the largest eigenvalue of `A` divided by `0` (or some really small number close to `0`) results in `oo` (or a really large number close to `oo`). Thus, the condition number tells us how close a matrix is to being invertible. If the condition number is small, then it is invertible (and the smaller the condition number, the easier it is to invert). If the condition number is `oo`, then it is not invertible (and the larger the condition number, the harder it is to invert).
This gives an alternate interpretation of the condition number, but it really isn't too useful. As mentioned before, calculating eigenvalues is a slow process. However, we can provide an estimate for the condition number.
It turns out that the condition number of a matrix `A` is always bigger than the norm of any column of `A` divided by the norm of any other column of `A`:
`kappa_p(A) >= norm(a_i)_p/norm(a_j)_p`
This gives us a lower bound as to what the condition number could be.
The story thus far: When it comes to solving `Ax = b`, we actually never know `b` perfectly. Because `b` is obtained from collecting measurements, `b` is subject to measurement error. Therefore, we're actually trying to solve `Ax = b + deltab` where `deltab` is the error. We could still solve for `x`, but it will be for `Ax = b + deltab`, not `Ax = b`. So we hope that the answer we get is close enough to the true answer to be useful. The condition number of `A` determines whether `deltab` is an issue or if it's small enough to not affect the problem.
Perturbing `A`
In the previous section, we assumed that we knew `A` perfectly. Like `b`, `A` is also obtained from measurements, so it is also possible to have measurement error in `A`. Now we look at not knowing `A` perfectly but knowing `b` perfectly.
`(A + deltaA)x = b`
This is a harder problem than `Ax = b + deltab`. In that problem, `A` was assumed to be invertible, which made it possible to solve the problem. Here, adding some error to `A` might change it enough so that it is no longer invertible.
How can we avoid that situation? It turns out that if `A` is invertible and `norm(deltaA)/norm(A) lt 1/(kappa(A))`, then `A + deltaA` is invertible.
A rough idea of the previous statement:
Adding error `(deltaA)` to `A` changes `A` and its eigenvalues. However, if the error is smaller than the smallest eigenvalue of `A`, then the error won't change `A` and its eigenvalues too much.
As before, since we don't have a perfect `A`, we don't have a perfect `x`. That means we have `hat(x) = x + deltax`. So the problem is:
`(A + deltaA)hat(x) = b`
`(A + deltaA)(x + deltax) = b`
`Ax + A(deltax) + deltaA(x + deltax) = b`
Here, `Ax = b`
`A(deltax) + deltaA(x + deltax) = 0`
`A(deltax) = -deltaA(x + deltax)`
`deltax = -A^(-1)(deltaA(x + deltax))`
`norm(deltax) = norm(A^(-1)(deltaA(x + deltax)))`
`norm(deltax) le norm(A^(-1))*norm(deltaA(x + deltax))`
`norm(deltax) le norm(A^(-1))*norm(deltaA)*norm(x + deltax)`
Multiplying both sides by `1 = norm(A)/norm(A)`, we get:
`1*norm(deltax) le norm(A^(-1))*norm(deltaA)*norm(x + deltax)norm(A)/norm(A)`
`norm(deltax)/norm(x + deltax) le norm(A^(-1))*norm(A)norm(deltaA)/norm(A)`
`norm(deltax)/norm(x + deltax) le kappa(A)norm(deltaA)/norm(A)`
So the amount of error we get in our solution is bounded by the condition number and the amount of error in `A`.
Example: Let `A = [[1, 1],[1, 1.01]], A^(-1) = [[101, -100],[-100, 100]]`. Assume `norm(deltaA)_1 lt .001`.
Using the facts about `1`-norms from the Matrix Norms section, we get:
`norm(A)_1 = 2.01` and `norm(A^(-1))_1 = 201`
`kappa_1(A) = norm(A)_1*norm(A^(-1))_1 = (2.01)(201) ~~ 400`
`norm(deltax)_1/norm(x + deltax)_1 le kappa_1(A)norm(deltaA)_1/norm(A)_1`
`norm(deltax)_1/norm(x + deltax)_1 le (400)(.001/2.01)`
`norm(deltax)_1/norm(x + deltax)_1 le .2`
This means that if we change `A` by `.1%`, the solution we get could be off from the true solution by `20%`.
The story thus far: Like for `b`, we never know `A` perfectly. (However, we assumed for this section we knew `b` perfectly.) So the problem becomes `(A + deltaA)x = b` where `deltaA` is the error in `A`. Also like for `b`, the condition number of `A` determines whether `deltaA` makes our answer still close enough to the true answer or completely off from the true answer.
Error Estimates
An a priori error estimate is an estimate made about the potential error of our solution before solving for the solution. In other words, we are getting a feel for how accurate our solution will be so that once we do get our solution, we can determine whether it is accurate or not.
This what we've been doing so far.
An a posteriori estimate is the opposite: first we get our solution; then we analyze how accurate it is. That is what we'll do in this section.
In an ideal situation, we would solve `Ax = b` to get `x`. Since `Ax` and `b` are equal to each other, subtracting them should result in `0`. That is, `b-Ax = 0`.
However, we're never going to have an ideal situation, so we would end up with `hat(x) != x`, which means `hat(x)` isn't the true solution. So `Ahat(x)` is not equal to `b`, and subtracting them should result in a number not `0`. That is, `b-Ahat(x) = hat(r)`. `hat(r)` is called the residual.
The residual is a measure of how close `hat(x)` is to being the actual solution.
Now, we can analyze our error in terms of the residual. Let's look again at making a small change to `b`. So `Ax = b + deltab`. First of all:
`Ax = b + deltab`
`-deltab = b - Ax`
`-deltab = hat(r)`
Recall that we defined `hat(x) = x + deltax`. Also, we got this:
`norm(deltax)/norm(x) le kappa(A)norm(deltab)/norm(b)`
We could rewrite this in terms of the residual:
`norm(x - hat(x))/norm(x) le kappa(A) norm(hat(r))/norm(b)`
This equation is saying the same thing as the other equation. But this gives a different interpretation. Instead of bounding our error by looking at the change in `b`, we can bound our error by looking at the residual. This is more helpful because it's not really possible to calculate `deltab` (you can't really know exactly how much measurement error you made; if you did, then there would be almost no point to all of this.) But it is possible to calculate the residual: do `b - Ahat(x)`.
Example: `A = [[1, 1],[1, 1.01]]`, `kappa_1(A) ~~ 400`, `b = [[1],[2]]`.
Let's say we try to solve `Ax = b` and get our solution `hat(x)`.
Now we can check how far `hat(x)` is from the actual solution by getting the residual: `hat(r) = b - Ahat(x)`
Let's say `hat(r) = [[2 xx 10^(-5)],[1 xx 10^(-5)]]`
So what does this say about `x - hat(x)`? I.e., how far off is `hat(x)` from `x`?
From calculating, we get: `norm(hat(r))_1 = 3 xx 10^(-5)` and `norm(b)_1 = 3`
`norm(x - hat(x))/norm(x) le kappa(A) norm(hat(r))/norm(b)`
`norm(x - hat(x))/norm(x) le (400)((3 xx 10^(-5))/3)`
`norm(x - hat(x))/norm(x) le .004`
What's happening here is that we got our solution `hat(x)` and the residual was really small (`.01%`). But after analyzing our error, our solution could be off by as much as `.4%`.
It takes `n^2` time to calculate `hat(r)`.
Floating Point Arithmetic
So far, the only errors that have been mentioned were measurement errors. There is another source of errors, and that is in how a computer stores numbers.
Computers don't store numbers exactly the way in which we type them. It's impossible for some numbers, like `pi` since it has infinitely many digits. Because of storage limitations, computers store only a certain number of digits.
Example: Suppose our computer is computing `(1.52 xx 10^2)(2.72 xx 10^3)` and it only stores `3` digits.
The actual answer is `4.1344 xx 10^5`. But since our computer only stores `3` digits, it's saved as `4.13 xx 10^5`. So how far off are we?
`text(error) = abs(4.13 xx 10^5 - 4.1344 xx 10^5)/abs(4.1344 xx 10^5) ~~ 0.001 = .1%`
This is known as rounding error.
Other types of errors:
Overflow: if a computer only stores up to`10^308` digits, then `10^200*10^200` will be treated as `oo`
Underflow: if a computer only stores down to `10^-308` digits, then `10^(-200)*10^(-200)` will be treated as `0`
We can define what the computer actually stores by `fl(c)`, the float of `c`, where `c` is a number. One way to write this floating point error is:
`fl(c) = c(1 + epsilon)`
That comes from the idea that `fl(c)` is `c` with some error. Mathematically, `fl(c) = c + e` where `e` is the absolute error. The relative error would be `e/c = epsilon => e = cepsilon`. Then `fl(c) = c + e = c + cepsilon = c(1 + epsilon)`.
Let's say we want the computer to multiply two numbers. What the computer would store is `fl(xy)`.
Already, there are some errors before the calculation; the computer can't store `x` and `y` exactly. So it stores `fl(x) = x(1 + epsilon_1)`, call it `hat(x)`, and `fl(y) = y(1 + epsilon_2)`, call it `hat(y)`.
So what we're actually getting is `fl(hat(x)hat(y))`.
`fl(hat(x)hat(y)) = hat(x)hat(y)(1 + epsilon_3)`
`fl(hat(x)hat(y)) = x(1 + epsilon_1)y(1 + epsilon_2)(1 + epsilon_3)`
`fl(hat(x)hat(y)) = xy(1 + epsilon_1)(1 + epsilon_2)(1 + epsilon_3)`
`fl(hat(x)hat(y)) ~~ xy(1 + epsilon_1 + epsilon_2 + epsilon_3)`
Multiplying `(1 + epsilon_1)(1 + epsilon_2)(1 + epsilon_3)` will result in some terms like `epsilon_1*epsilon_2`. A small number multiplied by another small number is going to be a really small number, so we can ignore it because it won't affect anything on a big enough scale to matter.
So in multiplying two numbers, there could've been error in `x`, which is `(1 + epsilon_1)`, error in `y`, which is `(1 + epsilon_2)`, and error in `xy`, which is `(1 + epsilon_3)`. These errors add up.
This could lead to a problem when doing Cholesky decomposition because the `r_(i,j)`s were computed using previously calculated `r_(i,j)`s. The errors gradually get bigger as the errors get carried over into future computations of `r_(i,j)`s.
It's even worse when doing addition/subtraction:
`hat(x) + hat(y) = x(1 + epsilon_1) + y(1 + epsilon_2)`
`= x + xepsilon_1 + y + yepsilon_2`
`= (x+y)(1 + x/(x+y)epsilon_1 + y/(x+y)epsilon_2)`
What if `x + y` was close to `0`? Since, we're dividing by `x + y`, the error could possibly be infinite. This is referred to as "catastrophic error".
Looking at the equation for multiplication, if the errors are small (e.g. each `epsilon_i` is much less than `1`), then the error in the product can be assumed to be small. Looking at the equation for addition, even if the errors were small, if `x` and `y` are large enough, they could affect the sum quite a bit.
With all these errors showing up, we want to know that the solution we get is useful at all. One way of knowing this is by knowing if our calculations are "backward stable". We could do the computations first and then round. Or we could round first and then compute. If the answers from doing these two methods are the same, then the algorithm we're using is backward stable.
Compute first then round: `hat(x) = fl(A^(-1)b)`
Round first then compute: `hat(x) = (A + deltaA)^(-1)(b + deltab)`
The story thus far: Errors show up everywhere in solving `Ax = b`, from using iterative methods to get approximate solutions to using approximate data for `A` and `b` to computer storage limitations. When we get our solution, we want to know that the errors from these sources of errors don't make our solution completely incorrect. Two conditions for being able to trust our solution are: 1) having a small condition number `kappa(A)` and 2) verifying that the algorithm we're using to solve `Ax = b` is backward stable.
Gaussian Elimination
Gaussian elimination is the first method that linear algebra students are taught for solving `Ax = b`. However, with all the errors mentioned before, no one actually ever uses this method. Analyzing Gaussian elimination does produce a significant result though.
The basic idea is to turn the matrix `A` into an upper-triangular matrix in order to do back substitution.
`[[a_(1,1), a_(1,2), a_(1,3), |, b_1],[a_(2,1), a_(2,2), a_(2,3), |, b_2],[a_(3,1), a_(3,2), a_(3,3), |, b_3]] -> [[a_(1,1), a_(1,2), a_(1,3), |, b_1],[0, a'_(2,2), a'_(2,3), |, b'_2],[0, a'_(2,3), a'_(3,3), |, b'_3]] -> [[a_(1,1), a_(1,2), a_(1,3), |, b_1],[0, a'_(2,2), a'_(2,3), |, b'_2],[0, 0, a''_(2,3), |, b''_3]]`
where the `0`s were obtained by multiplying the `1^(st)` row by a number `(a_(2,1)/a_(1,1))` so that `a_(1,1) = a_(2,1)`. Subtracting `a_(2,1)-a_(1,1)` would lead to `0` while `a_(2,2)-a_(1,2)` and `a_(2,3)-a_(1,3)` would be numbers that are not `a_(2,2)` and `a_(2,3)`.
Example: `A = [[2, 1, 1],[2, 2, -1],[4, -1, 6]]`, `b = [[9],[9],[16]]`
`(1)` multiply the `1^(st)` row by `2/2 = 1` and subtract the `2^(nd)` row by the `1^(st)` row
`(1)` `[[color(red)(2), color(red)(1), color(red)(1), |, color(red)(9)],[color(red)(2), color(red)(2), color(red)(-1), |, color(red)(9)],[4, -1, 6, |, 16]] -> [[color(red)(2), color(red)(1), color(red)(1), |, color(red)(9)],[color(red)(0), color(red)(1), color(red)(-2), |, color(red)(0)],[4, -1, 6, |, 16]]`
`(2)` multiply the `1^(st)` row by `4/2 = 2` and subtract the `3^(rd)` row by the `1^(st)` row
`(2)` `[[color(red)(2), color(red)(1), color(red)(1), |, color(red)(9)],[0, 1, -2, |, 0],[color(red)(4), color(red)(-1), color(red)(6), |, color(red)(16)]] -> [[color(red)(2), color(red)(1), color(red)(1), |, color(red)(9)],[0, 1, -2, |, 0],[color(red)(0), color(red)(-3), color(red)(4), |, color(red)(-2)]]`
`(3)` multiply the `2^(nd)` row by `(-3)/1 = -3` and subtract the `3^(rd)` row by the `2^(nd)` row
`(3)` `[[2, 1, 1, |, 9],[0, color(red)(1), color(red)(-2), |, color(red)(0)],[0, color(red)(-3), color(red)(4), |, color(red)(-2)]] -> [[2, 1, 1, |, 9],[0, color(red)(1), color(red)(-2), |, color(red)(0)],[0, color(red)(0), color(red)(-2), |, color(red)(-2)]]`
This is a simple but tedious and time-costly method. To get the first `0` in the `1^(st)` column, we're doing `n` multiplications and `n` subtractions `(1)`. To get the second `0` in the `1^(st)` column, we're also doing `n` multiplications and `n` subtractions `(2)`. And we did this for `2` rows (every row but the `1^(st)`).
Generalizing this for the `1^(st)` column, there are `n-1` rows, each with `n+n = 2n` multiplications and subtractions. So the total is `2n(n-1) ~~ 2n^2` operations.
To get the first (and only) `0` in the `2^(nd)` column, we're doing `n-1` multiplications and `n-1` subtractions `(3)`. And we did this for `1` row (every row but the `1^(st)` and `2^(nd)`).
Generalizing this for the `2^(nd)` column, there are `n-2` rows, each with `n-1 + n-1 = 2(n-1)` multiplications and subtractions. So the total is `2(n-1)(n-2) ~~ 2(n-1)^2` operations.
Generalizing this for all columns, there are `2(n-i)^2 ~~ n^2` operations for the `i^(th)` column where `1 le i le n`. Since there are `n` columns, there are `n^2*n ~~ n^3` operations.
A result that this section will show is that doing Gaussian elimination results in decomposing `A` into two matrices `L` (lower-triangular) and `U` (upper-triangular).
We started with `b` (in the example, `[[9],[9],[16]]`) and turned it into some new vector `y` (in the example, `[[9],[0],[-2]]`). In `0`ing out the `1^(st)` column, `2^(nd)` row, we multiplied `b_1` `(9)` by `m_(2,1) = a_(2,1)/a_(1,1)` `(1 = 2/2)` and subtracted that from `b_2` `(9)`.
`[[b_1],[b_2],[b_3]] = [[y_1],[y_2],[y_3]] = [[b_1],[color(red)(b_2 - m_(2,1)*b_1)],[b_3 - m_(3,1)*b_1 - m_(3,2)*y_2]]`
In `0`ing out the `1^(st)` column, `3^(rd)` row, we multiplied `b_1` by `m_(3,1) = a_(3,1)/a_(1,1)` `(2 = 4/2)` and subtracted that from `b_3` `(-2)`.
`[[b_1],[b_2],[b_3]] = [[y_1],[y_2],[y_3]] = [[b_1],[b_2 - m_(2,1)*b_1],[color(red)(b_3 - m_(3,1)*b_1) - m_(3,2)*y_2]]`
In `0`ing out the second column, we multiplied `y_2` `(0)` by `m_(3,2) = a_(3,2)/a_(1,1)` `(-3)` and subtracted that from `b_3`.
`[[b_1],[b_2],[b_3]] = [[y_1],[y_2],[y_3]] = [[b_1],[b_2 - m_(2,1)*b_1],[color(red)(b_3) - m_(3,1)*b_1 color(red)(- m_(3,2)*y_2)]]`
Since `y_1 = b_1`, we could replace instances of `b_1` with `y_1`:
`[[b_1],[b_2],[b_3]] = [[y_1],[y_2],[y_3]] = [[b_1],[b_2 - m_(2,1)*y_1],[b_3 - m_(3,1)*y_1 - m_(3,2)*y_2]]`
This could be represented mathematically as:
`y_i = b_i - sum_(j = 1)^(i-1) m_(i,j)*y_j`
This is actually the (easier) formula for forward/back substitution. Remember that it was:
`x_i = (1/a_(i,i))(b_i - sum_(j = 1)^(i-1) a_(i,j)*x_j)`
That could actually be written in matrix form when we rearrange `y_i = b_i - sum_(j = 1)^(i-1) m_(i,j)*y_j => b_i = sum_(j = 1)^(i-1) m_(i,j)*y_j + y_i`:
`[[b_1],[b_2],[vdots],[vdots],[b_n]] = [[1, 0, 0, ..., 0], [m_(2,1), 1, 0, ..., vdots], [m_(3,1), m_(3,2), 1, ..., vdots], [vdots, vdots, vdots, ddots, 0], [m_(n,1), m_(n,2), m_(n,3), ..., 1]][[y_1], [y_2], [vdots], [vdots], [y_n]] = [[y_1], [m_(2,1)*y_1 + y_2], [m_(3,1)*y_1 + m_(3,2)*y_2 + y_3], [vdots], [vdots]]`
This means that `b` can be written in terms of `L` and `y`. Namely, `b = Ly`. So if we're using Gaussian elimination to solve `Ax = b`, that is equivalent to solving `Ax = Ly`. But also remember that by doing Gaussian elimination, we transformed the problem from `Ax = b` to `Ux = y`. So:
`Ax = b => Ax = Ly => Ax = LUx`.
That means `A` has to equal `LU`. More formally, any invertible matrix `A` can be decomposed uniquely into `LU` where `L` is a lower-triangular matrix with `1`s along the diagonal and `U` is an upper-triangular matrix. This is very similar to Cholesky decomposition. The benefit is also there: if we have to compute `Ax = b` for multiple `b`, we can decompose `A` into `LU` and reuse them for future use.
Example: Decompose `A = [[2, 1, -1],[-2, 0, 3],[0, 2, 3]]` into `L` and `U`.
We proceed by doing Gaussian elimination.
Multiply the `1^(st)` row by `(-1)` and subtract the `1^(st)` row from the `2^(nd)` row: `color(red)(m_(2,1) = -1)`, `color(red)(u_(2,1)) = -2 - 2*(-1) color(red)(= 0)`, `color(red)(u_(2,2)) = 0 - 1*(-1) color(red)(= 1)`, `color(red)(u_(2,3)) = 3 - (-1)*(-1) color(red)(= 2)`
`[[1, 0, 0],[color(red)(-1), 1, 0], [-, -, 1]][[2, 1, -1],[color(red)(0), color(red)(1), color(red)(2)],[0, 2, 3]]`
Multiply the `1^(st)` row by `(0)` and subtract the `1^(st)` row from the `3^(rd)` row: `color(red)(m_(3,1) = 0)`, `color(red)(u_(3,1)) = 0 - 2*0 color(red)(= 0)`, `color(red)(u_(3,2)) = 2 - 1*0 color(red)(= 2)`, `color(red)(u_(3,3)) = 3 - (-1)*0 color(red)(= 3)`
`[[1, 0, 0],[-1, 1, 0], [color(red)(0), -, 1]][[2, 1, -1],[0, 1, 2],[color(red)(0), color(red)(2), color(red)(3)]]`
Multiply the `2^(nd)` row by `(2)` and subtract the `2^(nd)` row from the `3^(rd)` row: `color(red)(m_(3,2) = 2)`, `color(red)(u_(3,1)) = 0 - 0*2 color(red)(= 0)`, `color(red)(u_(3,2)) = 2 - 1*2 color(red)(= 0)`, `color(red)(u_(3,3)) = 3 - 2*2 color(red)(= -1)`
`[[1, 0, 0],[-1, 1, 0], [0, color(red)(2), 1]][[2, 1, -1],[0, 1, 2],[color(red)(0), color(red)(0), color(red)(-1)]]`
To summarize: Gaussian elimination is the age-old algorithm used to solve `Ax = b`. It involves performing row operations to change `Ax = b` into `Ux = y`. What's going on under the hood is that we're decomposing `A` into two matrices `L` and `U`. Gaussian elimination can be performed on any invertible matrix `A`, so that means any invertible matrix `A` can be decomposed into `LU`. In the Triangular Systems section, we said that we didn't have a way of finding `L` and `U`. Now we do.
Least Squares Problem
Up to this point, `A` has been a square matrix (`n xx n`). However, it is possible for `A` to be an `n xx m` matrix where `n != m`.
`[[a_(1,1), a_(1,2)],[a_(2,1), a_(2,2)],[a_(3,1), a_(3,2)]][[x_1],[x_2]] = [[b_1],[b_2],[b_3]]`
We generally can't solve these problems perfectly, so we instead look at the residual, `hat(r) = b - Ax` and try to make it as small as possible (i.e., make `norm(hat(r))_2` as close to `0` as possible.)
So, to solve the least squares problem, we want to make `norm(hat(r))_2` as small as possible. Well, that's the same as saying, "out of all the possible vectors, choose the one — call it w — that makes `norm(hat(r))_2 = norm(b - Aw)_2` as small as possible."
`min_(w in R^m) norm(b - Aw)_2`
where `R^m` is the set of all vectors with `m` rows
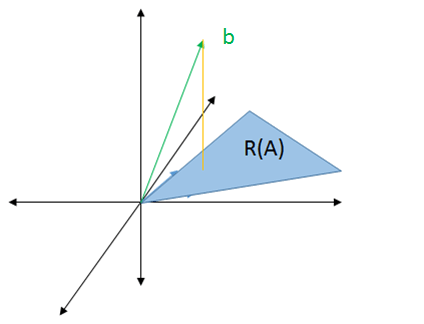
Since we're looking at `b - Aw`, let's instead consider only the vectors produced by doing `Aw`. The vectors that are formed by multiplying `A` with `w` are in the "range" of `A`, denoted `R(A)`.
`min_(y in R(A)) norm(b - y)_2`
Let's look at this visually. We'll start with the case when `A` is a `2xx2` matrix.
The matrix `A` can be represented as two vectors (the columns of `A`)
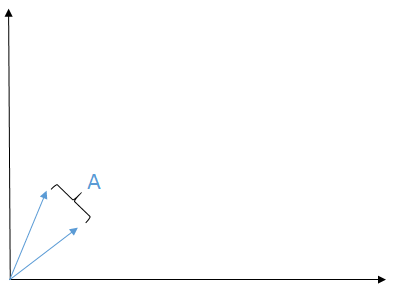
The range of `A`, `R(A)`, is the shaded area in blue between the vectors of `A` (this comes from the fact that the range of `A` is the span of the columns of `A` i.e., the column space of `A`)

If `b` lies in the shaded region, then `Ax = b` (which means we can find an `x` that satisfies that equation.) If `b` doesn't lie in the shaded region, then it is impossible to find an `x` such that `Ax = b`.

In the least squares problem, `A` has more rows than columns, so let's say it is `3xx2`.

So for `Ax = b`, since `A` only has `2` columns, `x` must have `2` rows and `b` must have `3` rows. This means that we must somehow find an `x` in `2` dimensions to reach a `b` in `3` dimensions. This is why we can't solve the least squares problem perfectly, as mentioned at the beginning.
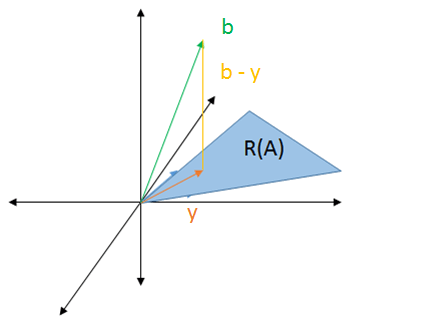
The best we can do is to find the solution in `2` dimensions that is as close as possible to `b` in `3` dimensions. This can be done by dropping a straight line down to the `2` dimension area.
The solution, denoted by `y`, is the vector pointing to where the line drops. That line is a vector representing the difference between `b` and `y`.
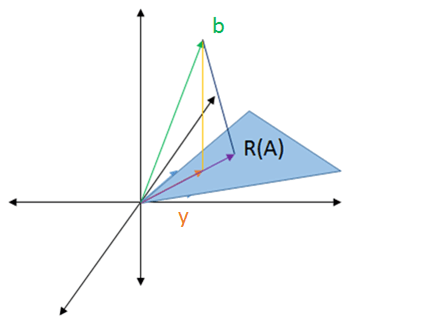
This would be the vector in `2` dimensions with the shortest distance to `b`. We could choose any other vector and it would be farther to `b` than `y`.
That could be seen by looking at right triangles.
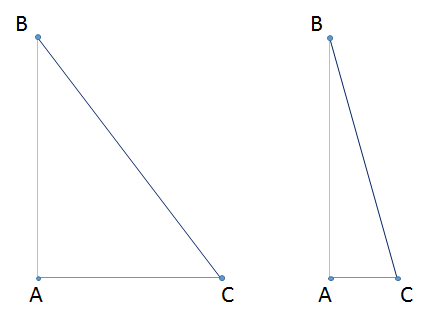
No matter what we choose for point `C`, the distance from point `A` to `B` will always be shorter than the distance from point `B` to `C`.
Going back to the statement before all the visuals, solving the least squares problem means making `norm(b-y)_2` as small as possible. From the visuals, we see that it is as small as possible when we take the vector pointing to the straight line dropped from `b`. The straight line is perpendicular to `R(A)`. More formally:
`min norm(r)_2 = min_(w in R^m) norm(b - Aw)_2` if and only if `b - Aw in R(A)^(bot)`
It turns out that `R(A)^(bot) = N(A^T)`, the null space of `A^T` (i.e., all the vectors `x` such that `A^Tx = 0`). So:
`b - Ax in R(A)^(bot)`
`=> b - Ax in N(A^T)`
`=> A^T(b - Ax) = 0`
`=> A^Tb - A^TAx = 0`
`=> A^TAx = A^Tb`
This leads to the final statement about the least squares problem: `x` solves the least squares problem for `Ax = b` if and only if `(A^TA)x = A^Tb`.
I know I switched between using `w` and `x` throughout this section. At the beginning, we didn't know what `x` was, so we chose some vector `w` to try and make it equal to `x`. At the end, we showed that `w`, when chosen correctly, is the solution we're looking for.
Thanks to Victor and Lewis for their visual explanation, which helped me come up with this.
`QR` Decomposition (by Reflectors)
From `(A^TA)x = A^Tb`, we could theoretically do `x = (A^TA)^(-1)A^Tb`. But then we would be back again at the very beginning of this whole story. Because taking inverses of matrices is bad, we're gonna instead find a more efficient way to solve this problem.
Similar to the Cholesky decomposition, `QR` decomposition breaks `A` into `2` matrices, namely, `Q` and `R`. If `A` is an `n xx m` matrix where `n > m`, then `A = QR` where `Q` is an `n xx n` orthogonal* matrix and `R` is an `n xx m` matrix. Specifically, `R = [[color(blue)(hat(R))],[color(red)(0)]]` where `hat(R)` is an `m xx m` upper triangular matrix.
`[[a_(1,1), a_(1,2), a_(1,3), a_(1,4)],[a_(2,1), a_(2,2), a_(2,3), a_(2,4)],[a_(3,1), a_(3,2), a_(3,3), a_(3,4)],[a_(4,1), a_(4,2), a_(4,3), a_(4,4)],[a_(5,1), a_(5,2), a_(5,3), a_(5,4)]] = [[q_(1,1), q_(1,2), q_(1,3), q_(1,4), q_(1,5)],[q_(2,1), q_(2,2), q_(2,3), q_(2,4), q_(2,5)],[q_(3,1), q_(3,2), q_(3,3), q_(3,4), q_(3,5)],[q_(4,1), q_(4,2), q_(4,3), q_(4,4), q_(4,5)],[q_(5,1), q_(5,2), q_(5,3), q_(5,4), q_(5,5)]] [[color(blue)(r_(1,1)), color(blue)(r_(1,2)), color(blue)(r_(1,3)), color(blue)(r_(1,4))],[color(blue)(0), color(blue)(r_(2,2)), color(blue)(r_(2,3)), color(blue)(r_(2,4))],[color(blue)(0), color(blue)(0), color(blue)(r_(3,3)), color(blue)(r_(3,4))],[color(blue)(0), color(blue)(0), color(blue)(0), color(blue)(r_(4,4))],[color(red)(0), color(red)(0), color(red)(0), color(red)(0)]]`
where `n = 5`, `m = 4`
*orthogonal means `Q^T = Q^(-1)`, which is the same as `Q^TQ = I`
Orthogonal matrices don't change the size of vectors. That means taking a vector `x` and multiplying it with `Q` won't "stretch" or "scale" `x`; it'll just make `x` point in some other direction. Formally, `norm(Qx) = norm(x)`. The same holds for `Q^T`: `norm(Q^Tx) = norm(x)`.
Recall that solving the least squares problem involves minimizing `norm(b - Ax)_2`. Since `Q` preserves length, we can do:
`norm(b - Ax)_2`
`= norm(Q^T(b - Ax))_2`
`= norm(Q^Tb - Q^TAx)_2`
`= norm(Q^Tb - Rx)`
(since `A = QR => Q^(-1)A = R => Q^TA = R` and `Q^(-1) = Q^T`)
`Q^T` is an `n xx n` matrix and `b` is an `n xx 1` vector, so `Q^Tb` will be some `n xx 1` vector. We can say that `Q^Tb = [[color(blue)(hat(c))],[color(red)(d)]]`, where `hat(c)` is an `m xx 1` vector and `d` is an `(n-m) xx 1` vector.
`[[q_(1,1), q_(2,1), q_(3,1), q_(4,1), q_(5,1)],[q_(1,2), q_(2,2), q_(3,2), q_(4,2), q_(5,2)],[q_(1,3), q_(2,3), q_(3,3), q_(4,3), q_(5,3)],[q_(1,4), q_(2,4), q_(3,4), q_(4,4), q_(5,4)],[q_(1,5), q_(2,5), q_(3,5), q_(4,5), q_(5,5)]] [[b_1],[b_2],[b_3],[b_4],[b_5]] = [[color(blue)(hat(c)_1)],[color(blue)(hat(c)_2)],[color(blue)(hat(c)_3)],[color(blue)(hat(c)_4)],[color(red)(d)]]`
`R = [[hat(R)],[0]]`, so `Rx = [[hat(R)x],[0]]`.
Combining these two points, we get:
`norm(Q^Tb - Rx)_2`
`= norm([[hat(c)],[d]] - [[hat(R)x],[0]])_2`
`= norm([[hat(c) - hat(R)x],[d]])_2`
Since the `2`-norm is a sum, we can break it up:
`norm([[hat(c) - hat(R)x],[d]])_2`
`= sqrt(norm(hat(c) - hat(R)x)_2^2 + norm(d)_2^2)`
So from all of that, we get `norm(b - Ax)_2 = sqrt(norm(hat(c) - hat(R)x)_2^2 + norm(d)_2^2)`. We're trying to minimize `norm(b - Ax)`, which is the same as minimizing `sqrt(norm(hat(c) - hat(R)x)_2^2 + norm(d)_2^2)`. That happens when `norm(hat(c) - hat(R)x)_2^2 = 0`. That happens when `hat(R)x = c`. `hat(R)` is `m xx m` and `c` is `m xx 1`, so this problem is solvable using the techniques earlier in the story. `hat(R)` is actually upper triangular, so we can use back sub to solve for `x`. By solving for `x`, we are able to make `norm(c - hat(R)x) = 0`. What we are left with is `sqrt(norm(d)_2^2) = norm(d)_2`. That is the measure of the error in our solution (because we can't solve the least squares problem perfectly).
Example: `A = [[3, -6],[4, -8],[0, 1]]`, `b = [[1],[2],[3]]`, `Q = [[-0.6, 0, 0.8],[-0.8, 0, -0.6],[0, -1, 0]]`, `R = [[-5, 10],[0, -1],[0, 0]]`
First we rewrite the problem using `A = QR`:
`[[-0.6, 0, 0.8],[-0.8, 0, -0.6],[0, -1, 0]] [[-5, 10],[0, -1],[0, 0]]x = [[1],[2],[3]]`
`QRx = b`
Then we can multiply both sides by `Q^T` to get `Rx = Q^Tb`. We have `Q` and `b` so we can solve for `Q^Tb`:
`Q^Tb = [[-0.6, -0.8, 0],[0, 0, -1],[0.8, -0.6, 0]] [[1],[2],[3]] = [[color(blue)(-2.2)],[color(blue)(-3)],[color(red)(-0.4)]] = [[color(blue)(hat(c))],[color(red)(d)]]`
`[[-5, 10],[0, -1],[0, 0]]x = [[color(blue)(-2.2)],[color(blue)(-3)],[color(red)(-0.4)]]`
`Rx = [[color(blue)(hat(c))],[color(red)(d)]]`
We can then do back sub to solve for `x`:
`[[-5, -10],[0, -1]]x = [[-2.2],[-3]]`
`=> x = [[6.44],[3]]`
`d` gives us the residual:
`norm(hat(r)) = norm(d) = norm(-0.4)_2 = 0.4`
So if we're given `A`, how do we find the `Q` and `R`? Notice how the problem went from `Ax = b` to `Rx = Q^Tb`. That means that doing a `QR` decomposition invovles turning `A` into `R`.
`[[color(blue)(a_(1,1)), color(red)(a_(1,2)), a_(1,3), a_(1,4)],[color(blue)(a_(2,1)), color(red)(a_(2,2)), a_(2,3), a_(2,4)],[color(blue)(a_(3,1)), color(red)(a_(3,2)), a_(3,3), a_(3,4)],[color(blue)(a_(4,1)), color(red)(a_(4,2)), a_(4,3), a_(4,4)],[color(blue)(a_(5,1)), color(red)(a_(5,2)), a_(5,3), a_(5,4)]] -> [[color(blue)(r_(1,1)), color(red)(r_(1,2)), r_(1,3), r_(1,4)],[color(blue)(0), color(red)(r_(2,2)), r_(2,3), r_(2,4)],[color(blue)(0), color(red)(0), r_(3,3), r_(3,4)],[color(blue)(0), color(red)(0), 0, r_(4,4)],[color(blue)(0), color(red)(0), 0, 0]]`
That is, we want to find a `Q` such that `Q^TA = R` (since `A = QR`). We want to find some matrix that turns the first column of `A` into a vector with only `1` number in the first entry and so on.
`[[color(blue)(a_(1,1))], [color(blue)(a_(2,1))], [color(blue)(a_(3,1))], [color(blue)(a_(4,1))], [color(blue)(a_(5,1))]] -> [[color(blue)(r_(1,1))], [color(blue)(0)], [color(blue)(0)], [color(blue)(0)], [color(blue)(0)]]` `[[color(red)(a_(1,2))],[color(red)(a_(2,2))],[color(red)(a_(3,2))],[color(red)(a_(4,2))],[color(red)(a_(5,2))]] -> [[color(red)(r_(1,2))],[color(red)(r_(2,2))],[color(red)(0)],[color(red)(0)],[color(red)(0)]]`
It turns out that, for a vector `x`, there exists an orthogonal matrix `Q` such that `Q^Tx = [[-tau],[0], [vdots], [0]]`. So for each column of `A`, we can find a `Q_i` to do what we want.
`Q_1^TA: [[a_(1,1), a_(1,2), a_(1,3), a_(1,4)],[a_(2,1), a_(2,2), a_(2,3), a_(2,4)],[a_(3,1), a_(3,2), a_(3,3), a_(3,4)],[a_(4,1), a_(4,2), a_(4,3), a_(4,4)],[a_(5,1), a_(5,2), a_(5,3), a_(5,4)]] -> [[-tau_1, alpha_(1,2), alpha_(1,3), alpha_(1,4)], [0, alpha_(2,2), alpha_(2,3), alpha_(2,4)], [0, alpha_(3,2), alpha_(3,3), alpha_(3,4)], [0, alpha_(4,2), alpha_(4,3), alpha_(4,4)], [0, alpha_(5,2), alpha_(5,3), alpha_(5,4)]]`
`Q_2^TQ_1^TA: [[a_(1,1), a_(1,2), a_(1,3), a_(1,4)],[a_(2,1), a_(2,2), a_(2,3), a_(2,4)],[a_(3,1), a_(3,2), a_(3,3), a_(3,4)],[a_(4,1), a_(4,2), a_(4,3), a_(4,4)],[a_(5,1), a_(5,2), a_(5,3), a_(5,4)]] -> [[-tau_1,alpha_(1,2), alpha_(1,3), alpha_(1,4)], [0, -tau_2, beta_(2,3), beta_(2,4)], [0, 0, beta_(3,3), beta_(3,4)], [0, 0, beta_(4,3), beta_(4,4)], [0, 0, beta_(5,3), beta_(5,4)]]`
For `m` columns of `A`, we would have `Q_m^TQ_(m-1)^T...Q_1^TA`. Then `Q^T = Q_m^TQ_(m-1)^T...Q_1^T`.
It turns out that `Q = I - 2u u^T` where `u = (x - y)/norm(x-y)_2`. `I` is the identity matrix. `x` is the column vector we're trying to change and `y` is the column vector we're trying to get. Doing the `QR` decomposition this way is known as doing it with "reflectors", where `Q` is the reflector.
Alternatively, `Q = I - 2/norm(u)_2^2 u u^T`
Example: Find `Q` s.t. `Q[[3],[4]] = [[-tau],[0]]`
Since orthogonal matrices don't change the size of vectors, `norm([[3],[4]])_2 = norm([[-tau],[0]])_2`
`sqrt(3^2 + 4^2) = sqrt((-tau)^2 + 0^2) => tau = 5`
So the problem becomes finding `Q` such that `Q[[3],[4]] = [[-5],[0]]`
`u = (x - y)/norm(x-y)_2 = ([[3],[4]] - [[-5],[0]])/norm([[3],[4]] - [[-5],[0]])_2 = ([[8],[4]])/norm([[8],[4]])_2 = 1/sqrt(8^2 + 4^2) [[8],[4]] = 1/sqrt(80) [[8],[4]]`
So `Q = I - 2u u^T = I - 2(1/sqrt(80)[[8],[4]])(1/sqrt(80)[[8, 4]]) = I - 2/80 [[8],[4]] [[8, 4]]`
Once we know what `Q` is, we are able to find `R` from `A = QR => R = Q^TA`.
Example: Given `A = [[3, 5],[4, 0],[0, 3]]`, find `R`
First, we have to find `Q`. Since `A` has `2` columns, `Q = Q_1Q_2`. We start by finding `Q_1`. That means changing the first column of A into the form `[[-tau],[0],[0]]` and finding out what `u` is.
`[[3],[4],[0]] -> [[-tau],[0],[0]]`
`norm([[3],[4],[0]])_2 = norm([[-tau],[0],[0]])_2 => tau = 5`
`u = (x - y)/norm(x-y)_2 = ([[3],[4],[0]] - [[-5],[0],[0]])/norm([[3],[4],[0]] - [[-5],[0],[0]])_2 = ([[8],[4],[0]])/norm([[8],[4],[0]])_2 = 1/sqrt(80)[[8],[4],[0]]`
`Q_1 = = I - 2/norm(u)_2^2 u u^T = I - 2/80 [[8],[4],[0]] [[8, 4, 0]]`
Remember that the end goal is `R = Q^TA = (Q_2Q_1)^TA = Q_2^TQ_1^TA`. We can solve for `Q_1^TA`:
By design, we found a `Q_1` such that it would turn the first column of `A` into `[[-5],[0],[0]]`. So we have:
`Q_1^T[[3],[4],[0]] = [[-5],[0],[0]]`. We need to know what `Q_1^T` does to the other column of `A`:
`Q_1^T[[5],[0],[3]] = (I - 2/80 [[8],[4],[0]] [[8, 4, 0]])^T [[5],[0],[3]] = (I - 2/80 [[8, 4, 0]]^T [[8],[4],[0]]^T) [[5],[0],[3]]`
`= (I - 2/80 [[8],[4],[0]] [[8, 4, 0]]) [[5],[0],[3]] = [[5],[0],[3]] - 2/80 [[8],[4],[0]] ([[8, 4, 0]][[5],[0],[3]])`
`= [[5],[0],[3]] - 2/80 [[8],[4],[0]] (40) = [[5],[0],[3]] - [[8],[4],[0]] = [[-3],[-4],[3]]`
So `Q_1^TA = Q_1^T[[3, 5],[4, 0],[0, 3]] = [[-5, -3],[0, -4],[0, 3]]`
Now we need to find `Q_2` that changes the second column into `[[-tau_2],[0]]`**.
`[[-4],[3]] -> [[-tau_2],[0]]`
`norm([[-4],[3]])_2 = norm([[-tau_2],[0]])_2 => tau = 5`
Now that we've changed all the columns of `A` into the form we need, we're done:
`Q_2^TQ_1^TA = [[-5, -3],[0, -5],[0, 0]] = R`
**we can't change the `-5` in `[[-5, -3],[0, -4],[0, 3]]` because `Q` preserves lengths of vectors. `norm([[3],[4],[0]])_2 = norm([[-tau],[0],[0]])` so `tau` must be `5`. Changing the `-5` violates this property, so we only work below the first row for `Q_2`. Namely, `[[0, -4],[0, 3]]`.
We could get `Q` by doing `Q = Q_1Q_2`.
The story thus far: When `A` is a square `n xx n` matrix, we can use the techniques mentioned near the beginning of the story, like Cholesky decomposition or iterative methods to solve the problem. Those methods don't really work when `A` is `n xx m` though. Solving `Ax = b` when `A` is not a square matrix is known as the least squares problem. One way of solving the least squares problem is doing `QR` decomposition.
Singular Value Decomposition
"This is the single most important thing in all of matrix analysis." -Professor Alex Cloninger
`QR` decomposition only works in some situations*. A more powerful method that works in all(?) situations is singular value decomposition (SVD).
*it only works when `A` has full rank, i.e. `A` has `m` pivots, i.e. `A` has `m` linearly independent column vectors, i.e. `A` has `n` linearly independent row vectors. The list goes on. I think.
Let `A` be an `n xx m` matrix with rank `r`. Then `A = USigmaV^T` where:
`U` is an `n xx n` orthogonal matrix
`V` is an `m xx m` orthogonal matrix
`Sigma = [[sigma_1, -, -, -, -, -],[-, sigma_2, -, -, -, -],[-, -, ddots, -, -, -],[-, -, -, sigma_r, -, -],[-, -, -, -, 0, -],[-, -, -, -, -, ddots]]` is an `n xx m` "diagonal" matrix
where the dashes are `0`s
`sigma_1 >= sigma_2 >= ... >= sigma_r` are singular values
Alternatively, `A = sum_(i = 1)^r sigma_iu_iv_i^T`
Assuming we know the values of `v_i`, how do we find the values of `sigma_i` and `u_i`?
It turns out that:
`Av_i = sigma_iu_i`
`A^Tu_i = u_i^TA = sigma_iv_i`
for `1 le i le r`
To get `sigma_i`, we can look at `(A^TA)v_i`:
`(A^TA)v_i = A^T(Av_i)`
`= A^T(sigma_iu_i)`
`= sigma_iA^Tu_i = sigma_i(A^Tu_i)`
`= sigma_i(sigma_iv_i)`
`= sigma_i^2v_i`
So we get `A^TAv_i = sigma_i^2v_i`. This means `sigma_i^2` is an eigenvalue of `A^TA`. That means all `sigma_i` are the square roots of the eigenvalues of `A^TA`. To find the singular values `sigma_i` of `A`, we find the eigenvalues of `A^TA` and take the square root of them.
Very informally, `A^TA` is kinda like `A^2`. So finding the eigenvalues of that and taking the square root gives us the eigenvalues of `A`.
Since we have `Av_i = sigma_iu_i`, we can divide both sides by `sigma_i` to get `u_i`:
`(Av_i)/sigma_i = u_i`
Another way to find the values of `u_i` is to find the eigenvectors of `A A^T`.
It turns out that the eigenvectors of `A A^T` are the columns of `U` and the eigenvectors of `A^TA` are the columns of `V`.
The singular values `sigma_i` are the square roots of the eigenvalues of `A A^T` or `A^TA`. An interesting point arises when we look at the sizes of each matrix. `A` is an `n xx m` matrix, so `A A^T` is an `n xx n` matrix whereas `A^TA` is an `m xx m` matrix. Since `n != m`, either `n > m` or `n lt m`. Either way, one matrix will be smaller than the other. So it would be faster to find out which matrix is smaller compute the eigenvalues of the smaller matrix.
Besides being used to find the decomposition of `A`, `sigma_i` is important in another way. We've looked at `norm(A)_2` but only when `A` was a square matrix. Here, `A` isn't a square matrix, so the norm is a bit different. It turns out that `norm(A)_2 = sigma_1`.
Example: `A = [[1, 0, 1],[1, 1, 0]]`. What is `norm(A)_2`?
We know that `norm(A)_2 = sigma_1`. And to find `sigma_1` we need to find the eigenvalues of either `A A^T` or `A^TA`. So first we want to find out which one of `A A^T` and `A^TA` is smaller. `A A^T` is `2 xx 2` and `A^TA` is `3 xx 3`, so we find the eigenvalues of `A A^T`.
`A A^T = [[1, 0, 1],[1, 1, 0]] [[1, 1],[0, 1],[1, 0]] = [[2, 1],[1, 2]]`*
To find the eigenvalues of `A A^T`, we find the determinant of `A A^T - lambdaI` and set it equal to `0`.
`abs(A A^T-lambdaI) = abs([[2-lambda, 1],[1, 2-lambda]]) = (2-lambda)^2 - 1^2 = lambda^2 - 4lambda + 3 = 0 => lambda = 3,1`
Since `sigma_1 >= sigma_2 >= ... >= sigma_r` and we're looking for `sigma_1`, we consider the larger eigenvalue `3`.
`3` is an eigenvalue of `A A^T`, so `sigma_1` of `A` is `sqrt(3)` (`sigma_2` would be `sqrt(1) = 1`).
So `norm(A)_2 = sigma_1 = sqrt(3)`
*`A A^T` will always be symmetric. By definition, `A` is symmetric if `A^T = A`. So `(A A^T)^T = (A^T)^TA^T = A A^T`.
Similarly, `A^TA` will also always be symmetric. `(A^TA)^T = A^T(A^T)^T = A^TA`.
Singular values are also helpful with finding the condition number of a non-square matrix. For a square matrix, the condition number was defined as:
`kappa(A) = norm(A)norm(A^(-1))`
However, non-square matrices don't have an inverse. So that definition of condition number doesn't make sense in this situation. We also defined condition numbers as:
`kappa(A) = (text(maxmag)(A))/(text(minmag)(A))`
Here, the maximum `A` can stretch a vector is `sigma_1` and the minimum `A` can stretch a vector is `sigma_m`.
`kappa(A) = sigma_1/sigma_m`
when `n > m`
And the condition number for non-square matrices is a measure of how good the least squares approximation will be.
In general, when we use the determinant method to find the eigenvalues of a `2 xx 2` matrix, we end up with a quadratic equation (`ax^2 + bx + c = 0`). For `3 xx 3`, we end up with a cubic equation. For `4 xx 4`, we end up with a quartic equation. It is always possible to find the roots of those equations. But for polynomials with degree greater than `5`, there are no formulas for finding the roots. This means the determinant method won't always work for matrices `5 xx 5` and greater.
That would mean that SVD decomposition would only work if `A^TA` was smaller than `5 xx 5`. This isn't true however. So we have to look at another way to find an eigenvalue.
Note: From here on, I use `A`, but most of the time, it's referring to `A^TA` or `A A^T`.
Power Method
First, some terminology. `(lambda, v)` is an eigenpair of `A` if `Av = lambdav`. If `A` has eigenpairs `(lambda_i, v_i)`, then, by convention, we order them such that `abs(lambda_1) > abs(lambda_2) > ... > abs(lambda_n)`. `lambda_1` is considered the dominant eigenvalue.
Not only does the determinant method not work for big matrices, it only gives us the eigenvalues. We have to do a completely different method to find the eigenvectors. The power method gives us both the eigenvalues and eigenvectors (eigenpairs) at the same time. (The power method actually gives us the dominant eigenvalue. Variations of the power method give us all the eigenvalues.)
There is a restriction for the power method though. It only works when `A` is semisimple, i.e., all the eigenvalues are distinct.
So how does it work? Let's pick a random vector `q`. We can rewrite `q` in terms of the eigenvectors of `A`:
`q = c_1v_1 + ... + c_nv_n`
Now, let's multiply `q` by `A`:
`Aq = c_1lambda_1v_1 + ... + c_nlambda_nv_n`
since `Av_i = lambda_iv_i`
Repeatedly multiplying by `A` results in:
`A^2q = c_1lambda_1^2v_1 + ... + c_nlambda_n^2v_n`
`vdots`
`A^kq = c_1lambda_1^kv_1 + ... + c_nlambda_n^kv_n`
Factoring out the `lambda_1^k`, we get:
`A^kq = lambda_1^k(c_1v_1 + c_2(lambda_2/lambda_1)^kv_2 + ... + c_n(lambda_n/lambda_1)^kv_n)`
When `k` gets large enough, then `A^kq ~~ lambda_1^kc_1v_1` (since `abs(lambda_1)` is greater than `abs(lambda_i)`, `lambda_i/lambda_1` will be less than `1` and with repeated multiplications, will get to `0`.)
Then we have:
`A^kq ~~ lambda_1^kc_1v_1 => (A^kq)/lambda_1^k ~~ c_1v_1`
This gives us a way of finding the eigenvector. How large will `k` be before we get a good estimate? If we let `q^((k)) = (A^kq)/lambda_1^k`, then we can look at `norm(q^((k))-c_1v_1)_2`:
`norm(q^((k))-c_1v_1)_2 = norm((lambda_2/lamda_1)^kc_2v_2 + ... + (lambda_n/lambda_1)^kc_nv_n)_2`
`le sum_(i = 2)^n (lambda_i/lambda_1)^k abs(c_i)norm(v_i)_2` (by triangle inequality)
`le abs(lambda_2/lambda_1)^k sum_(i = 2)^n abs(c_i)norm(v_i)_2` (since `lambda_1 > lambda_2 > ... > lambda_i`)
So `norm(q^((k)) - c_1v_1)_2 le abs(lambda_2/lambda_1)^k sum_(i = 2)^n abs(c_i)norm(v_i)_2` goes to `0` as `k -> oo`. This means that we should stop when `abs(lambda_2/lambda_1)^k` is really small.
This says that repeatedly multiplying `q` by `A` and dividing by `lambda_1` will eventually give us the eigenvector `v_1`. It also says that if `abs(lambda_2/lambda_1)` is much smaller than `1`, then it won't take long for this method to converge (i.e. `k` will be small). But if `abs(lambda_2/lambda_1)` is close to `1` (i.e., `lambda_2` is close to `lambda_1`), then it will take a long time to converge (i.e., `k` will be large).
We have a way of finding the eigenvector, but it is dependent on the eigenvalue. And we currently don't know the eigenvalue. It turns out that we can't really compute it exactly, so we make an educated guess as to what it could be.
Example: `A = [[2, 0],[0, 1]]`. We start with a guess `q^((0)) = [[1],[1]]`.
Throughout, we let `s_j` be the "guess" as to what the eigenvalue could be after the `j^(th)` step. `q^((j))` would be the approximation of the eigenvector after the `j^(th)` step. We choose `s_j` to be the largest entry in `Aq^((j-1))`. `q^((j))` would be `(Aq^((j-1)))/s_j`.
`Aq^((0)) = [[2],[1]]`, `s_1 = 2`, `q^((1)) = [[1],[1/2]]`
`Aq^((1)) = [[2],[1/2]]`, `s_2 = 2`, `q^((2)) = [[1],[1/4]]`
`Aq^((2)) = [[2],[1/4]]`, `s_3 = 2`, `q^((3)) = [[1],[1/8]]`
`vdots`
`Aq^((k)) = [[2],[1/2^k]]`, `s_k = 2`, `q^((k)) = [[1],[1/2^k]]`
So our guess for the eigenvalue is `2` and the eigenvector would be `[[1],[0]]` as `k` gets large.
Example: `A = [[2, 1],[1, 4]]`. We start with a guess `q^((0)) = [[1],[1]]`.
`Aq^((0)) = [[3],[5]]`, `s_1 = 5`, `q^((1)) = [[3/5],[1]]`
`Aq^((1)) = [[11/5],[23/5]]`, `s_2 = 23/5`, `q^((2)) = [[11/23],[1]]`
`Aq^((2)) = [[45/23],[103/23]]`, `s_3 = 103/23`, `q^((3)) = [[45/103],[1]]`
So our guess for the eigenvalue is `4.4` and the eigenvector would be `[[4.4],[1]]`.
Inverse Power Method
The power method gives us one eigenvalue, namely the dominant one. But we still need to find the rest of the eigenvalues. It turns out that if `(lambda,v)` is an eigenpair of `A`, then `(1/lambda,v)` is an eigenpair of `A^(-1)`. This allows us to find the smallest eigenvalue of `A`. If `lambda^(text(*))` is the largest eigenvalue of `A^(-1)`, then `1/lambda^(text(*))` is the smallest eigenvalue of `A`.
Example: `A = [[10,1],[1,2]]`. What is the smallest eigenvalue? We start with a guess `q^((0)) = [[1],[1]]`.
Now we want to do the power method on `A^(-1)`, so we start by finding `A^(-1)`.
`A^(-1) = 1/(20-1)[[2,-1],[-1,10]] = [[2/19, -1/19],[-1/19,10/19]]`
Now we repeatedly do `A^(-1)q^((j))`:
`A^(-1)q^((0)) = [[1/19],[9/19]]`, `s_1 = 9/19`, `q^((1)) = [[1/9],[1]]`
`A^(-1)q^((1)) = [[-7/171],[91/171]]`, `s_2 = 91/171`, `q^((2)) = [[-7/91],[1]]`
`vdots`
Unfortunately, the numbers are getting ugly, but our guess for the eigenvalue is `0.53` and the eigenvector would be `[[-0.12],[1]]` as `k` gets large. But this is for `A^(-1)`. The eigenvalue of `A` is `1/0.53 ~~ 1.88` and the eigenvector is the same.
Shift-and-Invert
So we have the largest and the smallest eigenvalues of `A`. But we still need the rest. It turns out that if `(lambda,v)` is an eigenpair of `A`, then `(lambda-rho,v)` is an eigenpair of `A - rhoI`.
We can shift the interval down by `rho` to get:
Now, `lambda_i` is the smallest eigenvalue and we can use the inverse power method to get the eigenvalue of `A`. Doing the inverse power method on the shifted `A` would result in the largest eigenvalue, `lambda`, of `(A-rhoI)^(-1)`. Then `1/lambda` would be the largest eigenvalue of `A-rhoI`.
Example: `A = [[3, 0, 0],[0, 2.01, 0],[0, 0, 1]]`. Find the eigenvalue closest to `rho = 2`.
We start with `A - 2I = [[1, 0, 0],[0, 0.01, 0],[0, 0, -1]]`, `(A - 2I)^(-1) = [[1, 0, 0],[0, 100, 0],[0, 0, -1]]`, and `q^((0)) = [[1],[1],[1]]`.
`(A - 2I)^(-1)q^((0)) = [[1],[100],[-1]]`, `s_1 = 100`, `q^((1)) = [[1/100],[1],[-1/100]]`
`(A - 2I)^(-1)q^((1)) = [[1/100],[100],[1/100]]`, `s_2 = 100`, `q^((2)) = [[1/10000],[1],[1/10000]]`
So our guess for the eigenvalue is `100` and the eigenvector would be `[[0],[1],[0]]`. But this is for `(A-2I)^(-1)`. The eigenvalue of `A-2I` is `1/100`. Since we shifted left by `2`, we have to shift right by `2` to get the eigenvalue of `A`, which is `1/100 + 2`. The eigenvector is the same.
To summarize: We now have `3` methods for finding all the eigenvalues of a matrix. The power method finds the dominant eigenvalue. The inverse power method finds the smallest eigenvalue. And the shift-and-invert method gives us all the eigenvalues in between. Finding all the eigenvalues of a matrix allows us to do a singular value decomposition on a matrix.
For the inverse power method and shift-and-invert methods, we've been calculating the inverse of `A` to perform the methods. As mentioned at the beginning of the story, inverting a matrix is a relatively time-consuming process. There's a better way to solve for `q^((j))`:
`(A - rhoI)^(-1)q^((j-1)) = q^((j))`
`=> (A - rhoI)q^((j)) = q^((j-1))`
We know what `A - rhoI` is and we know what `q^((j-1))` is. In fact, this is the same `Ax = b` problem this whole story is about. (In the note before the Power Method section, I mention that `A` in these past three sections is referring to `A^TA` or `A A^T`. So here, `A` really is a square matrix.) `A - rhoI` is probably not positive definite, but it likely has a `LU` decomposition. Then we can write `A - rhoI` as `LU` to get:
`(A - rhoI)q^((j)) = q^((j-1))`
`=> (LU)q^((j)) = q^((j-1))`
Then we can use forward and back sub to get the values for `q^((j))`, which is relatively faster. This allows us to compute `L` and `U` one time and store them to make future calculations faster.
It turns out that if `A` is triangular, then `A - rhoI` is also triangular. Then `(A - rhoI)q^((j)) = q^((j-1))` can be solved mmediately with forward/back sub without having to find the `LU` decomposition.
Computers actually go about this by turning `A` into a tridiagonal matrix by using reflectors (from the `QR` Decomposition section), because forward/back sub with a tridiagonal matrix is really fast. Reflectors turn a vector into another vector with numbers on the top and `0`s on the bottom. So reflectors can be used to turn the columns of `A` into a vector with `3` numbers on top and `0`s on the bottom:
`[[a_(1,1), a_(1,2), a_(1,3), a_(1,4)],[a_(2,1), a_(2,2), a_(2,3), a_(2,4)],[a_(3,1), a_(3,2), a_(3,3), a_(3,4)],[a_(4,1), a_(4,2), a_(4,3), a_(4,4)]] -> [[alpha_(1,1), alpha_(1,2), 0, 0],[alpha_(2,1), alpha_(2,2), alpha_(2,3), 0],[0, alpha_(3,2), alpha_(3,3), alpha_(3,4)],[0, 0, alpha_(4,3), alpha_(4,4)]]`