Functional Programming
Shortcut to this page: ntrllog.netlify.app/fp
Notes provided by Professor John Hurley (CSULA)
(all code examples are done in Kotlin with expression bodies when possible)
Kotlin Basics
Write code that uses recursion to calculate the sum of all integers from `1` to `n`, and print the result.
fun summation(n: Int): Int =
if (n == 1) 1
else n + summation(n-1)
fun main() {
println(summation(4))
}
Write an isPyth(a,b,c) function with an expression body that takes three Doubles as arguments and returns true if they are a Pythagorean triple, otherwise returns false. Use Math.pow(base, exponent), where both base and exponent are Doubles. Double has an equals() method; use that, not ==.
fun isPyth(a: Double, b: Double, c: Double): Boolean =
(Math.pow(a, 2.0) + Math.pow(b, 2.0)).equals(Math.pow(c, 2.0))
Write a palindrome check function. Use this algorithm:
- if the length of the string is less than `2`, return true
- else if the first and last characters are not equal, return false
- else return the result of a recursive call with the substring from the second character (the one at index `1`) to the second to last character
fun isPalindrome(s: String): Boolean =
if (s.length < 2) true
else if (s[0] != s[s.length-1]) false
else isPalindrome(s.substring(1, s.length-1))
Write a function getArea() which takes a Double radius and returns the area of a circle with the given radius (Math.PI times radius ^ `2`).
fun getArea(r: Double): Double = Math.PI * r * r
Write a recursive function that takes an Int `n` and returns a list of the areas of circles for each radius from `n` to `1` (in decreasing order.) Get the areas by calling the area function above. Then rewrite the recursive function so that the areas appear in increasing order.
fun getAreasDec(n: Int): List<Double> =
if (n == 0) listOf()
else listOf(getArea(n.toDouble())) + getAreasDec(n-1)
fun getAreasInc(n: Int): List<Double> =
if (n == 0) listOf()
else getAreasInc(n-1) + listOf(getArea(n.toDouble()))
Create a list that uses the getArea() function as an initializer and contains the areas of circles with each integer from `1` to `25` as the radius.
val l = List<Double>(25){i -> getArea((i+1).toDouble())}
Create a list of Ints from `1` to `25`. Then use map() with the list and the getArea() function to create a list of the areas of circles with each of the Ints as the radius.
val l: List<Int> = (1..25).toList()
val m: List<Double> = l.map{getArea(it.toDouble())}
Using an initializer expression, create a list of the Ints from `0` to `25`, and another of the squares of the Ints from `0` to `25`. Then zip the two lists and print the result.
val l1 = List<Int>(26){it}
val l2 = List<Int>(26){it * it}
val l3 = l1.zip(l2)
println(l3)
Write a recursive function that takes a list of Pairs in which each value may be of any type, and returns a list of the first elements from each pair.
fun firstOf(l: List<Pair<Any, Any>>): List<Any> =
if (l.isEmpty()) listOf()
else listOf(l[0].first) + firstOf(l.drop(1))
Write one line of code that uses filter() and zip() to take two lists of Strings and zip only those pairs in which each String is longer than four characters.
val l = l1.zip(l2).filter{it.first.length > 4 && it.second.length > 4}
Use filter() to create a list of Strings that consists only of Strings that contain the character 'r'.
val r = l.filter{"r" in it}
Write a recursive function called myZip that takes two lists of type Any and returns a List of Pairs in which each value may be any type. The pairs consist of corresponding elements in the two lists (the first element of the first list and the first element of the second list, etc). The base case should be that either (or both) of the original lists has length `1`, so that, if the lists have different length, the zipping stops when one of the lists runs out of values.
fun myZip(l1: List<Any>, l2: List<Any>): List<Pair<Any, Any>> =
if (l1.size == 1 || l2.size == 1) listOf(Pair<Any, Any>(l1[0], l2[0]))
else listOf(Pair<Any, Any>(l1[0], l2[0])) + myZip(l1.drop(1), l2.drop(1))
Write a function lengthGreaterThan() that takes a String `s` and an Int `n` and returns true if the String is at least `n` characters long. Then revise the function so that it can accept null values. If it receives null as the parameter, it should return false.
fun lengthGreaterThan(s: String, n: Int): Boolean = s.length >= n
fun lengthGreaterThanVer2(s: String?, n: Int?): Boolean =
if (s == null || n == null) false
else s.length >= n
Write a recursive function myFilter() that takes a list of nullable Strings and an Int and returns a list of just the Strings from the original list that satisfies the above condition.
fun myFilter(l: List<String?>, n: Int): List<String?> =
if (l.isEmpty()) listOf()
else if (lengthGreaterThanVer2(l[0], n)) listOf(l[0]) + myFilter(l.drop(1), n)
else myFilter(l.drop(1), n)
Get the same result above by using filter().
l.filter{lengthGreaterThanVer2(it, n)}
Write code that declares two nullable String values, sets one to "Godzilla" and the other to null. Then, for each one, if it is not null, print the upper case version (use the String method uppercase()), but if it is null, print the String "nothing to print!". Do this in two different ways: once using if/else and once using both the safe call operator and the Elvis operator.
val s1: String = "Godzilla"
val s2: String? = null
for (s in listOf(s1, s2)) {
if (s != null) {
println(s.uppercase())
} else {
println("nothing to print!")
}
println(s?.uppercase() ?: "nothing to print!")
}
Write a function called isLong() that takes one argument whose type is Any and returns whether or not the value is a Long.
fun isLong(a: Any): Boolean = a is Long
Use as once in a way that will correctly cast from Any to a specific type, and once in a way that will throw an exception.
val s1: Any = "hi"
val s2: Any = 43
val s3: String = s1 as String
val s4: String = s2 as String
Let's say we have this color Enum:
enum class Color {
RED, ORANGE, YELLOW, GREEN, BLUE, INDIGO, VIOLET
}
Create a Monster data class. A monster has a name, height, and favorite color. The class should also have a property called isNamedGodzilla, with an accessor that will return true if the monster is named Godzilla, else false. The class should also have a heightRatio() function, which takes another Monster as a parameter and returns the ratio of the instance monster's height to that of the parameter Monster.
data class Monster(val name: String, val height: Double, val favColor: Color) {
val isNamedGodzilla: Boolean
get() {
return name == "Godzilla"
}
fun heightRatio(m: Monster): Double = this.height / m.height
}
Write a recursive linear search function that takes a String and a Char and returns true if the String contains the Char. The base cases are that a) the length of the String is `0` or b) the first character in the String is the character we are searching for.
fun linSearch(s: String, c: Char): Boolean =
if (s.length == 0) false
else if (s[0] == c) true
else linSearch(s.drop(1), c)
Modify the linear search function so that both the String and the Char are nullable. If either is null, return false.
fun linSearch(s: String?, c: Char?): Boolean =
if (s == null || c == null) false
else if (s.length == 0) false
else if (s[0] == c) true
else linSearch(s.drop(1), c)
Write code that creates a list of nullable Strings.
val l: List<String?> = listOf("hey", null, "hi", null)
Write the function divIntSafe(a: Int, b:Int). This function should take two Ints, convert them to Doubles, divide the first by the second, and return the result.
fun divIntSafe(a: Int, b: Int): Double = a.toDouble() / b.toDouble()
Write code that creates a list of the inverses of the Ints from `1` to `10`. Do this in two ways: using a lambda expression as the initializer expression and using divIntSafe() as the initializer expression.
val l1: List<Double> = List<Double>(10){1/(it + 1).toDouble()}
val l2: List<Double> = List<Double>(10){divIntSafe(1, it+1)}
Write code that declares a nullable Int (give it a value), then declares a nullable Double and uses the safe call operator to set its value to null if the nullable Int was null, else to the result of casting the Int to a Double.
val n: Int? = null
val d: Double? = n?.toDouble()
Write code that declares a nullable Int (give it a value), then declares a nullable Double and uses the safe call operator and the Elvis operator to set its value to `0.0` if the nullable Int was null, else to the result of casting the Int to a Double.
val n: Int? = null
val d: Double? = n?.toDouble() ?: 0.0
Consider this apply() method:
fun apply(s: String, f: (String) -> String): String = f(s)
Use a lambda expression in a call to apply(). Then write some function and use it in a call to apply().
val s1 = apply("hey", { it + "z" })
fun prependA(s: String): String = "a" + s
val s2 = apply("hey", ::prependA)
Write code that divides `1` by `7` and prints the result to `5` decimal places.
"%.5f".format(1.0/7.0)
Write a function printInt() that can accept an input parameter of Any type and return an Int using the when construct.
fun printInt(a: Any): Int =
when (a) {
is Int -> a
is Double -> a.toInt()
is String -> a.length
is IntArray -> a.sum()
else -> -1
}
Pure Functions
A pure function is a function that:
- always returns the same value for the same input
- has no side effects
Referential Transparency
Consider the function:
fun doubleIt(n: Int): Int = n * 2
and consider the input `n=3`. We can see that for `n=3`, the output will always be `6` no matter what.
This can be thought of as referential transparency, meaning that calls to the same function with the same arguments will always return the same value.
Technically, referential transparency refers to the ability to replace an expression with its value while still maintaining the correctness of the code. For example, if, for some reason, we had doubleIt(3) in our code, we could replace it with 6 and the program would still work the same way.
val x = doubleIt(3) // this line can be rewritten as val x = 6
This replacement is possible only because the function will always return the same value for the same input. Which is why the definition of referential transparency can be thought of this way.
(In a way, the definition of referential transparency is referentially transparent? 🤔😏)
That's Not Very Referentially Transparent of You
An example of a function that's not referentially transparent is this:
val cost = 0.73
fun getCost(n: Int): Double = n * cost
If the value of cost is changed, then getCost() will return something different for the same input.
Side Effects
Side effects are changes that are caused by a function call, but the changes themselves occur outside of the function call. These changes usually are not necessary for calculating the return value of the function (assuming, in the spirit of functional programming, that the primary purpose of a function is to return something rather than do something). Some examples of side effects are:
- modifying a variable beyond the scope of the block where the change occurs
- modifying a data structure in place
- setting a field on an object
- throwing an exception or halting with an error
- printing to the console
- reading user input
- reading from or writing to a file
- drawing on the screen
This is an example of a function that modifies a variable outside of its scope (and prints):
var counter = 0
fun incrementCounter() {
++counter
println(counter)
}
Data Immutability
In functional programming, data are not allowed to be changed* once it is created. So something as simple (and seemingly essential) as a loop is not allowed. Consider this loop:
for (num in numbers) {
squaredNums += listOf(num * num)
}
num and squaredNums are being changed on every iteration of the loop, and data are not allowed to be changed!
*Changed means reassigned to a different value.
Instead of loops, recursion is used.
In the context of lists, if we want a different list (e.g., one of the elements need to be changed or removed), then we need to create a new list instead of modifying the original list.
val originalList = listOf(1, 2, 3, 4, 5)
val newList = originalList.slice(0..1) + originalList.slice(3..originalList.size-1) // newList = [1, 2, 4, 5]
Why Functional Programming?
With functional programming, there are no side effects; there are no mutable data; and there is referential transparency. All of these make functional programming great for concurrent programming because there is no shared state, data synchronization issues, race conditions, and deadlocks.
The code is more modular since there is no shared state.
Pure functions are less buggy than impure functions. Since they don't depend on external state, pure functions are more reliable once they are thoroughly tested. Pure functions also don't have side effects, so they don't create unpredictable problems.
Referential transparency makes it possible to cache the result of a function call, so that the result can be used instead of calling the function again. (This is called memoization.)
Tail Recursion
Whenever a function call is made, a stack is created for that function call. So for recursive functions, a stack is created for each recursive call.
fun main() {
val n = factorial(3)
}
fun factorial(n: Int): Int = if (n <= 1) n else n * factorial(n-1)

If too many recursive calls are made, then too many stacks will be created, resulting in a stack overflow. Since we're pretty much limited to recursion in functional programming, we have to find a way to use recursion without running into a stack overflow.
Well, we can avoid having too many stacks by getting rid of them once we don't need them anymore. Going back to the recursion animation above, notice that each stack after the main stack needs to allocate memory for an Int (the n in n * factorial(n-1)). This means that the recursive call is not the last thing that is performed in the stack (the multiplication is the last thing being performed). Because we need to store the n in each stack in order for the recursion to work, we cannot simply remove the stack after a recursive call. But it would be nice to be able to do so!
So if we don't want to store anything in each stack, then that means we should push all the information we need to the next stack. Consider this modified factorial function:
fun main() {
val n = factorial(3, 1)
}
fun factorial(n: Int, accumulator: Int): Int = if (n <= 1) accumulator else factorial(n-1, n * accumulator)
This modification pushes the result of each multiplication forward (in the accumulator) so that it doesn't need to be stored.

(lol there's no animation here.)
Notice now that the recursive call is the last thing that is performed in the stack and that no memory needs to be allocated to store anything — this is tail recursion! Capable compilers are able to take advantage of this and remove the previous stack on each recursive call — after all, there's no important information being stored in the previous stack (this is tail-call elimination/optimization!)

The fact that the stacks can be removed is nice, but this factorial function is a bit awkward. It's not intuitive to need two parameters to calculate the factorial of a number. In addition, if we accidentally put the wrong initial value for the accumulator, then the answer will be wrong.
Helper Function to the Rescue!
Consider this final version of the factorial function:
fun main() {
val n = factorial(3)
}
fun factorial(n: Int): Int {
tailrec fun helper(x: Int, accumulator: Int): Int =
if (x <= 1) accumulator
else helper(x-1, x * accumulator)
return helper(n, 1)
}
Here, we have a nested function (helper()) that is called recursively. The outer function (factorial()) is no longer called recursively; instead it kicks off the recursive process. This allows the factorial function to be clean while still getting the benefits of tail-call elimination.

A Systematic Approach to Making Functions Tail Recursive
There are three main ideas:
- there is an outer function that defines and calls an inner function, which is going to be the recursive one
- the inner function takes in an accumulator that starts with an initial value and builds up the result at each recursive step
- the base case returns the accumulator
Let's look at string reversal as an example.
There is an outer function:
fun myReverse(s: String): String {
That defines an inner function, which takes in an accumulator:
fun myReverse(s: String): String {
tailrec fun helper(x: String, acc: String): String =
The base case returns the accumulator:
fun myReverse(s: String): String {
tailrec fun helper(x: String, acc: String): String =
if (x.length == 0) acc
The inner function is recursive and the accumulator builds up the result at each recursive step:
fun myReverse(s: String): String {
tailrec fun helper(x: String, acc: String): String =
if (x.length == 0) acc
else helper(x.dropLast(1), acc + x[x.length-1])
The outer function calls the inner function with an initial value for the accumulator:
fun myReverse(s: String): String {
tailrec fun helper(x: String, acc: String): String =
if (x.length == 0) acc
else helper(x.dropLast(1), acc + x[x.length-1])
return helper(s, "")
}
Tail Recursion Practice Problems
Write a recursive harmonic number (`1/1 + ... + 1/n`) function using a tail-recursive helper function.
fun harm(n: Int): Double {
tailrec fun helper(n: Int, acc: Double): Double =
if (n == 0) acc
else helper(n-1, acc + 1.0/n)
return helper(n, 0.0)
}
Consider this appAllTR() function:
fun appAllTR(l: List<String>, f: (String) -> String): List<String> {
tailrec fun helper(l: List<String>, f: (String) -> String, acc: List<String>): List<String> =
if (l.isEmpty()) acc
else helper(l.drop(1), f, acc + listOf(f(l.get(0))))
return helper(l, f, emptyList<String>())
}
Change the appAllTR() function so that it takes a list of Ints and a function from Int to Int and returns a list of Ints. Write an abs() function that takes an Int and returns its absolute value (if `n` is less than zero, return `-n`, otherwise return `n`). Test appAllTR() with the abs() function as an argument, then with a lambda expression that has the same logic.
fun appAllTR(l: List<Int>, f: (Int) -> Int): List<Int> {
tailrec fun helper(l: List<Int>, f: (Int) -> Int, acc: List<Int>): List<Int> =
if (l.isEmpty()) acc
else helper(l.drop(1), f, acc + listOf(f(l.get(0))))
return helper(l, f, emptyList<Int>())
}
fun abs(n: Int): Int =
if (n < 0) -n
else n
val x = appAllTR(l, ::abs)
val y = appAllTR(l, { if (it < 0) -it else it })
Write the function myStringFilter(), which takes a list of Strings and a function `f` from String to Boolean and returns a list the contains just those of Strings in the original list for which `f` is true. Use a tail recursive helper function. Call it with a lambda expression (for example, one that evaluates to true if the length of the String is greater than `4`) as the function.
fun myStringFilter(l: List<String>, f: (String) -> Boolean): List<String> {
tailrec fun helper(l: List<String>, f: (String) -> Boolean, acc: List<String>): List<String> =
if (l.isEmpty()) acc
else if (f(l[0])) helper(l.drop(1), f, acc + listOf(l[0]))
else helper(l.drop(1), f, acc)
return helper(l, f, emptyList<String>())
}
val x = myStringFilter(l, { it.length > 4 })
Change myStringFilter() so that it takes a list of nullable Strings and returns a list of Strings. Any nullable String that is null should not be included in the returned list. Call it with a lambda expression (for example, one that evaluates to true if the length of the String is greater than 4) as the function.
fun myStringFilter(l: List<String?>, f: (String?) -> Boolean): List<String?> {
tailrec fun helper(l: List<String?>, f: (String?) -> Boolean, acc: List<String?>): List<String?> =
if (l.isEmpty()) acc
else if (l[0] == null || f(l[0]) == false) helper(l.drop(1), f, acc)
else helper(l.drop(1), f, acc + listOf(l[0]))
return helper(l, f, emptyList<String?>())
}
val x = myStringFilter(l, { it?.length ?: 0 > 4 })
Write and the function applyToTwoLists(), which takes two lists of Doubles and a function `f` from Double to Double and returns a list of Doubles that consists of the results of applying the function to each pair of corresponding values from the two lists (that is, f(list1.get(0), list2.get(0)), then f(list1.get(1), list2.get(1)), etc.) Use a tail-recursive helper function.
fun applyToTwoLists(l1: List<Double>, l2: List<Double>, f: (Double, Double) -> Double): List<Double> {
tailrec fun helper(l1: List<Double>, l2: List<Double>, f: (Double, Double) -> Double, acc: List<Double>): List<Double> =
if (l1.isEmpty() || l2.isEmpty()) acc
else helper(l1.drop(1), l2.drop(1), f, acc + listOf(f(l1[0], l2[0])))
return helper(l1, l2, f, emptyList<Double>())
}
val x = applyToTwoLists(l1, l2, { x: Double, y: Double -> x + y })
Write and test the function myZip(), which takes a List<String> and a List<Int> and zips them, returning a List<Pair<String, Int>>. Don't call Kotlin's built in zip() function! Use a tail-recursive helper function.
fun myZip(l1: List<String>, l2: List<Int>): List<Pair<String, Int>> {
tailrec fun helper(l1: List<String>, l2: List<Int>, acc: List<Pair<String, Int>>): List<Pair<String, Int>> =
if (l1.isEmpty() || l2.isEmpty()) acc
else helper(l1.drop(1), l2.drop(1), acc + listOf(Pair<String, Int>(l1[0], l2[0])))
return helper(l1, l2, emptyList<Pair<String, Int>>())
}
Write a function countCharOccs(s:String, c: Char): Int that uses a tail-recursive inner function to find and return the number of occurrences of the Char in the String.
fun countCharOcc(s: String, c: Char): Int {
tailrec fun helper(s: String, c: Char, acc: Int): Int =
if (s.length == 0) acc
else if (s[0] == c) helper(s.drop(1), c, acc+1)
else helper(s.drop(1), c, acc)
return helper(s, c, 0)
}
A Different Way To Recurse
Now, I don't know about you, but when I learned about recursion, there was always some argument that would get smaller with each recursive call. For example, in the example above, the string being passed to the recursive helper function is getting smaller by one character each time until it is empty. I never really realized that this is not the only way to do things recursively.
If working with strings or lists, then instead of making the string or list smaller in each recursive call, we can just pass an increasing (or decreasing) index instead. 🤯
fun myReverse(s: String): String {
tailrec fun helper(n: Int, acc: String): String =
if (n < 0) acc
else helper(n-1, acc + s[n])
return helper(s.length-1, "")
}
Currying
Currying is taking a function with multiple arguments and breaking it up into mutiple functions, each with one argument.
(I feel like a function that adds two numbers is a very contrived and overused example, but let's roll with it!) Suppose we have a function that adds two numbers:
fun myAdd(x: Int, y: Int): Int = x + y
Now suppose we have a use case where we always want to add `5` to any number. Of course, we can simply just do myAdd(x, 5), whenever we need to, but we can make the function calls simpler and clearer. The idea is to create a new function (let's call it addFive()) that takes in only one argument and adds `5` to it. Simpler and clearer.
Time to curry the myAdd() function!
fun addCurried(x: Int): (Int) -> Int {
return fun(y: Int): Int = x + y
}
val add5 = addCurried(5)
val r = add5(10) // r = 15
We broke the myAdd() function into two smaller functions, each with one argument. The outer function takes in one of the arguments (x) and simply returns another function. That other function takes in the other argument (y) and does what the original myAdd() function would've done. Since the outer function returns a function, we can create new functions, like add5().
Closure
When we return from a function, everything in that function's scope gets destroyed. So it's interesting to note here that even when addCurried() returned, add5() still had access to the `5`, which was passed through x. Theoretically, x looks like it should've been inaccessible after addCurried() returned. But it isn't. A closure is a function that can access a variable that is defined outside of its scope, even after the outer function has returned.
Let's look at a more complicated, but more practical, example. Suppose we had our own filter function that filtered a list based on a custom function:
fun myFilter(l: List<Int>, f: (Int) -> Boolean): List<Int> = l.filter(f)
Time to curry!
fun filterCurried(f: (Int) -> Boolean): (List<Int>) -> List<Int> {
return fun(l: List<Int>): List<Int> = l.filter(f)
}
val isEven = { n: Int -> n % 2 == 0 }
val filterEven = filterCurried(isEven)
println(filterEven(listOf(1, 2, 3, 4, 5, 6)) // prints [2, 4, 6]
With this example, we can see a more useful reason to use currying. Imagine if we wanted to create filterEven() and filterOdd() but without currying.
fun filterEven(l: List<Int>): List<Int> = l.filter{it % 2 == 0}
fun filterOdd(l: List<Int>): List<Int> = l.filter{it % 2 == 1}
Notice how they're almost exactly the same. It seems like wasted repetition to create two similarly-defined functions this way.
Polymorphic Functions
Consider this function that searches for a string in a list of strings:
fun findFirst(l: List<String>, key: String): Int {
tailrec fun helper(n: Int): Int =
when {
n >= l.size -> -1
l.get(n) == key -> n
else -> helper(n+1)
}
return helper(0)
}
This is a monomorphic function because it operates only on one type of data, namely strings.
What if we wanted to search for an integer in a list of integers?
fun findFirst(l: List<Int>, key: Int): Int {
tailrec fun helper(n: Int): Int =
when {
n >= l.size -> -1
l.get(n) == key -> n
else -> helper(n+1)
}
return helper(0)
}
With the exception of the parameter types, the code is exactly the same. Of course, it seems like a waste to create two separate functions that do the exact same thing, just with different types.
Polymorphic functions are functions that operate on any type that it is given.
fun <A> findFirst(l: List<A>, key: A): Int {
tailrec fun helper(n: Int): Int =
when {
n >= l.size -> -1
l.get(n) == key -> n
else -> helper(n+1)
}
return helper(0)
}
This function will work for strings, ints, doubles, anything really.
This type of polymorphism is called parametric polymorphism. Polymorphism in object-oriented programming is subtype polymorphism.
Predicate Functions
A predicate function is a pure function that returns either true or false. These are typically used as custom compare functions. For example, here is a predicate function (written as a lambda expression) that returns true if the input to the function contains the letter l:
{ it.contains('l') }
So instead of being restricted to whatever condition is inside the when statement, we can pass our own compare function:
fun <A> findFirst(l: List<A>, f: (A) -> Boolean): Int {
tailrec fun helper(n: Int): Int =
when {
n >= l.size -> -1
f(l.get(n)) -> n
else -> helper(n+1)
}
return helper(0)
}
val i: Int = findFirst(l, { it.contains('l') })
Polymorphic functions are also called generic functions because the types are being abstracted.
Quicksort is a sorting algorithm that starts with a pivot element, sorts the sublist that is "less than" the pivot element, sorts the sublist that is "greater than" the pivot element, and then combines them together to get a sorted list. Typically, the pivot is chosen randomly, but here we'll use the first element of the (sub)list(s) as the pivot.
Here's a pretty cool example of quicksort with generic types and a predicate function:
fun <A> quicksort(l: List<A>, f: (x: A, y: A) -> Int): List<A> =
if (l.size <= 1) l
else quicksort(l.drop(1).filter{ f(it, l.get(0)) < 0 }, f) + l.get(0) + quicksort(l.drop(1).filter{ f(it, l.get(0)) >= 0 }, f)
fun main() {
val l1 = listOf(41, 89, -10, 54, 16, 543, 4)
val l2 = listOf("pizza", "taco", "cheeseburger", "french fries", "popcorn", "pie")
println(quicksort(l1, {x, y -> if(x < y) -1 else if(x == y) 0 else 1 }))
println(quicksort(l2, {x, y -> if(x.length < y.length) -1 else if( x.length == y.length) 0 else 1}))
}
As convenient as it looks, we don't always want polymorphic functions to accept any type. To show why, here's a simple example:
fun <A> oneHalf(value: A): Double = value.toDouble() / 2.0
Obviously, this only works with number-like types; so if we pass in a string, things will go wrong. To prevent this, we can restrict the types that can be used as type arguments:
fun <A: Number> oneHalf(value: A): Double = value.toDouble() / 2.0
This says that we can pass in any type for A as long as it is a Number type.
A more practical example would be writing one compare function that works for multiple types, including custom classes:
fun <A: Comparable<A>> max(first: A, second: A): A = if (first.compareTo(second)) first else second
Here, we can pass in any type for A as long as it is Comparable.
Higher-Order Functions Practice Problems
Write a higher-order function (idk, call it myF()) that takes two arguments and returns a String. The first argument is a String and the second is a function that takes a Char and returns a Boolean. Your function should return a String containing those of the characters in the original String for which the function returns true. Use a tail-recursive helper function. Test the function with several different lambdas (for example, one that returns true if the Char is not 'l' and then one that returns true if the Char is later in lexicographic order than 'f').
fun myF(s: String, f: (Char) -> Boolean): String {
tailrec fun helper(n: Int, acc: String): String =
when {
n >= s.length -> acc
f(s[n]) -> helper(n+1, acc + s[n])
else -> helper(n+1, acc)
}
return helper(0, "")
}
val x = myF("hello", { it != 'l' })
val y = myF("hey", { it > 'f' })
Consider this Employee class and this list of Employees:
data class Employee(val name: String, val wage: Double, val hours: Double)
val l: List<Employee> = listOf(Employee("Bob", 34.33, 42.0), Employee ("Cathy", 27.33, 15.25), Employee("Carlos", 46.99, 38.75), Employee("Tomas", 49.66, 28.45), Employee("Xavier", 34.56, 11.5))
Write one line of code that uses filter(), sortedBy(), and map() to show the names and hours worked of those Employees who earn more than `$30` per hour, sorted by employee name. The output should be: [Bob worked `42.0` hours, Carlos worked `38.75` hours, Tomas worked `28.45` hours, Xavier worked `11.5` hours]
l.filter{it.wage > 30.0}.sortedBy{it.name}.map{"${it.name} worked ${it.hours} hours"}
Write a function called calcBracket() that calculates an employee's tax withholding bracket this way: if the employee's hourly wage is under `15` (in dollars per hour), the withholding bracket is `0`; if the wage is at least `$15` but under `$25`, the bracket is `.15` (that is, `15%`); if the wage is at least `$25` but less than `$35`, the bracket is `.25`; if the wage is at least `$35`, the bracket is `.35`. Return the bracket. (This is not really how tax brackets work, but it's good enough for this exercise!)
fun calcBracket(wage: Double): Double =
if (wage < 15.0) 0.0
else if (wage < 25.0) 0.15
else if (wage < 35.0) 0.25
else 0.35
Write a payroll() function that takes a list of Employees and `f`, a function from Double to Double that returns a list of Pairs in which each Pair contains a String and a Double. For each Employee in the list, return a Pair with that employee's name and their paycheck amount. Calculate the paycheck amount this way: multiply the employee's wage by their hours worked, and multiply the result by `1 - text(their tax withholding bracket)` (for example, if the wage is `$20` and hours worked are `30`, do this: `20 * 30 * (1 - .15)`. Use Kotlin's map() function. (Don't call calcBracket() in this function; It is intended to be passed in through `f`.)
fun payroll(l: List<Employee>, f: (Double) -> Double): List<Pair<String, Double>>=
l.map{ Pair(it.name, (it.wage * it.hours) * (1 - f(it.wage))) }
Call payroll() by passing in calcBracket(). Then use a lambda to calculate the withholding bracket and send the lambda to the payroll() function.
payroll(l, ::calcBracket)
payroll(l, {
when {
it < 15.0 -> 0.0
it < 25.0 -> 0.15
it < 35.0 -> 0.25
else -> 0.35
}
})
Write a function called raise() which takes a list of Employees and a Double and returns a list of Employees like the original but with each having received a raise, with the Double representing the percentage raise. For example, if an employee's wage was `$20` per hour and the Double is `.15` (that is, `15%`), their new wage will be `$23` per hour. Don't change the Employees; create and return a list of new Employee objects with the new wages. Use Kotlin's map() function.
fun raise(l: List<Employee>, d: Double): List<Employee> =
l.map{ Employee(it.name, it.wage + (it.wage * d), it.hours) }
Write a function called formatPaycheck() that takes a Pair<String, Double> and returns a String. formatPaycheck() should use the two parts of the Pair to put together and return a String like this, with the paycheck amount shown to two digits past the decimal point: Pay to the order of Cathy `$359.47`
fun formatPaycheck(p: Pair<String, Double>): String = "Pay to the order of %s $%.2f".format(p.first, p.second)
Use raise() to raise all the employees' pay by `15%`. Then use map() with the payroll() and formatPaycheck() functions to get a list of the paychecks in the format shown above. Print the result. The output should look like this: [Pay to the order of Bob `$1077.79`, Pay to the order of Cathy `$359.47`, Pay to the order of Carlos `$1361.09`, Pay to the order of Tomas `$1056.09`, Pay to the order of Xavier `$297.09`]
println(payroll(raise(l, 0.15), ::calcBracket).map{formatPaycheck(it)})
Consider this Employee class and this list of Employees:
data class Employee(val id: Int, val name: String, val wage: Double, val hours: Double)
Write a function fireEmployee(), which takes a list of Employees and an id number and returns a list that consists of all the original employees without any that have that id. Use filter().
fun fireEmployee(l: List<Employee>, id: Int): List<Employee> = l.filter{ it.id != id }
Revise the function fireEmployee() to take a list of Employees and a function `f` and return a list that consists of all the original employees that don't satisfy `f`. Pass `f` to filter().
fun fireEmployee(l: List<Employee>, f: (Employee) -> Boolean): List<Employee> = l.filter{ !f(it) }
Revise the function fireEmployee() to use a tail-recursive helper function instead of filter().
fun fireEmployee(l: List<Employee>, f: (Employee) -> Boolean): List<Employee> {
tailrec fun helper(n: Int, acc: List<Employee>): List<Employee> =
when {
n >= l.size -> acc
!f(l[n]) -> helper(n+1, acc + listOf(l[n]))
else -> helper(n+1, acc)
}
return helper(0, emptyList())
}
Write a function myF() that takes a String and a function (Char) -> Boolean and uses a tail-recursive inner function to find and return the number of Chars in the String for which the function returned true.
fun myF(s: String, f: (Char) -> Boolean): Int {
tailrec fun helper(s: String, f: (Char) -> Boolean, acc: Int): Int =
if (s.length == 0) acc
else if (f(s[0])) helper(s.drop(1), f, acc+1)
else helper(s.drop(1), f, acc)
return helper(s, f, 0)
}
Generics
This naturally leads us to the concept of subtypes and supertypes. Suppose we have two types, `A` and `B`. Type `B` is a subtype of type `A` if you can use type `B` whenever type `A` is required. For example, Int is a subtype of Number; whenever the code expects a Number, we can pass an Int because technically, an Int is a Number.
To be a little more precise, in order for a type to be a true subtype (i.e., in order to fit the actual definition of what it means to be a subtype), we must be able to replace the supertype with the subtype without causing any errors. This means that:
- A subtype must accept all argument types that the supertype can accept
- A subtype must not return a result type that the supertype won't return
(When I say subtype and supertype here, I mean their functions.)
(The following illustrations are adapted from https://typealias.com/guides/illustrated-guide-covariance-contravariance/. Most of the information in this section is also from that website.)
For example, suppose we had a supertype with a function that takes in a shape and returns a color. It only accepts one square or one circle and returns only green or blue.
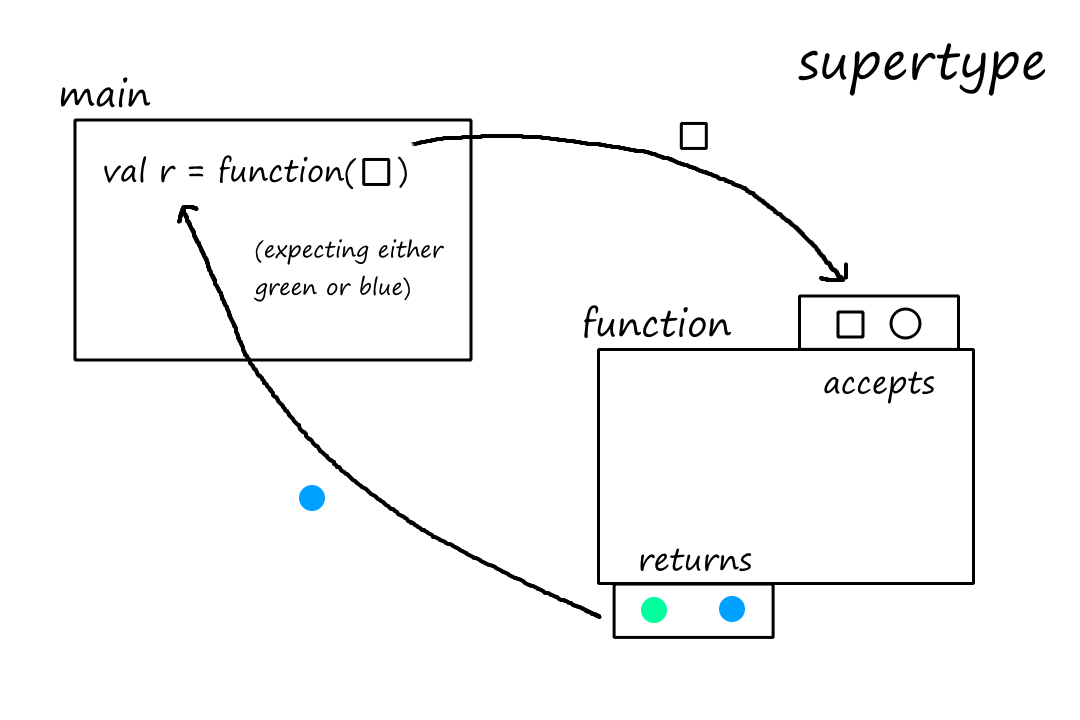
In order for a type to be a true subtype of the supertype, we have to be able to replace the supertype with the subtype without causing errors. The first rule says that "a subtype must accept all argument types that the supertype can accept". Let's see what happens if we don't follow that rule, i.e., the subtype does not accept all argument types that the supertype can accept.
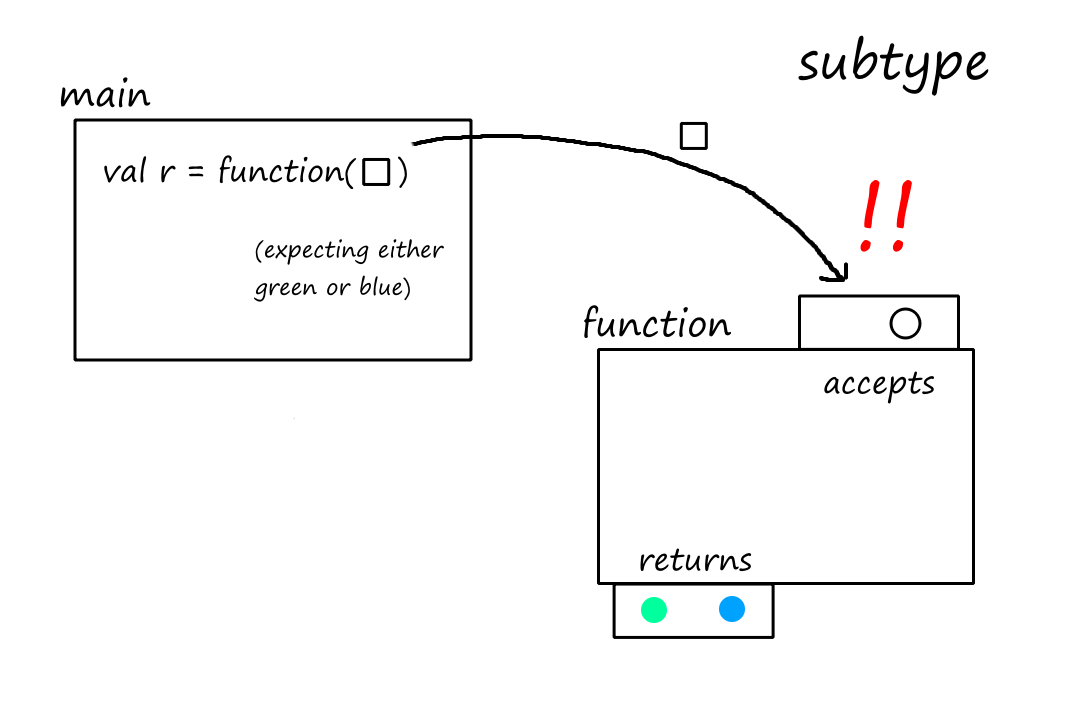
In this case, the subtype only accepts circles. The supertype accepted squares, and the function call in main was expecting the code to work with passing in a square. But when we replaced the supertype with the subtype, the code broke. So the subtype is not a true subtype.
Let's look at the second rule: "a subtype must not return a result type that the supertype won't return". Again, we'll see what happens when we don't follow that rule, i.e., the subtype does return a type that the supertype doesn't return.
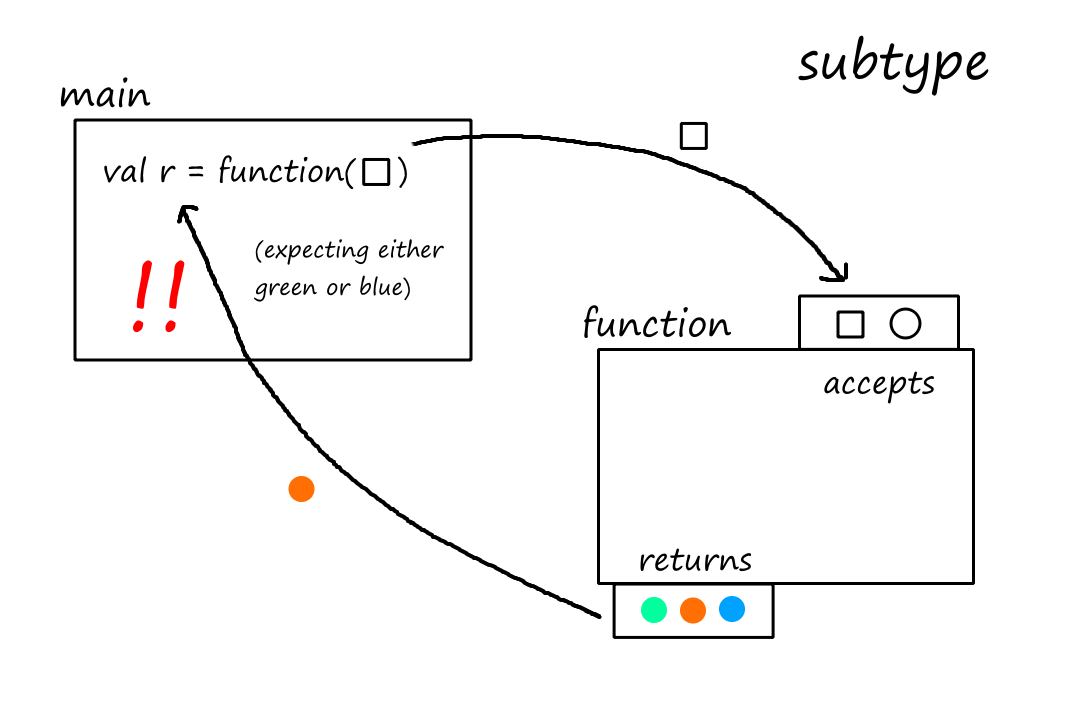
This time, the subtype can also return orange. The supertype only returned green or blue, and the function call in main was expecting only green or blue, not orange! So the subtype is not a true subtype.
Now, this doesn't mean that if we want to create true subtypes, we have to create carbon copies of the supertype. (If this was the case, there wouldn't really be a point in creating subtypes in the first place.) Subtypes can be a little bit more flexible and still be a true subtype.
Contravariance
Let's change the first rule from "a subtype must accept all argument types that the supertype can accept" to "a subtype must accept at least the argument types that the supertype can accept". Under this new rule, the subtype still technically accepts "all" the argument types that the supertype can accept, just a little bit more.
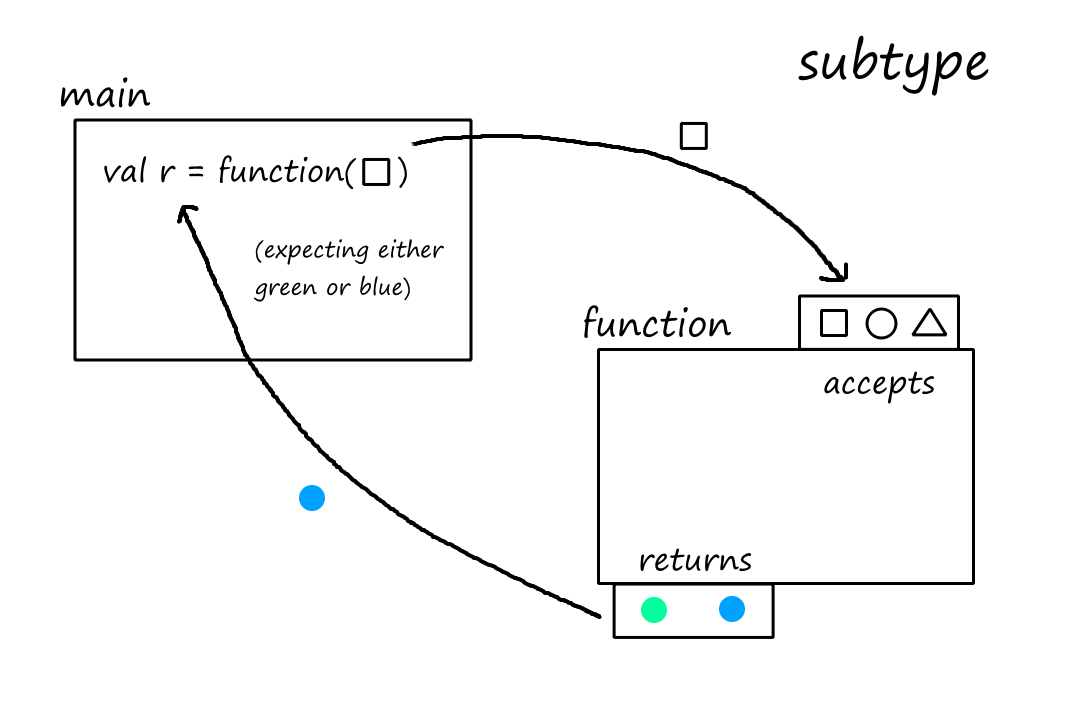
And this is fine. Remember that the definition of a true subtype is that we can replace the supertype without causing any errors. As far as main is concerned, it is still interacting with the supertype, so main will continue to pass only squares and circles.
This is called contravariance because as the type gets more specific ("narrower"), the type of arguments that can be accepted get more general ("expands"). They go in opposite directions, hence the "contra".
Covariance
Let's change the second rule from "a subtype must not return a result type that the supertype won't return" to "a subtype must return at most the same result types that the supertype returns". Under this new rule, the subtype can choose to exclude something the supertype returns.
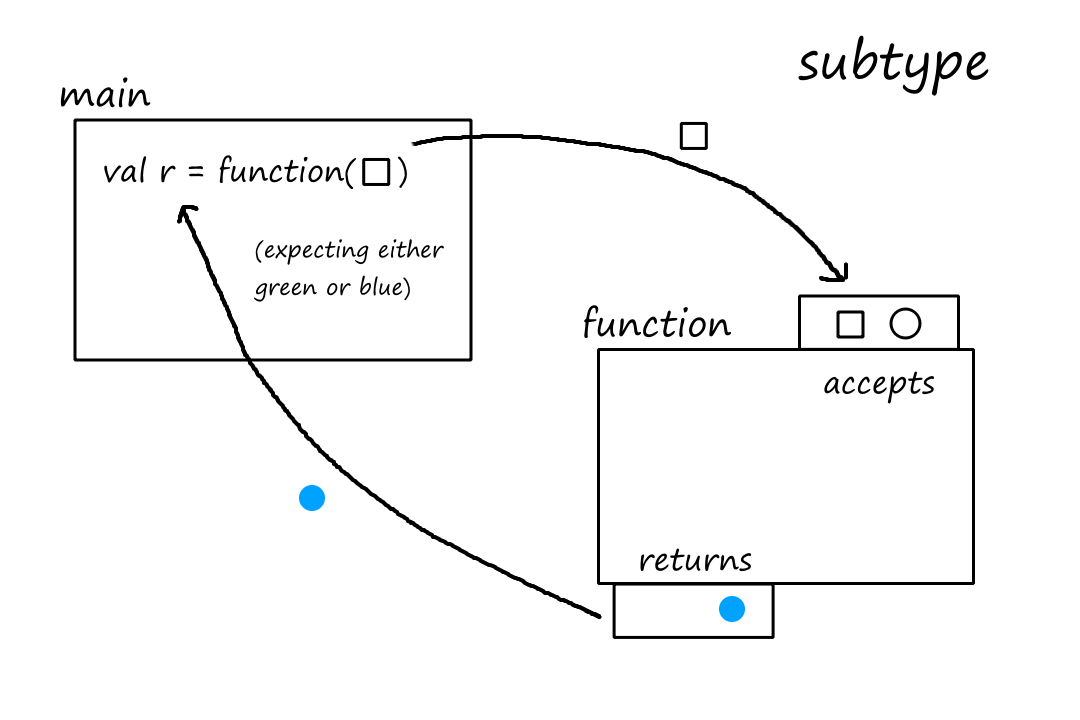
Again, this is fine because main is expecting either green or blue.
This is called covariance because as the type gets more specific ("narrower"), the return types also get narrower. They go in the same direction, hence the "co".
New Rules!
So now the two rules for a subtype to be a true subtype are:
- A subtype must accept at least the argument types that the supertype can accept
- A subtype must return at most the same result types that the supertype returns
Variance
Variance is, at a very basic level, looking at if something is covariant or contravariant (or invariant, which we'll see right now).
Since a String is a subtype of Any, is a MutableList of Strings a subtype of a MutableList of Anys?
fun add42ToList(list: MutableList<Any>) {
list.add(42)
}
fun main() {
val strings = mutableListOf("abc")
add42ToList(strings)
println(strings.maxBy{ it.length })
}
This doesn't compile, but if it did, there would be a runtime error when calling the length method on an Int. Since we can't replace a MutableList of Anys with a MutableList of Strings, a MutableList of Strings is not a subtype of a MutableList of Anys.
In fact, MutableList is invariant on the type parameter. That is, for any two different types `A` and `B`, MutableList<A> isn't a subtype or a supertype of MutableList<B>.
Generic Variance (Covariance)
Suppose we have a generic class Group<T>. If `A` is a subtype of `B` and Group<A> is a subtype of Group<B>, then the Group class is covariant. The subtyping is preserved, hence the "co".
Now let's suppose that Group has two functions: insert() and fetch(). (Let's also suppose it's an interface instead of a class just so it compiles.)
interface Group<T> {
fun insert(item: T): Unit
fun fetch(): T
}
Let's say we have two classes: an Animal class and a Dog class, where Dog is a subtype of Animal. If we want to make the Group class covariant, then Group<Dog> should be a subtype of Group<Animal>. Let's see what we have so far and see if it's possible.
Group<Animal> {
fun insert(item: Animal): Unit
fun fetch(): Animal
}
Group<Dog> {
fun insert(item: Dog): Unit
fun fetch(): Dog
}
The way things are right now, Group<Dog> is not a subtype of Group<Animal> because Group<Dog> does not accept at least the same argument types that Group<Animal> accepts. For example, we could pass in a Cat to Group<Animal>'s insert() function, but we can't pass a Cat to Group<Dog>'s insert() function.
Note that Group<Dog> already returns at most the same result types that Group<Animal> returns, so that rule is not being broken.
Kotlin Variance Annotation (out)
For now, let's remove the insert() function so that the first rule is not broken.
interface Group<T> {
fun fetch(): T
}
Group<Animal> {
fun fetch(): Animal
}
Group<Dog> {
fun fetch(): Dog
}
Since both subtyping rules are not being broken anymore, Group<Dog> is a subtype of Group<Animal>. To tell Kotlin that we want to treat Group<Dog> as a subtype of Group<Animal>, we use the out annotation:
interface Group<out T> {
fun fetch(): T
}
It's called "out" because the type is used only as an output.
If we were to add the insert() function back, we would get a compile-time error: "Type parameter T is declared as 'out' but occurs in 'in' position in type T".
interface Group<out T> {
fun insert(item: T): Unit
fun fetch(): T
}
And as we just saw, this is because this violates the first subtype rule about accepting at least all of the supertype's arguments.
(Note that adding the out modifier prevents us from creating any functions that take the type as a parameter, and therefore, breaking the above rule.)
Generic Variance (Contravariance)
On the other hand, if `A` is a subtype of `B` and Group<B> is a subtype of Group<A>, then the Group class is contravariant. The subtyping is reversed, hence the "contra".
If we want to make the Group class contravariant, then Group<Animal> should be a subtype of Group<Dog>. Let's see what we have so far and see if it's possible.
Group<Dog> {
fun insert(item: Dog): Unit
fun fetch(): Dog
}
Group<Animal> {
fun insert(item: Animal): Unit
fun fetch(): Animal
}
Well, Group<Animal> does accept at least the same argument types as Group<Dog> does, so that rule is fine. However, Group<Animal> can return more types than Group<Dog> can. So the second rule is being broken!
Kotlin Variance Annotation (in)
Similarly to before, let's remove the fetch() function so that the second subtyping rule is not broken.
interface Group<T> {
fun insert(item: T): Unit
}
Group<Dog> {
fun insert(item: Dog): Unit
}
Group<Animal> {
fun insert(item: Animal): Unit
}
Now both subtyping rules are not being broken anymore, so Group<Animal> is a subtype of Group<Dog>. To tell Kotlin that we want to treat Group<Animal> as a subtype of Group<Dog>, we use the in annotation:
interface Group<in T> {
fun insert(item: T): Unit
}
It's called "in" because the type is used only as an input.
If we were to add the fetch() function back, we would get a compile-time error: "Type parameter T is declared as 'in' but occurs in 'out' position in type T".
interface Group<in T> {
fun insert(item: T): Unit
fun fetch(): T
}
And as we just saw, this is because this violates the second subtype rule about returning at most all of the supertype's arguments.
(Note that adding the in modifier prevents us from creating any functions that return the type, and therefore, breaking the above rule.)
Another Example With Squares
Out
Suppose we had a Square class that can hold an item and return it:
class Square<out T>(private val item: T) {
fun getItem(): T = item
}
Let's look at what we are allowed to do with this Square. This first line is nothing special; we can assign a Square<Int> to a variable of type Square<Int>:
fun main() {
val intSquare: Square<Int> = Square(1)
}
The next line is where it starts to get interesting. We can assign a Square<Int> to a variable of type Square<Number>:
fun main() {
val intSquare: Square<Int> = Square(1)
val numSquare: Square<Number> = intSquare
}
This is okay because the Square class is covariant (because of the out modifier); so Square<Int> is a subtype of Square<Number>.
Square<Number> can also call getItem() without any errors because the subtype (Square<Int>) does not return any values that the supertype (Square<Number>) doesn't return.
fun main() {
val intSquare: Square<Int> = Square(1)
val numSquare: Square<Number> = intSquare
println(numSquare.getItem())
}
In
Suppose we had a different Square class that can hold an item and compare it with another item:
class Square<in T>(private val item: T) {
fun compareValues(otherItem: T): Boolean = item == otherItem
}
Similar to what we did above, we can assign a Square<Number> to a variable of type Square<Int> because Square<Number> is a subtype of Square<Int> (because of the in modifier):
fun main() {
val numSquare: Square<Number> = Square(1)
val intSquare: Square<Int> = numSquare
}
For the same reason, we can also assign a Square<Number> to a variable of type Square<Double>:
fun main() {
val numSquare: Square<Number> = Square(1)
val intSquare: Square<Int> = numSquare
val doubleSquare: Square<Double> = numSquare
}
And Square<Double> can call compareValues() because the subtype (Square<Number>) does accept at least the same argument types that the supertype (Square<Double>) does.
fun main() {
val numSquare: Square<Number> = Square(1)
val intSquare: Square<Int> = numSquare
val doubleSquare: Square<Double> = numSquare
println(doubleSquare.compareValues(2.2))
}
Abstract Data Types
An abstract data type is a basic (abstract) description of a data structure. It specifies the type of data stored, the operations supported, and the types of parameters of the operations. Most importantly, an ADT specifies what each operation does, but not how the operation does it.
For example, a list is an abstract data type. We can say that the list holds Ints and that the operations we can perform on a list are to insert into and delete from the list. However, we are not specifying how the values of the list are stored, and we are not specifying how the insert and delete operations are implemented.
On the other hand, a linked list is a data structure. Each element in the list is a node that contains a value and a pointer to the next node (we're specifying how the values of the list are stored). Insertion and deletion of elements are performed by following each node's next pointer to traverse the linked list until the desired node is reached (we're specifying how the operations are implemented).
The set of behaviors supported by the ADT is referred to as its public interface.
Functional Data Structures
Suppose we wanted to design an interface to compute expressions like `(1+2)+4`.
interface Expr
class Num(val value: Int): Expr
class Sum(val left: Expr, val right: Expr): Expr
And to use this to represent `(1+2)+4`, it would look like this:
Sum(Sum(Num(1), Num(2)), Num(4))
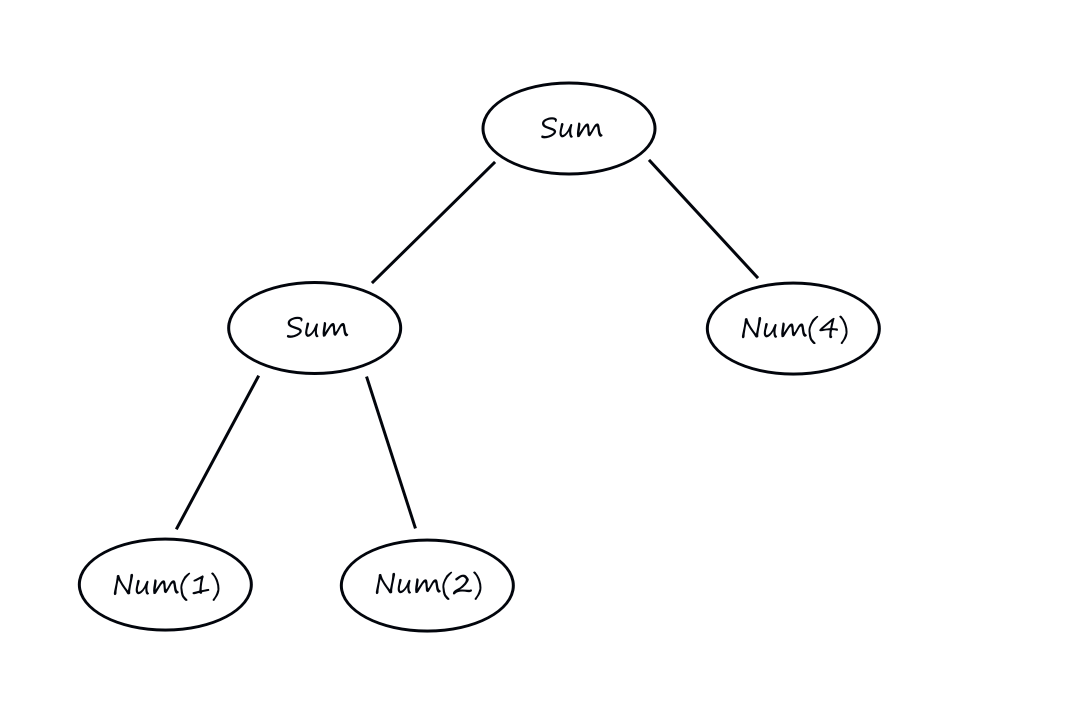
To actually evaluate the result of the expression, we can write a function:
fun eval(e: Expr): Int =
when(e) {
is Num -> e.value
is Sum -> eval(e.right) + eval(e.left)
else -> throw IllegalArgumentException("Unknown expression")
}
And to call the function:
fun main() {
println(eval(Sum(Sum(Num(1), Num(2)), Num(4))))
}
We need to have the else part in the when expression because if new subclasses of Expr are created, the when expression needs to know how to handle those.
However, we may not want other people to create new subclasses of Expr (and typing that else part can be a little annoying). In Kotlin, we can create a sealed class so that only the classes that are compiled with Expr can be subclasses. We do this by adding sealed in front of the class/interface.
sealed interface Expr
class Num(val value: Int): Expr
class Sum(val left: Expr, val right: Expr): Expr
fun eval(e: Expr): Int =
when(e) {
is Num -> e.value
is Sum -> eval(e.right) + eval(e.left)
}
Recall that in functional programming, data is not modified. This means that functional data structures must be immutable. So we can't use arrays, (imperative) linked lists, etc.
Notice in the Expr example, when evaluating the result of the expression, we never changed any values. We sorta "passed it up the chain".
In principle, if we want to perform insert or delete operations on functional data structures, we make a new copy based on the inputs but with the desired changes, leaving the inputs unmodified.
Singly Linked List
Linked lists are a common functional data structure because
- they're persistent
- prepending (producing a new list) is `O(1)`
- building an `n`-element list is `O(n)`
We can see why by comparing it to an array list, both the mutable and immutable versions.
For the mutable array list:
- prepending is `O(n)` because everything has to be shifted over
- while appending is usually `O(1)`, it can be `O(n)` if the array list is full (we have to create a bigger array list to add the new element)
- in the worst case, it's `O(n^2)` (think about starting with an array list of size `1` and appending)
For the immutable array list:
- a new array has to be created for each insert/delete operation, so building a new list is `O(n)` and doing this for `n` operations makes it `O(n^2)`
Here's how a functional singly linked list could be implemented:
sealed class MyList<out A>
object MyNil: MyList<Nothing>()
data class MyCons<out A>(val head: A, val tail: MyList<A>): MyList<A>()
The object and the data class represent the two possibilities that a list can be. The MyNil object represents an empty list and MyCons represents a non-empty list. (Cons is short for "construct".) If there is only one item in the list, the tail is MyNil.
In Kotlin, Nothing is a subtype of every type. So by using the out annotation, MyList<Nothing> is a subtype of lists of any other types.
This is what it looks like to create a list:
val l: MyList<Int> = MyCons(1, MyCons(2, MyCons(3, MyNil)))
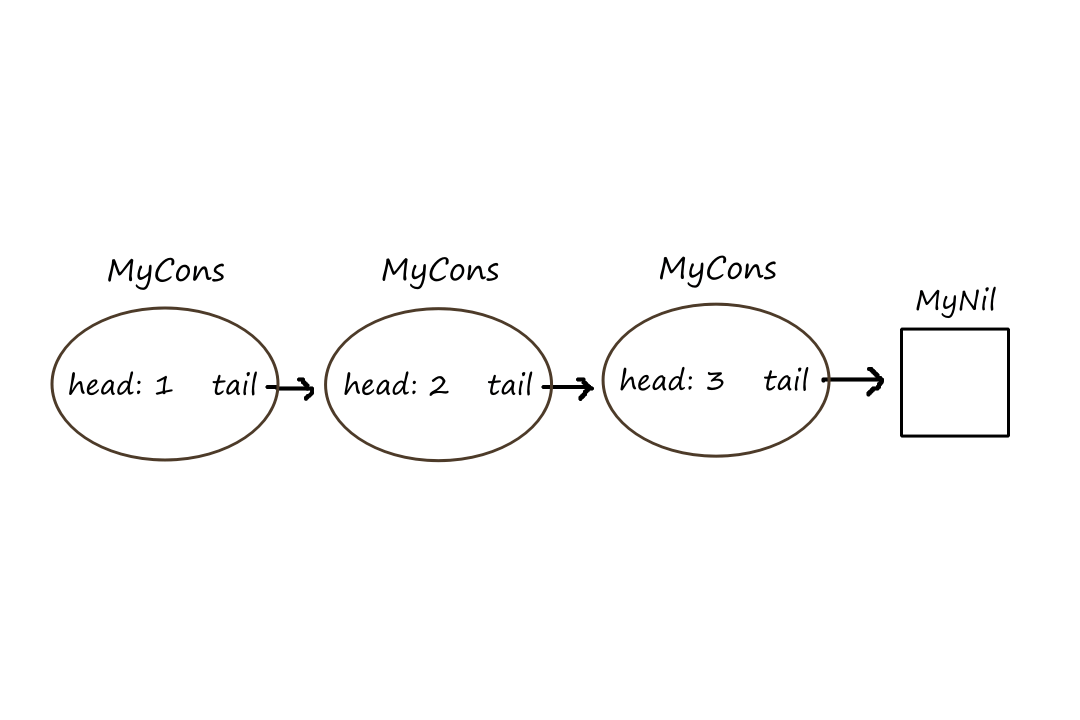
It is a little bit complicated to create lists this way. We can make it easier by creating a function similar to Kotlin's listOf() function.
sealed class MyList<out A> {
companion object {
fun <A> of(vararg aa: A): MyList<A> {
val tail = aa.sliceArray(1 until aa.size)
return if (aa.isEmpty()) MyNil else MyCons(aa[0], of(*tail))
}
}
}
fun main() {
val l = MyList.of(1, 4, 22, -30, 1)
}
A companion object is a singleton object whose properties and functions are not tied to an instance of the class. This means that we can call a companion object's functions without having to create an instance of the class first. Basically, think of static in Java.
vararg specifies that the parameter will be an array*, where the number of elements can vary depending on how many arguments are passed. This makes the of() function a variadic function, meaning that it can accept zero or more arguments.
The * in MyCons(aa[0], of(*tail)) is the "spread operator", which passes the contents of an array as an argument to a function.
*Wait a minute, didn't I say arrays weren't allowed in functional programming? In this case, the array isn't being changed (only consumed) so no data is being modified.
In addition (😏), we can define functions to compute the sum (😏) and product of all the elements in our list.
fun sum(ints: MyList<Int>): Int =
when (ints) {
is MyNil -> 0
is MyCons -> ints.head + sum(ints.tail)
}
fun product(doubles: MyList<Double>): Double =
when (doubles) {
is MyNil -> 1.0
is MyCons ->
if (doubles.head == 0.0) 0.0
else doubles.head * product(doubles.tail)
}
fun main() {
val ints = MyList.of(1, 4, 22, -30, 1)
println(MyList.sum(ints))
val doubles = MyList.of(1.0, 4.0, 22.0, -30.0, 1.0)
println(MyList.product(doubles))
}
Data Sharing
Now for the million-dollar question: since MyList is a functional data structure, how do we add and remove elements from MyList?
Let's say we wanted to add an element to the front of a list. In this case, we return a new list with the element we want to add as the head and the existing list as the tail:
fun <A> prepend(l: MyList<A>, e: A): MyList<A> = MyCons(e, l)
If we want to remove an element from the front of a list, we return the list's tail:
fun <A> premove(l: MyList<A>): MyList<A> =
when (l) {
is MyCons -> l.tail
is MyNil -> MyNil
}
To insert and remove at any index:
fun <A> insertAt(l: MyList<A>, index: Int, e: A): MyList<A> =
when (l) {
is MyCons ->
if (index == 0) MyCons(e, l)
else MyCons(l.head, insertAt(l.tail, index - 1, e))
is MyNil -> MyNil
}
fun <A> removeAt(l: MyList<A>, index: Int): MyList<A> =
when (l) {
is MyCons ->
if (index == 0) l.tail
else MyCons(l.head, removeAt(l.tail, index - 1))
is MyNil -> MyNil
}
Basically, we recursively traverse the list until we reach the desired index.
A (perhaps) subtle thing to note here is that we're not actually creating new lists and copying over the values from the existing list to the new list; We're reusing the reference to the existing list. This is called data sharing.
Functional Data Structures Practice Problems
Write a modifyListHead() method to get a new list that is identical to the old list except with a different first element. This function accepts an input list and an input variable, and returns a list where the head of the input list has been replaced with the input variable. For example, calling modifyListHead(exList, 10) where exList = (1,2,3,4,5) would return (10,2,3,4,5).
fun <A> modifyListHead(l: MyList<A>, v: A): MyList<A> =
when (l) {
is MyCons -> MyCons(v, l.tail)
is MyNil -> MyNil
}
Write a dropFromList() method to get a new list with the first `n` elements from the list. This function accepts an input list and a value for `n`, and returns a list with the first `n` elements dropped. For example, calling dropFromList(exList,2) where exList = (1, 7, 3, 42, 11) would return (3,42,11).
fun <A> dropFromList(l: MyList<A>, n: Int): MyList<A> =
when (l) {
is MyCons ->
if (n == 0) l
else dropFromList(l.tail, n-1)
is MyNil -> MyNil
}
Write a sumTwoLists() method that accepts two lists of Ints and adds corresponding elements of each list, continuing until the shorter list is exhausted. This function accepts two input lists and returns their sum as illustrated: for two input lists `(1,2,3)` and `(4,5,6)`, this function returns `(5,7,9)`.
fun sumTwoLists(l1: MyList<Int>, l2: MyList<Int>): MyList<Int> =
if (l1 is MyNil || l2 is MyNil) MyNil
else if (l1 is MyCons && l2 is MyCons) MyCons(l1.head + l2.head, sumTwoLists(l1.tail, l2.tail))
else MyNil
Error Handling
A quick note about semantics. An error is a problem that is caused by something out of the application's control. Examples are out-of-memory errors and stack overflows. An exception is an event that an application can catch. These are the errors from try/catch blocks.
This section is really going over "exceptions", not "errors". But I'll use them interchangeably.
As mentioned in the "Side Effects" section, throwing an exception is not functional programming. This is because throwing an exception interrupts the normal flow of the program, so now whatever was in charge of running the application has to change what it was expecting (normal execution) and deal with it.
Exceptions Break Referential Transparency
Recall that referential transparency is the ability to replace an expression with a constant value if the expression will always evaluate to the same value.
Throwing exceptions break referential transparency. Consider this function:
fun idkWhatThisDoes(): Int {
val y: Int = throw Exception("boom")
return try {
val x = 42 + 5
x + y
} catch (e: Exception) {
43
}
}
If we call this function, we will get an error message at runtime: 'Exception in thread "main" java.lang.Exception: boom'.
If this function was referentially transparent, we should be able to replace y with its value without changing the result of the function call.
fun idkWhatThisDoes(): Int {
return try {
val x = 42 + 5
x + (throw Exception("boom")) as Int
} catch (e: Exception) {
43
}
}
However, if we call this function, the exception will be caught and `43` will be printed out.
The meaning/value of a referentially transparent expression does not depend on context and can be reasoned about locally. While the meaning/value of a non-referentially transparent expression is context dependent and needs more global reasoning.
For example, the meaning of the expression throw Exception("boom") takes on different meanings depending on which try block it's nested inside.
Note that this does not mean that try/catch blocks cannot be used in functional programming. We can still use try/catch blocks; We just can't throw exceptions.
Dealing with Exceptions
Exceptions can't be avoided, but if they can't be thrown, then how do we deal with them?
Consider this function where we might want to handle the exception of dividing by `0`:
fun mean(xs: List<Double>): Double =
if (xs.isEmpty()) throw ArithmeticException("cannot get mean of empty list")
else xs.sum() / xs.size
This mean function is a partial function. That is, it doesn't always produce an output for any input values. In this case, it doesn't return a value for an empty list.
Approach 1: Sentinel Value
Instead of throwing the exception, we can return some dummy value, like null, `-1`, or Double.NaN.
fun mean(xs: List<Double>): Double =
if (xs.isEmpty()) Double.NaN
else xs.sum() / xs.size
Drawbacks of Using a Sentinel Value
The caller may forget to check if the sentinel value was returned and treat it as a normal value, resulting in logic errors.
If using polymorphic code, there may not be a sentinel value of the correct type for certain output types. For example, if the function is taking in a list of As, we can't invent a value of type A.
Approach 2: Supplied Default Value
Instead of us deciding what to return, we can pass the decision over to the caller.
fun mean(xs: List<Double>, onEmpty: Double): Double =
if (xs.isEmpty()) onEmpty
else xs.sum() / xs.size
Approach 3: New Classes (Preferred Approach)
Instead of returning predefined values, we can create our own values to represent errors (and successes).
Option
sealed class Option<out A>
data class Some<out A>(val get: A): Option<A>()
object None: Option<Nothing>()
When a function is defined for an input, a Some object is returned. When a function is undefined for an input, the None object is returned.
Applying this to our mean function:
fun mean(xs: List<Double>): Option<Double> =
if (xs.isEmpty()) None
else Some(xs.sum() / xs.size)
Drawbacks of Using Option
An Option doesn't tell us anything about what went wrong or why the error occurred.
Either
sealed class Either<out E, out A>
data class Left<out E>(val value: E): Either<E, Nothing>()
data class Right<out A>(val value: A): Either<Nothing, A>()
For successful function calls, we return a Right object (because it's right!). For errors, we return a Left object (because it's not right!).
The Either data type has two values. The left (type E) is the value representing an error and the right (type A) is the value representing the result of a function.
Applying this to our mean function:
fun mean(xs: List<Double>): Either<String, Double> =
if (xs.isEmpty()) Left("cannot get mean of empty list")
else Right(xs.sum() / xs.size)
Error Handling Practice Problems
Write the function productE(), which takes a list of Ints and, if the list is not empty, returns its product (list[0] * list[1] ...* list[n-1]), otherwise returns a String, such as "error: trying to find product of an empty list!". Use Either and calculate the product using a tail-recursive inner helper function. The tail-recursive function can just return an Int, as long as the base case is that the length of the list is `1`.
fun productE(l: List<Int>): Either<String, Int> {
tailrec fun helper(l: List<Int>, acc: Int): Int =
if (l.size == 1) l[0] * acc
else helper(l.drop(1), l[0] * acc)
return (
if (l.size == 0) Left("error: trying to find product of an empty list!")
else Right(helper(l, 1))
)
}
Write a data class Person with a name and age field as String and Int, respectively. Write a freestanding createPerson() function that accepts name and age values as arguments. If the age is < `0`, createPerson() returns an error message using Either stating that the age is invalid. Otherwise, it returns an instance of Person with the user-specified name and age.
data class Person(val name: String, val age: Int)
fun createPerson(name: String, age: Int): Either<String, Person> =
if (age < 0) Left("invalid age")
else Right(Person(name, age))
Write the function safeGetByIndex(), which takes a List<A> and an Int `n`. If `n` is a valid index in the list, the function returns list[`n`]. Otherwise, it returns an error message like "Invalid index!".
fun <A> safeGetByIndex(l: List<A>, n: Int): Either<String, A> =
if (n < 0 || n >= l.size) Left("Invalid index!")
else Right(l[n])
Write another version of safeGetByIndex() that uses a try/catch. If no exception occurs, return list[`n`]. Otherwise return the error message from the exception.
fun <A> safeGetByIndex(l: List<A>, n: Int): Either<Exception, A> =
try {
Right(l[n])
} catch (e: Exception) {
Left(e)
}
Strictness and Laziness
Strict evaluation means that expressions are evaluated and bound to variables when they are defined. Lazy evaluation means that expressions are evaluated only when they are used. Note that this means a variable can be assigned an expression, but that expression may not necessarily be evaluated. I promise this makes more sense with examples.
Stepping away from Kotlin for just a second, consider this line of code in some language:
print length([2+1, 3*2, 1/0, 5-4])
Under strict evaluation, this results in an error because the 1/0 part will be evaluated right away. But under lazy evaluation, this line of code will print `4` since the values of the elements in the list aren't needed for the length() function.
In fact, we're more familiar with lazy evaluation than we might think. The short-circuiting logic in the && and || operators are examples of lazy evaluation.
if(3 == 4 && a < b) // a < b is not evaluated
if(3 == 3 || a < b) // a < b is not evaluated
As we can see above, the if control construct can be non-strict.
The if/else statement is a little more interesting. The if part is strict since it will always evaluate the condition to know which branch to take. But as a whole, the two branches are non-strict since only one branch will ever be evaluated.
Lazy Behavior With Functions
Functions can be non-strict where they accept arguments without evaluating them. This is done by having the functions take functions (rather than values) as arguments and calling the functions only when needed.
This is an example of a non-strict function:
fun <A> lazyIf(cond: Boolean, onTrue: () -> A, onFalse: () -> A): A =
if (cond) onTrue() else onFalse()
To verify that this is actually a non-strict function, we can take advantage of print statements:
fun main() {
var a = 21
val y = lazyIf((a < 22), { println("a") }, { println("b") })
a = 22
val z = lazyIf((a < 22), { println("a") }, { println("b") })
}
What is printed is a and b (each only once). If this wasn't a non-strict function, then each of a and b would've been printed twice since the arguments would have been evaluated right away.
The unevaluated form of an expression is called a "thunk". More precisely, a thunk is a function wrapper around the expression we want to delay the evaluation of.
Lazy Behavior With Ranges
Consider this code:
val r: LongRange = 1..1000000000000
fun main() {
println(r)
println(r.take(5))
println(r.take(5000000))
}
The output of the first println() is `1...1000000000000`. The output of the second println() is `[1, 2, 3, 4, 5]`. But the third println() fails because there should not be enough memory to store `5,000,000` numbers.
Notice that there was not enough memory for `5,000,000` numbers, but running val r: LongRange = 1..1000000000000 was fine. This shows that the range isn't evaluated right away; only when it's used.
Lazy Initialization in Kotlin
Lazy initialization is the tactic of delaying the creation of an object, calculation of a value, or execution of an expensive process until the first time it is needed. Kotlin has a built-in function called lazy to accomplish this.
First, we'll look at greedy initialization.
fun maybeTwice(b: Boolean, i: () -> Int) = if (b) i() + i() else 0
fun main() {
val x = maybeTwice(true, { println("hi"); 1 + 41 })
}
Here, we're passing in a function that prints "hi" and evaluates to `42`. maybeTwice() takes in that function and calls it twice, which means that "hi" will be printed twice.
Calling the function twice should result in the same thing. So why should we spend time running the function a second time if we already know its value? This is where lazy comes in.
fun maybeTwiceLazy(b: Boolean, i: () -> Int) {
val j: Int by lazy(i)
if (b) j + j else 0
}
The first time j is referenced, it calls the function i(). The value of j is then cached so that when j is called the second time, it refers to the cached value instead of running i() again. And we can verify this with the same main() code above to see that "hi" is printed only once.
Laziness Practice Problems
Write a lazyCalculator() function that accepts input parameters:
- Two numbers
aandb - A boolean condition
- A function,
doFirst, that does a computation specified by a caller - A function,
doSecond, that does a computation specified by a caller
If the condition is true, doFirst() is called, otherwise doSecond() is called. doFirst() and doSecond() are not to be evaluated unless they are called, i.e., they should be lazy evaluated. As one example, doFirst() can be the sum of the two numbers and doSecond() can be the difference of the two numbers.
fun lazyCalculator(a: Int, b: Int, cond: Boolean, doFirst: (Int, Int) -> Int, doSecond: (Int, Int) -> Int): Int {
val x: Int by lazy({ doFirst(a, b) })
val y: Int by lazy({ doSecond(a, b) })
return if (cond) x else y
}
Consider this code, which crashes with a divide by zero error as soon as you build the list:
fun divide(n1: Int, n2: Int): Int = n1/n2
fun multiply(n1: Int, n2: Int): Int = n1*n2
fun expo(n1: Int, n2: Int): Int = Math.pow(n1.toDouble(), n2.toDouble()).toInt()
fun main() {
val n1: Int = 7
val n2: Int = 0
val l1 = listOf(multiply(n1, n2), divide(n1, n2), expo(n1, n2))
}
Create a List with these same operations, but without evaluating them. Hint: if you print the list, you will see something like this: [() -> kotlin.Int, () -> kotlin.Int, () -> kotlin.Int]
val l1 = listOf({ multiply(n1, n2) }, { divide(n1, n2) }, { expo(n1, n2) })
Lazy Lists
From here, we'll continue by looking at a problem and building up the pieces towards a solution.
Consider this line of code:
listOf(1, 2, 3, 4).map{ it + 10 }.filter{ it % 2 == 0 }.map{ it * 3 }
We start with a list of `[1,2,3,4]`, add `10` to each number, get only the even numbers, and multiply those even numbers by `3`. Under the hood, multiple lists are being created at each step.
map{ it + 10 }creates an intermediate list (`[11,12,13,14]`)filter{ it % 2 == 0 }creates an intermediate list (`[12,14]`)map{ it * 3 }creates the final list (`[36,42]`)
The problem with this is that it's inefficient to create intermediate lists that are used only as inputs to the next step and never used again. We can run into memory issues if the intermediate lists are very large.
We can avoid this problem of creating temporary data structures by using laziness to combine sequences of transformations into a single pass.
Imagine that we had a deck of cards and we were asked (by a magician I guess) to remove all the odd-numbered cards and then flip over all the queens. Naturally, we'd go through the deck one card at a time and check if the current card is odd or a queen. That way, we'd only need to go through the deck once.
It would be inefficient to go through the deck and pick out all the odd numbers first, then go through what's left of the deck and flip over all the queens. This is what's happening with the code above.
Stream
We'll create a Stream to store the elements in a way that is convenient to perform transformations on them.
sealed class Stream<out A>
data class Cons<out A> (
val head: () -> A,
val tail: () -> Stream<A>
): Stream<A>()
object Empty: Stream<Nothing>()
This is very similar to the implemention of a singly linked list (see the "Singly Linked List" section). The only difference is that the Cons in MyList takes input parameters that are already evaluated, while the Cons in Stream takes input parameters that are thunks instead of strict values.
Since the head is a function, we need a way to evaluate the function when we need its value. We'll do this with an extension function called headOption():
fun <A> Stream<A>.headOption(): Option<A> =
when (this) {
is Empty -> None
is Cons -> Some(head())
}
Recall that back in the "Dealing with Exceptions" section, we created an Option class to represent errors and successes. Here is the implementation again:
sealed class Option<out A>
data class Some<out A>(val get: A): Option<A>()
object None: Option<Nothing>()
Here, we'll add an extension function called getOrElse() that tries to get the value of an Option, or the user-provided default value if there is no value.
fun <A> Option<A>.getOrElse(default: () -> A): A =
when(this) {
is Some -> this.get
is None -> default()
}
We're using an Option to handle the case of returning the head of an empty list.
And we'll need a way to create a Stream with elements:
sealed class Stream<out A> {
companion object {
fun <A> of(vararg xs: A): Stream<A> =
if (xs.isEmpty()) empty()
else cons({ xs[0] }, { of(*xs.sliceArray(1 until xs.size)) })
fun <A> empty(): Stream<A> = Empty
fun <A> cons(hd: () -> A, tl: () -> Stream<A>): Stream<A> {
val head: A by lazy(hd)
val tail: Stream<A> by lazy(tl)
return Cons({ head }, { tail })
}
}
}
{ xs[0] } is shorthand for creating a function that takes no arguments and returns xs[0].
Here's an example of creating a Stream:
fun main() {
val s1 = Empty
println(s1)
println(s1.headOption().getOrElse({"No Value Found"}))
val s2 = Stream.of(1, 2, 3, 4, 5)
println(s2)
println(s2.headOption().getOrElse({"No Value Found"}))
}
(Note: this won't work in the Kotlin playground.) And this is the output:
Empty@12edcd21
No Value Found
Cons(head=Function0<A>, tail=Function0<Stream<? extends A>>)
1
We can write a function to check if an element exists in a Stream.
fun exists(p: (A) -> Boolean): Boolean =
when (this) {
is Cons -> p(this.head()) || this.tail().exists(p)
else -> false
}
fun main() {
val x = Stream.of("a", "b", "c", "d")
println(x.exists{ it == "a" })
println(x.exists{ it == "e" })
}
One thing to note here is that if the function being passed to exists() returns true for an element, then any elements after it are never evaluated. #laziness
Kotlin's fold() function reduces a collection to a single value by applying an operation to each element in the collection. It takes in two parameters: 1) an initial value for an accumulator and 2) a function that is applied to each element in the list.
fun main() {
val x = listOf(1, 2, 3, 4, 5)
println(x.fold(0, {acc: Int, i: Int -> acc + i }))
}
Now this is where everything starts to come together. Recall that the problem we were trying to solve was to not create intermediate lists for code like this:
listOf(1, 2, 3, 4).map{ it + 10 }.filter{ it % 2 == 0 }.map{ it * 3 }
Referring back to the card analogy, what we would like to do is to look at the list one element at a time, perform all those transformations on that element, and add the result to the final list. We can do this by building off of the idea behind Kotlin's fold() function.
We'll need a custom fold-like function that works with our Stream.
fun <B> foldRight(z: () -> B, f: (A, () -> B) -> B): B =
when (this) {
is Cons -> f(this.head()) { this.tail().foldRight(z, f) }
is Empty -> z()
}
There is another generic parameter B so that the return type does not need to be the same as the type of the items in the Stream.
z() acts as the accumulator and f() is the function that is applied to each element in the Stream.
Here's an example of using foldRight() to find the sum of a Stream of Ints:
fun main() {
val z: Stream<Int> = Stream.of(1, 2, 3, 2, 4, 6)
println(z.foldRight({ 0 }, { a, b -> a + b() }))
}
Here's an example of using foldRight() to implement an exists function:
fun existsUsingFoldRight(p: (A) -> Boolean): Boolean =
foldRight({ false }, { a, b -> p(a) || b() })
fun main() {
val x = Stream.of(1, 2, 3, 4, 5)
println(x.existsUsingFoldRight{ it == 3 })
}
Now, instead of using Kotlin's filter() and map(), we can use foldRight() to write our own versions of filter and map that work with our Stream.
fun <A, B> Stream<A>.map(f: (A) -> B): Stream<B> =
this.foldRight(
{ Stream.empty<B>() },
{ h, t -> Stream.cons({ f(h) }, t) }
)
fun <A> Stream<A>.filter(f: (A) -> Boolean): Stream<A> =
this.foldRight(
{ Stream.empty<A>() },
{ h, t -> if (f(h)) Stream.cons({ h }, t) else t() }
)
To make a Stream easier to see, we'll create a function that converts a Stream to a list:
fun <A> examineStream(s: Stream<A>): List<A> {
tailrec fun helper(s: Stream<A>, acc: List<A>): List<A> =
when (s) {
is Empty -> acc
is Cons -> helper(s.tail(), acc + listOf(s.head()))
}
return helper(s, emptyList<A>())
}
fun main() {
val x = Stream.of(1, 2, 3, 4, 5)
println(examineStream(x.map{ it + 3 }))
println(examineStream(x.filter{ it > 3 }))
}
With these versions of filter and map, we have now solved the problem of creating temporary lists! Let's look at the steps involved for
Stream.of(1, 2, 3, 4).map{ it + 10 }.filter{ it % 2 == 0 }.map{ it * 3 }
Stream.of(1, 2, 3, 4).map{ it + 10 }.filter{ it % 2 == 0 }.map{ it * 3 }Cons({ 11 }, { Stream.of(2, 3, 4).map{ it + 10 } }).filter{ it % 2 == 0 }.map{ it * 3 }Stream.of(2, 3, 4).map{ it + 10 }.filter{ it % 2 == 0 }.map{ it * 3 }Cons({ 12 }, { Stream.of(3, 4).map{ it + 10 } }).filter{ it % 2 == 0 }.map{ it * 3 }Cons({ 12 }, { Stream.of(3, 4).map{ it + 10 }.filter{ it % 2 == 0} }).map{ it * 3 }Cons({ 36 }, { Stream.of(3, 4).map{ it + 10 }.filter{ it % 2 == 0}.map{ it * 3 } })
This is what (I believe) it actually looks like at the end. We only applied all the transformations on the first element, and if it didn't make it through all of them, then we moved on to the next element until that element completed all the transformations. The transformations aren't applied to the rest of the elements until they need to be (e.g., when examineStream() is calling s.tail()).
Write an instance method for Stream that recursively calculates the length of the Stream.
fun length(): Int =
when (this) {
is Empty -> 0
is Cons -> 1 + tail().length()
}
Corecursion
Corecursion is kinda the opposite of recursion in a way. It uses recursion to generate data instead of, well, whatever you decide to use recursion for. It may seem weird, but there's no base case or termination condition in corecursion. This allows us to create infinite data structures that aren't actually infinite.
fun ones(): Stream<Int> = Stream.cons({ 1 }, { ones() })
We can define a function to take `n` elements from an infinite Stream.
fun <A> Stream<A>.take(n: Int): Stream<A> {
fun helper(xs: Stream<A>, n: Int): Stream<A> =
when(xs) {
is Empty -> Stream.empty()
is Cons ->
if (n == 0) Stream.empty()
else Stream.cons(xs.head, { helper(xs.tail(), n-1) })
}
return helper(this, n)
}
}
fun main() {
println(examineStream(ones().take(100)))
}
We can have something a little more useful than an infinite Stream of just `1`s.
fun countUp(n: Int): Stream<Int> = Stream.cons({ n }, { countUp(n+1) })
Memoization
Let's look at the classic example of calculating the Fibonacci numbers.
The Fibonacci numbers are defined by:
`F_0=0`, `F_1=1`
`F_n=F_(n-1)+F_(n-2)`
The first `11` Fibonacci numbers are:
| `F_0` | `F_1` | `F_2` | `F_3` | `F_4` | `F_5` | `F_6` | `F_7` | `F_8` | `F_9` | `F_10` |
| `0` | `1` | `1` | `2` | `3` | `5` | `8` | `13` | `21` | `34` | `55` |
If we were to do this in code, it would look like this:
fun naiveFibs(n: Int): Int =
if (n < 0) -1
else if (n == 0) 0
else if (n == 1) 1
else naiveFibs(n-2) + naiveFibs(n-1)
As can be inferrred from the name, this way of calculating the Fibonacci numbers is very inefficient. Consider the example of calculating the `5^(th)` Fibonacci number.
Look at how many of the calculations are repeated. Not only is it wasteful, it's actually time-consuming. Instead of recalculating the same values for which we already the answer, we can store them so that we can reuse them when we need to — this is memoization! We actually saw this in action in the "Lazy Initialization in Kotlin" section with Kotlin's lazy function.
We'll use our Stream to generate an infinite sequence of Fibonacci numbers.
While Cons objects (in a Stream) are evaluated only when forced, there's still a problem in that they are evaluated as many times as they are forced. Suppose we had some time-consuming function called expensive().
val x = Cons({ expensive(y) }, { tl })
val h1 = x.headOption()
val h2 = x.headOption()
expensive(y) will be evaluated multiple times. To solve this, we'll use memoization to cache the value of a Cons once they are forced.
To utilize laziness, we'll define a smart constructor, which is a function for constructing a data type that has a slightly different signature than the real constructor.
fun <A> cons(hd: () -> A, tl: () -> Stream<A>): Stream<A> {
val head: A by lazy(hd)
val tail: Stream<A> by lazy(tl)
return Cons({ head }, { tail })
}
This ensures that the thunk will only be called once when forced for the first time. Subsequent forces will return the cached values from using lazy.
By convention, smart constructors are in the companion object of the base class. Their names are also the lowercase version of the corresponding data structure.
So this is how we would generate Fibonacci numbers without recalculating old Fibonacci numbers:
fun fibsInfinity(): Stream<Int> {
fun helper(curr: Int, nxt: Int): Stream<Int> =
Stream.cons({ curr }, { helper(nxt, curr + nxt) })
return helper(0, 1)
}
To get the `n^(th)` Fibonacci number, we can drop the first `n-1` elements of the Stream. We'll need a drop function for this:
fun <A> Stream<A>.drop(n: Int): Stream<A> {
tailrec fun helper(xs: Stream<A>, n: Int): Stream<A> =
when (xs) {
is Empty -> Stream.empty()
is Cons ->
if (n == 0) xs
else helper(xs.tail(), n-1)
}
return helper(this, n)
}
So here's the improved version of calculating Fibonacci numbers:
fun lazyFibs(n: Int): Int {
val f = fibsInfinity().drop(n)
if (f is Cons) return f.head()
else return -1
}
The naiveFibs() function we defined earlier is `O(2^n)` while this lazyFibs() is `O(n)`.
Functional State
Program state refers to the values of the variables, data structures, and other information (e.g., the address of next line to execute, the status of I/O operations) that describe the current state of the program at a specific point in time. In functional programming, changes to program state are undesirable.
So to manipulate program state in a functional way, we view the program state as a transition or action that can be passed around. This keeps the state contained and localized.
Generating Random Numbers
We'll look at how to pass around state by looking at random number generation.
In programming, it's not really possible to generate numbers that are completely random. This is because deterministic algorithms are used to generate them. And these algorithms typically rely on an initial value, called a "seed". With this seed value, the entire "random" sequence of numbers can be reproduced.
For example, a fairly simple algorithm to generate pseudorandom numbers could look like this:
- Start with a seed
- Multiply the seed by a constant
- Add another constant
- Take the result modulo the upper bound
- the upper bound is the highest possible number that we want to generate
- Take the result and use it as the new seed
- Repeat steps `2-4` to generate a sequence of numbers
So this section is really looking at generating pseudorandom numbers with a pseudorandom number generator (PNRG).
If we wanted to generate random numbers in Kotlin, we would do something like this:
val rng = kotlin.random.Random
println(rng.nextInt(10))
println(rng.nextInt(10))
println(rng.nextInt(10))
As we expect, `3` numbers will be printed. Also as we expect, if we run these lines again, then `3` potentially different numbers will be generated. Since calling the same function with the same inputs produces different outputs, nextInt() is not referentially transparent. While we don't know exactly how nextInt() is implemented, we can see that there is some sort of state mutation happening.
Why does this matter? Let's say we're writing a function that simulates the rolling of a six-sided die, i.e., the function should return a value between `1` and `6`, inclusive.
fun rollDie(): Int {
val rng = kotlin.random.Random
return rng.nextInt(6)
}
There is an off-by-one error since nextInt(6) returns a number between `0` and `5`, inclusive. However, if we test this function, then `5` out of `6` times, it will look like it's working as intended.
Let's see how we can generate random numbers in a functional manner.
interface RNG {
fun nextInt(): Pair<Int, RNG>
}
data class SimpleRNG(val seed: Long): RNG {
override fun nextInt(): Pair<Int, RNG> {
val newSeed = (seed * 0x5DEECE66DL + 0xBL) and 0xFFFFFFFFFFFFL
val nextRNG = SimpleRNG(newSeed)
val n = (newSeed ushr 16).toInt()
return n to nextRNG
}
}
ushr is a bitwise shift operator.
to is used to create a Pair. So n to nextRNG is equivalent to Pair(n, nextRNG).
Forget about the details of the algorithm. The important thing to note is that our new nextInt() function is returning two things here: a random number and a random number generator.
fun main() {
val rng1: RNG = SimpleRNG(1001)
val (n1, rng2) = rng1.nextInt()
println(n1)
val (n2, rng3) = rng2.nextInt()
println(n2)
val (n3, rng4) = rng2.nextInt() // rng2 is intentional
println(n3)
}
If we run these lines multiple times, we'll get the same `3` numbers every time.
So what exactly did we do to make this possible? We made the state change explicity known by asking for a seed and returning the new state instead of implicitly mutating the original state.
Stateful APIs
Stateful APIs are interfaces in which the next state depends on the previous state. (Here, stateful means that we're creating a new state and using that to do stuff.) Our RNG is an example of a stateful API, and we'll look at how to extend it.
Let's say we wanted to write a function that generates a pair of random numbers using nextInt().
fun randomPair(rng: RNG): Pair<Pair<Int, Int>, RNG> {
val (i1, rng2) = rng.nextInt()
val (i2, rng3) = rng2.nextInt()
return (i1 to i2) to rng3
}
By returning rng3, we're allowing the caller to generate more random numbers if they need to.
Functional State Practice Problems
Write a function that uses RNG.nextInt() to generate a random integer between `0` and Int.MAX_VALUE (inclusive). Each negative value must be mapped to a distinct nonnegative value. Make sure to handle the corner case when nextInt() returns Int.MIN_VALUE, which doesn't have a nonnegative counterpart. (The range of an integer is `-2,147,483,648` to `2,147,483,647`, inclusive.)
fun nonNegativeInt(rng: RNG): Int {
val (i1, rng2) = rng.nextInt()
return if (i1 < 0) -(i1 + 1) else i1
}
Write a new version of the function that returns a Pair<Int, RNG> with the new RNG created when you used the old RNG.
fun nonNegativeInt(rng: RNG): Pair<Int, RNG> {
val (i1, rng2) = rng.nextInt()
return (if (i1 < 0) -(i1 + 1) else i1) to rng2
}
Write a function that takes an Int count and an RNG and generates a List of random Ints in a Pair with the RNG created when the last random Int was generated.
fun ints(count: Int, rng: RNG): Pair<List<Int>, RNG> =
if (count > 0) {
val (i, r1) = rng.nextInt()
val (xs, r2) = ints(count-1, r1)
listOf(i) + xs to r2
} else emptyList<Int>() to rng
This function maps integers (from a random number generator) to capital letters:
fun randChar(rng: RNG): Pair<Char, RNG> {
val (i1, newRng) = rng.nextInt()
val i = if (i1 < 0) -(i1 + 1) else i1
val rC = i % 26 + 65
return rC.toChar() to newRng
}
Write a function myF() that takes an RNG and an Int called count and returns a Pair<String, RNG>, where the String is a series of random capital letters whose length is count, and RNG is the last random number generator created in the series.
fun myF(rng: RNG, count: Int): Pair<String, RNG> {
tailrec fun helper(rng: RNG, count: Int, acc: Pair<String, RNG>): Pair<String, RNG> =
if (count == 0) acc
else {
val (c, newRng) = randChar(rng)
helper(newRng, count-1, acc.first+c to newRng)
}
return helper(rng, count, "" to rng)
}
There's a common pattern (which can be seen in the exercises above) where functions that need to return a value and a state return them as a Pair. These functions have a type of the form (RNG) -> Pair<A, RNG> for some type A. Functions of this type are called "state actions" or "state transitions" because they transform states from one call to the next.
(RNG) -> Pair<A, RNG> can be a bit cumbersome to read and type. In Kotlin, we can declare a type alias to make it simpler:
typealias Rand<A> = (RNG) -> Pair<A, RNG>
Here's an example of how it would be used:
fun main() {
val rng = SimpleRNG(92422)
val intR: Rand<Int> = { r -> r.nextInt() }
val (n, rng2) = intR(rng)
println(n)
}
Combinators
State actions can be combined using combinators, which are higher-order functions that combine or transform functions in some way to produce new functions.
fun <A, B> map(s: Rand<A>, f: (A) -> B): Rand<B> =
{ rng ->
val (a, rng2) = s(rng)
f(a) to rng2
}
map is a combinator that takes an RNG function (passed in as s) and applies f to the random number that is generated by s. Here's an example using it:
fun main() {
val rng = SimpleRNG(942)
val doubleR: Rand<Double> = map(::nonNegativeInt) { i -> i / (Int.MAX_VALUE.toDouble() + 1) }
val (d, _) = doubleR(rng)
println(d)
}
So we're taking the random integer generated by nonNegativeInt and dividing it by (Int.MAX_VALUE.toDouble() + 1).
Now here's something that's a little more complicated. We can take two state actions and apply a binary function to them:
fun <A, B, C> map2(ra: Rand<A>, rb: Rand<B>, f: (A, B) -> C): Rand<C> =
{ r1: RNG ->
val (a, r2) = ra(r1)
val (b, r3) = rb(r2)
f(a, b) to r3
}
fun <A, B> both(ra: Rand<A>, rb: Rand<B>): Rand<Pair<A, B>> =
map2(ra, rb) { a, b -> a to b }
fun main() {
val rng = SimpleRNG(942)
val intR: Rand<Int> = { rng -> rng.nextInt() }
val doubleR: Rand<Double> = map(::nonNegativeInt) { i -> i / (Int.MAX_VALUE.toDouble() + 1) }
val intDoubleR: Rand<Pair<Int, Double>> = both(intR, doubleR)
val (p, _) = intDoubleR(rng)
println(p)
}
So we're taking the random numbers generated by intR (passed as ra)and doubleR (passed as rb) and creating a Pair with them (using the lambda { a, b -> a to b }).
Monoids
No, it's not some infectious disease. In math (specifically, abstract algebra), a monoid is a set that has an associative binary operation and an identity element.
Recall that an operation is associative if we can group the elements in any way and still get the same result. For example, addition is associative because `(a+b)+c=a+(b+c)`.
An identity element is hard to explain in a grammatically correct sentence. Here are some examples instead:
For addition, the identity element is `0` because `a+0=a`.
For multiplication, the identity element is `1` because `a*1=a`.
Basically, when we perform the operation with a value and the identity element, the result is the value.
In programming, a monoid is a type with an associative binary operation and an identity element. We can create a monoid with the string concatenation operator. String concatenation is associative and the identity element is the empty string.
We can't create monoids with subtraction and division because those operations aren't associative. For subtraction, `(1-2)-3 != 1-(2-3)`. For division, `(6//2)//2 != 6//(2//2)`.
We can create a monoid with truth values and logical and (&). & is associative and the identity element is true.
We can express a monoid in Kotlin as an interface:
interface Monoid<A> {
fun combine(a1: A, a2: A): A
val nil: A
}
And create a monoid by implementing it:
val stringMonoid = object: Monoid<String> {
override fun combine(a1: String, a2: String): String = a1 + a2
override val nil: String = ""
}
fun main() {
println(stringMonoid.combine("h", "ello"))
println(stringMonoid.combine("hello", stringMonoid.nil))
}
A subtle thing to note here is that we're implementing an interface with an object instead of a class.
Here's another way with a monoid instance:
fun intAddition(): Monoid<Int> = object: Monoid<Int> {
override fun combine(a1: Int, a2: Int): Int = a1 + a2
override val nil: Int = 0
}
fun main() {
val add = intAddition()::combine
println(add(4,5))
println(add(1, add(2, add(3, 4))))
println(add(add(1, 2), add(3, 4)))
println(add(add(add(1, 2), 3), 4))
}
So what are monoids used for anyway? From the lecture slides:
- A monoid can be used as an abstraction
- We can write generic code, assuming only the capabilities provided by the fact that the abstraction is a monoid
Whatever that means.
It turns out that monoids are helpful for things like combining data structures and aggregating results. Monoids make it possible to do those things in a parallel manner, which we're about to see.
Lists and Monoids
Not relevant to this section, but list concatenation forms a monoid.
fun <A> listMonoid(): Monoid<List<A>> = object: Monoid<List<A>> {
override fun combine(a1: List<A>, a2: List<A>): List<A> = a1 + a2
override val nil: List<A> = emptyList()
}
This is from the "Stream" section, but I'll include it here again.
Kotlin's fold() function reduces a collection to a single value by applying an operation to each element in the collection. It takes in two parameters: 1) an initial value for an accumulator and 2) a function that is applied to each element in the list.
fun main() {
val x = listOf(1, 2, 3, 4, 5)
println(x.fold(0, {acc: Int, i: Int -> acc + i }))
}
foldLeft() and foldRight() are custom implementations of fold() that we can define if we want to iterate over the collection in a certain order. foldLeft() starts at the beginning and iterates to the end (left to right), while foldRight() starts at the end and iterates backwards to the beginning (right to left).
fun <A> List<A>.foldLeft(initial: A, operation: (acc: A, A) -> A): A {
tailrec fun helper(l: List<A>, acc: A): A =
if (l.isEmpty()) acc
else helper(l.drop(1), operation(acc, l[0]))
return helper(this, initial)
}
fun <A> List<A>.foldRight(initial: A, operation: (acc: A, A) -> A): A {
tailrec fun helper(l: List<A>, acc: A): A =
if (l.isEmpty()) acc
else helper(l.dropLast(1), operation(acc, l[l.size-1]))
return helper(this, initial)
}
If we call foldLeft() and foldRight() with a monoid, then we should get the same result for both functions (since the operation is associative).
val myIntMonoid = intAddition()
fun main() {
val l = listOf(1, 2, 3, 4, 5)
println(l.foldLeft(myIntMonoid.nil, myIntMonoid::combine))
println(l.foldRight(myIntMonoid.nil, myIntMonoid::combine))
}
The problem with foldLeft() and foldRight() is that they aren't efficient when the lists are very large (they iterate one element at a time). We can solve this by taking advantage of the fact that the operator in a monoid is associative, meaning that we can start from anywhere, combine the results in any way, and still get the same result as if we iterated one element at a time.
fun <A> List<A>.splitAt(n: Int): Pair<List<A>, List<A>> {
val mid: Int = (n+1)/2
val s1: List<A> = this.take(mid)
val s2: List<A> = this.drop(mid)
return s1 to s2
}
fun <A> List<A>.balancedFold(initial: A, operation: (acc: A, A) -> A): A =
when {
this.isEmpty() -> initial
this.size == 1 -> operation(initial, this[0])
else -> {
val (left, right) = this.splitAt(this.size / 2)
operation(left.balancedFold(initial, operation), right.balancedFold(initial, operation))
}
}
Monoids Practice Problems
XOR (exclusive OR) is a binary operation which is true if exactly one of the operands (which are Booleans or boolean expressions) is true (inclusive OR is true if at least one of the operands is true). Kotlin has an xor operator: a.xor(b).
Write an XOR monoid instance (a singleton) with an identity element and a combine() function. In addition, write xorFoldLeft(), xorFoldRight(), and xorBalancedFold() with these function headers:
fun xorFoldLeft(l: List<Boolean>, initial: Boolean): Boolean
fun xorFoldRight(l: List<Boolean>, initial: Boolean): Boolean
fun xorBalancedFold(l: List<Boolean>, initial: Boolean): Boolean
fun xorMonoid(): Monoid<Boolean> = object: Monoid<Boolean> {
override fun combine(a1: Boolean, a2: Boolean): Boolean = a1.xor(a2)
override val nil: Boolean = false
}
fun xorFoldLeft(l: List<Boolean>, initial: Boolean): Boolean {
tailrec fun helper(l: List<Boolean>, acc: Boolean): Boolean =
if (l.isEmpty()) acc
else helper(l.drop(1), xorMonoid().combine(l[0], acc))
return helper(l, initial)
}
fun xorFoldRight(l: List<Boolean>, initial: Boolean): Boolean {
tailrec fun helper(l: List<Boolean>, acc: Boolean): Boolean =
if (l.isEmpty()) acc
else helper(l.dropLast(1), xorMonoid().combine(l[l.size-1], acc))
return helper(l, initial)
}
fun xorBalancedFold(l: List<Boolean>, initial: Boolean): Boolean =
when {
l.isEmpty() -> initial
l.size == 1 -> xorMonoid().combine(l[0], initial)
else -> {
val (left, right) = l.splitAt(l.size / 2)
xorMonoid().combine(xorBalancedFold(left, xorMonoid().nil), xorBalancedFold(right, xorMonoid().nil))
}
}