Machine Learning
Shortcut to this page: ntrllog.netlify.app/ml
Notes provided by Professor Mohammad Pourhomayoun (CSULA)
Machine learning is using a set of algorithms that can detect and extract patterns from data to make predictions on future data. The process of detecting and extracting patterns from data is called training (this is the "learning" in "machine learning"). A machine learning model is trained so that the model can make predictions on future data. The data used to train the model is called the training data and the data used to make predictions is called the testing data.
There are many different types of machine learning algorithms and this page will explore how some of them work.
KNN (K-Nearest Neighbors): Like a near neighbor, State Farm is there. And there. And there.
Let's say we took the time to scour a website and collect some weather data for Los Angeles.
| Humidity (%) | Temperature (°F) | Sunny/Rainy |
| 42 | 97 | Sunny |
| 43 | 84 | Sunny |
| 44 | 68 | Rainy |
| 94 | 54 | Rainy |
| 51 | 79 | Sunny |
| 91 | 61 | Rainy |
| 39 | 84 | Sunny |
| 47 | 95 | Sunny |
| 96 | 55 | Rainy |
| 90 | 84 | Rainy |
| Humidity (%) | Temperature (°F) | Sunny/Rainy |
| 60 | 84 | Sunny |
| 61 | 79 | Sunny |
| 61 | 68 | Rainy |
| 92 | 55 | Rainy |
| 26 | 77 | Sunny |
| 92 | 61 | Rainy |
| 54 | 81 | Sunny |
| 62 | 72 | Sunny |
| 94 | 61 | Rainy |
| 93 | 59 | Rainy |
It's easy to notice that sunny days (red) are mostly in the top left and rainy days (blue) are mostly in the bottom right. Now let's say someone gives us the temperature (86°F) and humidity (59%) for a day and we have to guess whether it was rainy or sunny on that day (our lives depend on it!).
The temperature and humidity that the person gave us is plotted in green. Since it seems to be in red territory, we can guess that it was sunny on that day. 😎
This is the basic idea behind KNN classification. For any point that we are trying to figure out, we look at the points that are closest to it (neighbors) to see what it is similar to. We assume that data points for a particular result share the same characteristics. For example, sunny days tend to have high temperatures and low humidity while rainy days tend to have low temperatures and high humidity.

This letter is short for the word "okay". What is K?
So looking at a point's neighbors allows us to make some guesses about that point. But how many neighbors do we need to look at, i.e., what should the value of `k` be?
Using just 1 neighbor (`k=1`) is not a good idea.
The green data point is actually a sunny day, but let's pretend we didn't know whether it was rainy or sunny. If we looked at just 1 of its closest neighbors, we would think it was rainy. But if we look at, say, 5 of its closest neighbors, then the story changes.
It's now closer to more sunny days than rainy days, so we would then correctly guess that it was sunny.
Having more neighbors can also lessen the impact of outliers. For example, the left-most blue point (44% humidity, 68°F) could be considered an outlier since it is a rainy day with low humidity. But if we were to guess a random point in that general area (for example (40% humidity, 80°F)), it would be closer to more sunny days than rainy days so that outlier doesn't really affect the outcome.
Using more neighbors seems to be better since our decision is based on more information. So should we just use a ton of neighbors everytime?
Let's suppose we only had information for 14 days instead of 20 and that significantly more of the days were sunny than rainy. The green point (80% humidity and 70°F) is unknown and we're trying to figure out whether it is rainy or sunny. Given its characteristics (low temperature and high humidity), it looks like it should be rainy.
Using 1, 2, 3, 4, or 5 neighbors, we do see that it is closer to more rainy days than sunny days.
However, look what happens when we start using more than 6 neighbors.
Now it is "closer" to more sunny days than rainy days. And it will stay this way even as we use more neighbors. This happened because the dataset was unbalanced (there were significantly more sunny days than rainy days in the dataset), so using more neighbors introduced a bias towards the more popular label.
So there is the possibility of using too few neighbors or too many neighbors. However, picking the right number of neighbors reliably is best done through trial and error.
Euclidean Distance
So far, we have just been looking at the graph to see which points were neighbors to a given point. But computers can't "see" graphs, so they need to actually calculate the distance between each pair of points to see which of them has the shortest distance. (The points with the shortest distance to the given point are its neighbors.)
The formula for calculating the distance between 2 points `(x_1,y_1), (x_2,y_2)` is
`sqrt((x_1-x_2)^2+(y_1-y_2)^2)`
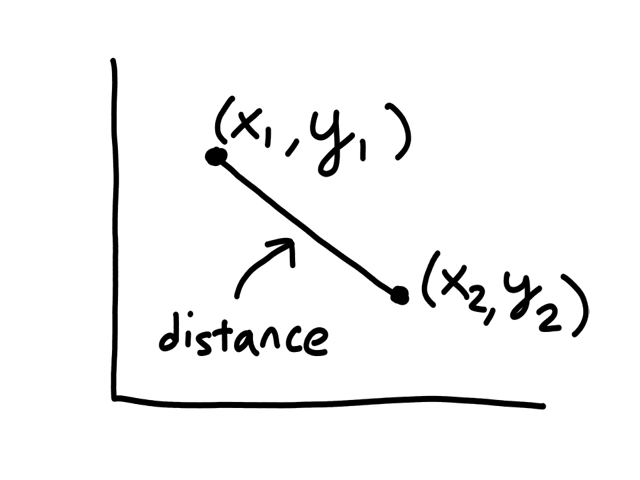
So to find the nearest neighbor of a given point, the computer has to calculate the distance between it and all the other points in the dataset. Then it sorts the distances to find the top `k` shortest distances. From this point of view, using a small number of neighbors makes things faster because there are less distances to calculate and sort.
Advantages of using a large `k`:
- ignores the effect of outliers
- better decision making
Advantages of using a small `k`:
- low computational complexity
- no bias towards popular labels
Normalization
A subtle thing to note about the weather data is that the scale of the units (percentage and degrees) was roughly similar. They both can theoretically range from 0-100. This is a good thing because there are some side effects of using units that aren't on a similar scale as each other.
To highlight this, we take a look at another dataset, which is completely made-up.
| Size (square feet) | Number of Bedrooms | Sold/Not Sold |
| 3000 | 1 | Sold |
| 4000 | 2 | Not Sold |
| 5000 | 3 | Sold |
| 6000 | 4 | Not Sold |
| 7000 | 5 | Not Sold |
The size of a house and the number of bedrooms it has are on completely different scales, with size in the thousands and number of bedrooms ranging from 1-5. So when we calculate distances between points, the number of bedrooms has a negligible impact on the distance. Consider this distance:
`sqrt((3000-4000)^2+(1-2)^2)`
`= sqrt((-1000)^2+(-1)^2)`
`= sqrt(1,000,000+1)`
and this distance:
`sqrt((3000-7000)^2+(1-5)^2)`
`= sqrt((-4000)^2+(-4)^2)`
`= sqrt(16,000,000+16)`
1,000,000 and 16,000,000 are really big numbers, so there's not much of a difference if we add 1 or 16 to them. This means that the effect of considering the number of bedrooms is practically negligible (we would get pretty much the same answer even if we didn't include the number of bedrooms in the calculation). It's like a millionaire finding a 20-dollar bill on the ground.
If the number of bedrooms is practically negligible, then KNN will — effectively — just look at the size of the house to predict whether or not it will be sold, which isn't what we want because we know the number of bedrooms should also have a significant impact. (🎵 Why you got a 12 car garage? 🎵) To prevent this, we can normalize the data so that the units are on the same scale.
One way to normalize data is to make the units on a scale from 0 to 1. We can do this by dividing each data point by the max value for that feature. In the housing dataset, the max size of a house is 7000 and the max number of bedrooms is 5, so we divide each size by 7000 and each number of bedrooms by 5.
| Size (square feet) [normalized] | Number of Bedrooms [normalized] | Sold/Not Sold |
| 0.4 | 0.2 | Sold |
| 0.6 | 0.4 | Not Sold |
| 0.7 | 0.6 | Sold |
| 0.9 | 0.8 | Not Sold |
| 1 | 1 | Not Sold |
The two distances calculated previously now become:
`sqrt((0.4-0.6)^2+(0.2-0.4)^2)`
`= sqrt((-0.2)^2+(-0.2)^2)`
`= sqrt(0.04+0.04)`
and:
`sqrt((0.4-1)^2+(0.2-1)^2)`
`= sqrt((-0.6)^2+(-0.8)^2)`
`= sqrt(0.36+0.64)`
Now the number of bedrooms has an impact on the distance.
Advantages and Disadvantages of KNN
Advantages of KNN:
- simple and requires low computational complexity
- all it's doing is calculating distances between points and then finding the shortest distances
Disadvantages of KNN:
- intensive when there are a lot of data points
- choosing a good `k` is hard
- most reliable way is through trial and error
Decision Tree
Now we take a turn (but not into an iceberg) and look at people on the Titanic. Or at least 891 of them anyway. Green means the person survived and red means they didn't.
There are some negative ages, which means that the ages for those people are unknown.
There are some clear patterns in the data. For example, females had a higher survival chance than males did and younger (male) children had a higher survival chance than older (male) adults. #BirkenheadDrill. So if we chose a random person on the Titanic and tried to guess if they survived or not, a good start would be looking at age and gender. If they were female, they probably survived. If they were young, they probably survived. Of course, there were several males who survived and several older people who survived, but classifying based on gender and age is better than random guessing in this case.
We could also look at how fancy they were. The lower the number, the fancier. (🎵 We flyin' first class... 🎵)
There's also a clear pattern here. Higher-class passengers tended to survive while lower-class passengers didn't. So in addition to looking at age and gender, we could also use passenger class to predict whether a randomly-chosen person on the Titanic survived or not. #PayToWin. Also, the same age pattern kind of appears here, more so for class 2 and 3.
Another feature there is data for is how many parents or children each passenger was travelling with. So if someone has a value of 3, then they could've been travelling with their parents and child or their three children.
This time, there's not really a clear pattern. There's neither an increasing nor decreasing trend as we move between levels, i.e., the chance of survival for those travelling with 3 family members looks about the same as the chance of survival for those travelling with 2 or 1 family members. So looking at the number of family members someone was travelling with doesn't give us a good idea of survival chance.
So some useful features we found are age, gender, and passenger class, all of which we could use to predict whether someone survived or not. This could be represented using a tree, where first we check gender, then passenger class, then age.

Many things with this tree are arbitrary. Like which features to check and in what order. And what age to use as a threshold (e.g., 4). This tree is based on the manual visual analysis we did earlier, but how do we do this systematically (so that we can create a tree for any dataset) and reliably (so that the tree is actually able to predict correct results)?
First, we have to find out which features are important and which ones aren't. But what does "important" mean? In this case, a feature is important if it provides a good amount of information. For example, age, gender, and passenger class are important because they are all able to tell us whether a passenger survived. The number of family members is not important because it told us nothing about survival chance. But does age give us more information than gender? Or does gender give us more information than passenger class? We need a way to measure information.
Information Theory
There are two important concepts about information. The first is: the amount of information about an event has an inverse relationship to the probability of that event happening. This means that events that are likely to happen don't surprise us while events that don't happen often give us a lot of information. For example, "the sun will rise in the morning" doesn't give us a lot of information because we already know this will happen. However, "an eclipse will occur tomorrow" is news to us because it doesn't happen that often.
For an event `x`, the concept can be represented mathematically as
`I(x) prop 1/(p(x))`
where `I(x)` represents the amount of information of `x` and `p(x)` is the probability of `x` happening.
The second important concept about information is: when two independent events happen, the joint probability of them is the product of their probabilities and the total information about them is the sum of their information.
For example, there is a `1/2` chance of flipping a coin and getting heads and there is a `1/2` chance of flipping a coin and getting tails. So the probability of getting a head on the first flip and then a tail on the second flip is `1/2*1/2=1/4`. Getting a head and getting a tail are two independent events because the result of the coin flip does not depend on what happened in the past flips.
Let's say a coin is flipped twice, but we don't know the results of the two flips. If we ask about the first flip, then we get `1` piece of information. If we ask about the second flip, then we get another `1` piece of information. So then we would have `1+1=2` pieces of information.
Let `p_1` be the probability of one (independent) event happening and `p_2` be the probability of another (independent) event happening. Let `I` be a function that represents the amount of information learned from an event happening. Then the information from these two events happening (`I(p_1 cdot p_2)`) is the sum of their information (`I(p_1)+I(p_2)`).
`I(p_1 cdot p_2)=I(p_1)+I(p_2)`
So if there was a way to measure information, then it would have to turn products into sums. Luckily, the log function does just that.
Log properties:
- `log(x cdot y) = log(x) + log(y)`
- `log(1)=0`
- Notice that represents the information function quite nicely. If the probability of an event is `1`, then it gives us no information at all.
- `log(1/x)=-log(x)`
So a function that measures the information of an event should calculate the log of the probability of that event. Also, the amount of information about an event has an inverse relationship to the probability of that event happening (the first concept). Both of these lead to the formulation of the information function:
`I(x)=log(1/(p(x)))=-log(p(x))`
Entropy: "What is it?"
There's a term for the amount of information we don't know. Entropy. It measures the amount of "uncertainty" of an event. That is, if an event occurred, how certain can we be that we will know the results of that event? If we're not really sure what the outcome will be, then there is high entropy. If we're certain enough to bet money on the outcome, then there is low entropy.
Another interpretation of entropy is that it represents expected information. When an event has occurred, then we "expect" to receive some information from the result. This is why the formula for entropy (denoted as `H`) is the expected value (denoted as `E`) of the information:
`H(X) = E(I(X)) = sum_(x in chi) p(x) cdot I(x)`
`= -sum_(x in chi)p(x)log(p(x))`
where `chi` represents all the possible outcomes for event `X`
Typically entropy uses log base 2, in which case the unit of measurement is 'bits' (8 bits = 1 byte). When the entropy is measured in bits, the interpretation is that it takes that many bits to inform someone of the outcome. For example, an entropy of 0 means that no bits are required to convey information (because the probability of that event happening was 1 so we didn't need to make space to store that information). An entropy of 1 means that 1 bit is required to convey the outcome. In the case of a coin flip, heads can be encoded as 1 and tails can be encoded as 0. Either result would require 1 bit to store it.
1 is the maximum value for entropy though I have yet to have an explanation why.
If we have a fair coin (probability of heads is `1/2` and probability of tails is `1/2`) and an unfair coin (e.g., probability of heads is `7/10` and probability of tails is `3/10`), which coin is more predictable? Obviously, the unfair coin is more predictable since it is more likely to land on heads. We can prove this by calculating entropy.
There are only two possible outcomes for flipping a coin and the probabilities of those outcomes are both `1/2` for the fair coin. So the entropy of flipping a fair coin is
`-sum_(x in X)p(x)log_2(p(x))`
`= -(0.5log_2(0.5)+0.5log_2(0.5))`
`= 1`
The entropy of flipping the unfair coin is
`-sum_(x in X)p(x)log_2(p(x))`
`= -(0.7log_2(0.7)+0.3log_2(0.3))`
`~~ 0.88`
There is less entropy with flipping an unfair coin, which means there is less uncertainty with flipping an unfair coin. This makes sense because we know it is more likely to land on heads.
Also notice that there is an entropy of 1 when flipping a fair coin. This means that we are completely unsure of what the result will be, which makes sense because each result is equally likely.
Information Gain
If we gain information, then we reduce uncertainty. If we reduce entropy, then we gain information. Information gain is the measure of how much entropy is reduced.
And Now, Back to Our Regularly Scheduled Programming
Before the discussion on information theory, we needed a way to measure information so we could figure out which features of a dataset were important and which were more important than others so we could build a decision tree. Now we have a way to measure information — and lack thereof, a.k.a. entropy. So how do we use it to determine which features are important?
Let's go back to the titanic dataset and pretend that we knew nothing about it. We would have a hard time predicting survivability (again, forgetting everything that we just found out about the dataset). Now let's say we analyzed survivability by gender and found out that females were way more likely to survive than males. Now how hard would it be to predict survivability? Splitting the data by gender reduced uncertainty/entropy and increased information gain. So a feature is important if it reduces entropy.
This means that when deciding which features to put at the top of the decision tree (i.e., which features to check first), we should look for features that reduce entropy the most. If you were playing 20 questions, would you rather ask a question that provided you with more information or no information?
Feature Finding
Splitting the data by certain features can reduce entropy. The idea is that there is a certain amount of entropy before splitting the data, and after splitting the data, the entropy is lower. Some features will reduce the entropy more than others. To see this calculation in action, let's revisit the weather, but this time look at a different dataset.
| Temperature | Humidity | Windy | Label |
| high | low | yes | sunny |
| low | high | yes | rainy |
| high | low | no | sunny |
| high | high | yes | sunny |
| mild | mild | no | sunny |
| mild | high | no | rainy |
| low | mild | yes | rainy |
There are `7` samples, `4` of them are sunny and `3` of them are rainy. So the probability of a day being sunny is `4/7` and the probability of a day being rainy is `3/7`.
Calculating the entropy, we get:
`H(X) = -sum_(x in chi)p(x)log_2(p(x))`
`= -((4/7)log_2(4/7)+(3/7)log_2(3/7))`
`~~ 0.98`
Splitting the data on a feature means dividing the data into subsets based on that feature. For example, splitting the data on wind means putting all the windy data in one group and putting all the non-windy data in another group. This allows us to see how much of an impact that feature has on the result. So if we find out that the probability of a sunny day is high in the windy group and low in the non-windy group, then that means wind has an impact on whether a day is sunny or not. If the probability is pretty much the same in both groups, then that means wind does not affect whether a day is sunny or not.
🎵 It's gettin' windy here 🎵
Now let's try splitting the data on wind. There are `4` windy days with `1` of them being sunny and `3` of them being rainy. So if a day is windy, then the probability of that day being sunny is `1/4` and the probability of that day being rainy is `3/4`. Calculating the entropy for windy days, we get:
`H(X) = -sum_(x in chi)p(x)log_2(p(x))`
`= -((1/4)log_2(1/4)+(3/4)log_2(3/4))`
`~~ 0.81`
There are `3` non-windy days with `2` of them being sunny and `1` of them being rainy. So if a day is not windy, the probability of that day being sunny is `2/3` and the probability of that day being rainy is `1/3`. Calculating the entropy for non-windy days, we get:
`H(X) = -sum_(x in chi)p(x)log_2(p(x))`
`= -((2/3)log_2(2/3)+(1/3)log_2(1/3))`
`~~ 0.91`
We have two entropies for each of the values of the wind feature. Getting their weighted average will give us the average entropy after splitting the data on wind.
`E(H(X)) = sum_(x in chi)p(x)H(x)`
`= (4/7)(0.81)+(3/7)(0.91)`
`~~ 0.85`
So we went from an entropy of 0.98 to an entropy of 0.85 after splitting that data on wind. It's a slight decrease, but not by much. If we think about it, wind level generally doesn't tell us whether a day will be sunny or rainy.
🎵 It's gettin' humid here 🎵
Now let's try splitting the data on humidity. There are `3` high humid days with `0` of them being sunny and `3` of them being rainy. So if a day has high humidity, then the probability of that day being sunny is `0/3=0` and the probability of that day being rainy is `3/3=1`. Calculating the entropy for high humid days, we get:
`H(X) = -sum_(x in chi)p(x)log_2(p(x))`
`= -((0)log_2(0)+(1)log_2(1))`
`= 0`
At first glance, this may seem surprising. But looking at the dataset, every day with high humidity was rainy. So, according to this dataset, if a day has high humidity, it will always rain, so there is no uncertainty, hence the 0.
There are `2` mild humid days with `1` of them being sunny and `1` of them being rainy. So if a day has mild humidity, the probability of that day being sunny is `1/2` and the probability of that day being rainy is `1/2`. Calculating the entropy for mild humid days, we get:
`H(X) = -sum_(x in chi)p(x)log_2(p(x))`
`= -((1/2)log_2(1/2)+(1/2)log_2(1/2))`
`= 1`
Again, looking at the dataset, there was 1 mild humid sunny day and 1 mild humid rainy day. So if a day is mild humid, it can be either sunny or rainy. Maximum uncertainty.
There are `2` low humid days with `2` of them being sunny and `0` of them being rainy. So if a day has low humidity, the probability of that day being sunny is `2/2=1` and the probability of that day being rainy is `0/2=0`. Calculating the entropy for low humid days, we get:
`H(X) = -sum_(x in chi)p(x)log_2(p(x))`
`= -((1)log_2(1)+(0)log_2(0))`
`= 0`
Each time the day was low humid, it was sunny. So no uncertainty.
We have three entropies for each of the values of the humidity feature. Getting their weighted average will give us the average entropy after splitting the data on humidity.
`E(H(X)) = sum_(x in chi)p(x)H(x)`
`= (3/7)(0)+(2/7)(1)+(2/7)(0)`
`~~ 0.28`
This was actually a big decrease in entropy (from 0.98 to 0.28). This means that splitting the data on humidity reduces uncertainty by a lot, i.e., humidity gives us a lot of information about whether a day will sunny or rainy. We saw this with real data back in the KNN section.
🎵 It's gettin' hot in here 🎵
Now let's try splitting the data on temperature. There are `3` high temperature days with `2` of them being sunny and `1` of them being rainy. So if a day has high temperature, then the probability of that day being sunny is `2/3` and the probability of that day being rainy is `1/3`. Calculating the entropy for high temperature days, we get:
`H(X) = -sum_(x in chi)p(x)log_2(p(x))`
`= -((2/3)log_2(2/3)+(1/3)log_2(1/3))`
`~~ 0.91`
There are `2` mild temperature days with `1` of them being sunny and `1` of them being rainy. So if a day has mild temperature, the probability of that day being sunny is `1/2` and the probability of that day being rainy is `1/2`. Calculating the entropy for mild temperature days, we get:
`H(X) = -sum_(x in chi)p(x)log_2(p(x))`
`= -((1/2)log_2(1/2)+(1/2)log_2(1/2))`
`= 1`
There are `2` low temperature days with `0` of them being sunny and `2` of them being rainy. So if a day has low temperature, the probability of that day being sunny is `0/2=0` and the probability of that day being rainy is `2/2=1`. Calculating the entropy for low temperature days, we get:
`H(X) = -sum_(x in chi)p(x)log_2(p(x))`
`= -((0)log_2(0)+(1)log_2(1))`
`= 0`
We have three entropies for each of the values of the temperature feature. Getting their weighted average will give us the average entropy after splitting the data on temperature.
`E(H(X)) = sum_(x in chi)p(x)H(x)`
`= (3/7)(0.91)+(2/7)(1)+(2/7)(0)`
`~~ 0.67`
There was a big decrease (0.98 to 0.67), but not as big as the decrease from humidity. So temperature gives us a decent amount of information, but not as much as humidity. Which makes sense in real life because cold temperatures doesn't necessarily mean it's raining.
Top of the Tree
Humidity reduced entropy the most, so if we were building a decision tree to predict weather, the first feature to check would be humidity.
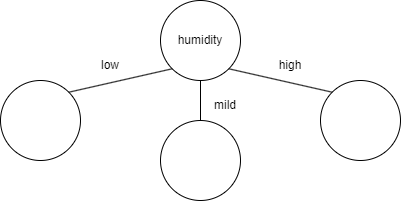
Temperature had the second most entropy reduction, but that doesn't mean it should be the next feature to check after humidity. That's because the calculation was entropy reduction from the starting entropy (0.98). After splitting the data, we're no longer working with the original dataset (because we've split the data). So if we were to continue building the tree after mild humidity, the new starting entropy would be 1 (calculated previously when it was gettin' humid in here) and we would be looking to see which feature (temperature or wind) would reduce that entropy value more. The same would have to be done for low and high humidity. In this case, the entropy for low and high humidity are both 0, so there's no reduction possible (which means based on this feature alone, we are able to tell whether a day is rainy or sunny). But theoretically, the branches below the second level of the tree could be different. For example, for low humidity, the best feature to check next might be temperature, but for mild humidity, the best feature to check next might be wind.
ID3 Algorithm
This is an algorithm to systematically build a decision tree. It's basically what we did above.
- Calculate entropy after splitting the data on every feature
- Select the feature that has the most entropy reduction
- Split the data into subsets using that feature and make a decision tree node for that feature
- Repeat with remaining features until
- no features left or
- all samples assigned to the same label (entropy is 0 for all nodes one level above all leaf nodes)
Viewer Discretization Is Advised
One thing that should be noted is that all the values for each feature were categorical values. They weren't numerical. For example, temperature was low, mild, high instead of 60, 75, 91. This is important because a decision tree shouldn't have branches for each numerical value. If the temperature is 90, then check this. If the temperature is 89, then check this. If the temperature is 88 ....
Let's say instead of low, mild, high for temperature, we had actual numerical values.
| Temperature | Humidity | Windy | Label |
| 90 | low | yes | sunny |
| 60 | high | yes | rainy |
| 92 | low | no | sunny |
| 89 | high | yes | sunny |
| 70 | mild | no | sunny |
| 73 | high | no | rainy |
| 61 | mild | yes | rainy |
Instead of building a decision tree for this dataset, we would want to first discretize the numerical values (i.e., convert the numbers into categories). Sorting the values first would help a lot.
| Temperature | Humidity | Windy | Label |
| 92 | low | no | sunny |
| 90 | low | yes | sunny |
| 89 | high | yes | sunny |
| 73 | high | no | rainy |
| 70 | mild | no | sunny |
| 61 | mild | yes | rainy |
| 60 | high | yes | rainy |
Now we need to define intervals/thresholds for what low, mild, and high temperatures are. Generally, the way to find the best threshold is to try every possible split to see which one minimizes entropy. However, there can sometimes be some more efficient ways to find the thresholds.
Looking at just temperature and label, we can notice that all days with temperature 89 and above are sunny and all days with temperature 61 and below are rainy. So we can decide that if a temperature is above 80, then it is considered high and if a temperature is below 65, then it is considered low.
Advantages and Disadvantages of Decision Tree
Advantages of Decision Tree:
- easily interpretable by a human
- it's easy to look at a tree and understand what it means and how to use it
- handles both numerical and categorical data
- (theoretically) works even with missing data*
- parametric algorithm
- just need to use training data once to build the tree, then use the tree to make predictions
- unlike KNN which needs to have the training dataset everytime to calculate distances for every prediction
- just need to use training data once to build the tree, then use the tree to make predictions
Disadvantages of Decision Tree:
- very prone to overfitting (see "A7) Overfitting")
- heuristic training techniques (brute force, trial and error)
- calculating entropy
- finding thresholds for discretizing numerical data
*Let's bring back the tree:
Will a 7-year old girl survive? Based on the tree, she will survive no matter what passenger class she is in. So even if there was no data for her passenger class, the tree could still (theoretically) make a prediction.
Linear Regression
So far, the algorithms we have looked at only predict categories, like sunny/rainy, sold/not sold, survived/didn't survive. But it is also possible to predict numerical values, like how much something will cost or how much rainfall an area will get.
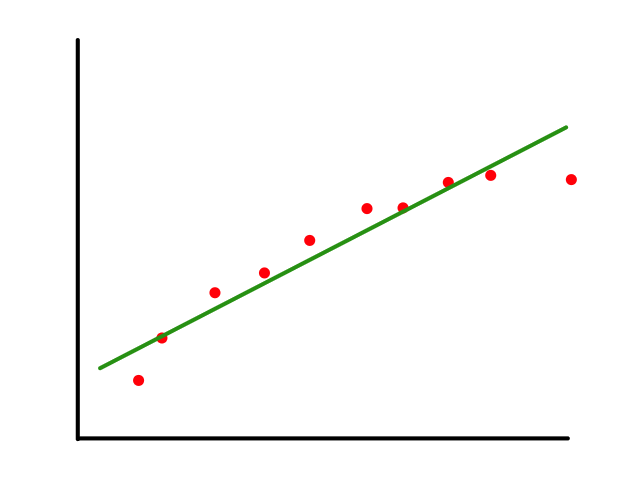
To start, we can look at some fake data for housing prices. In this case, we are only looking at one feature (square footage) and the price that the house sold for.
We can predict the price of houses based on their square footage by drawing a line ("linear" regression) through the data points that best fits the data. So if there is a house with 2000 square feet, then we can predict that it will cost around $1,250,000.
Of course, the question now is how do we draw the line that "best fits the data" (and what does best fit mean exactly?)
Lining Them Up
The equation of a line is `y=ax+b`.
`a` is the slope and it controls how "rotated" the line is.
`b` is the y-intercept and it controls where the line is placed.
From here on, we will rename some stuff so that the equation of the line is
`y=ax+b`
`darr`
`h_theta(x)=theta_0+theta_1x`
There are infinitely many possible lines that can be drawn.
So which line best fits the data?
To create a line that will best fit the data points, we need to find values for `theta_0`, `theta_1` that will rotate and position the line so that it is as close as possible to all the data points.
More formally, the line needs to minimize the differences between the actual data points and our predictions. In other words, we want to minimize the error between all of the actual values and all of our predicted values.

We are not minimizing error like what is shown below because we are only interested in minimizing error in the `y`-direction (not in the `x`- and `y`-direction). This is because the `y`-axis is the target value (what we are trying to predict).
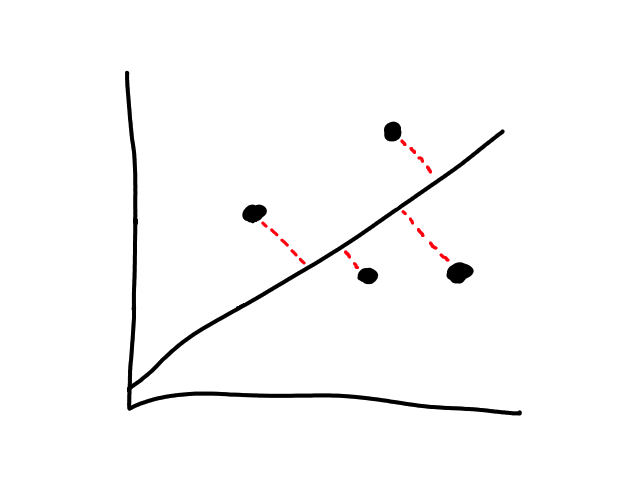
So the idea is that for every line that we can draw, there is going to be some error for each data point. We can add up all those errors to get the total error for that line. So each line we can draw will have a total error. The line with the smallest total error is the best line.
Mathematically, we can define a cost function `J` that represents the total error:
`J(theta_0,theta_1)=1/(2m)sum_(i=1)^m(h_theta(x^((i)))-y^((i)))^2`
for `m` data points
(this is actually the total average error but it doesn't change things since it's still measuring amount of error)
- Why is there a power of `2`?
- The error between the actual value and the predicted value is `h_theta(x^((i)))-y^((i))`. This error can be negative if `h_theta(x^((i)))>y^((i))` (the predicted value is greater than the actual value), so we take the square of it to make it positive. We need positive values for errors so that we can get the total error.
- Another nice side effect is that lines that don't fit the data very well are "penalized" more than lines that do. This is because large errors squared affect the total error more than small errors squared do.
- Why not use absolute value to get positive errors?
- Minimizing a function involves taking the derivative of that function. So the function needs to be differentiable.
- What's with the `1/2`?
- When we take the derivative of that function, the `2`s will cancel out, so it is there to make things cleaner.
If we can find `theta_0`, `theta_1` such that `J(theta_0,theta_1)` is minimized (i.e., the total error is as small as possible), then we have found the values that will allow us to create the line `h_theta(x)=theta_0+theta_1x` that best fits the data.
Gradient Descent
It turns out that the graph of the cost function is bowl shaped.
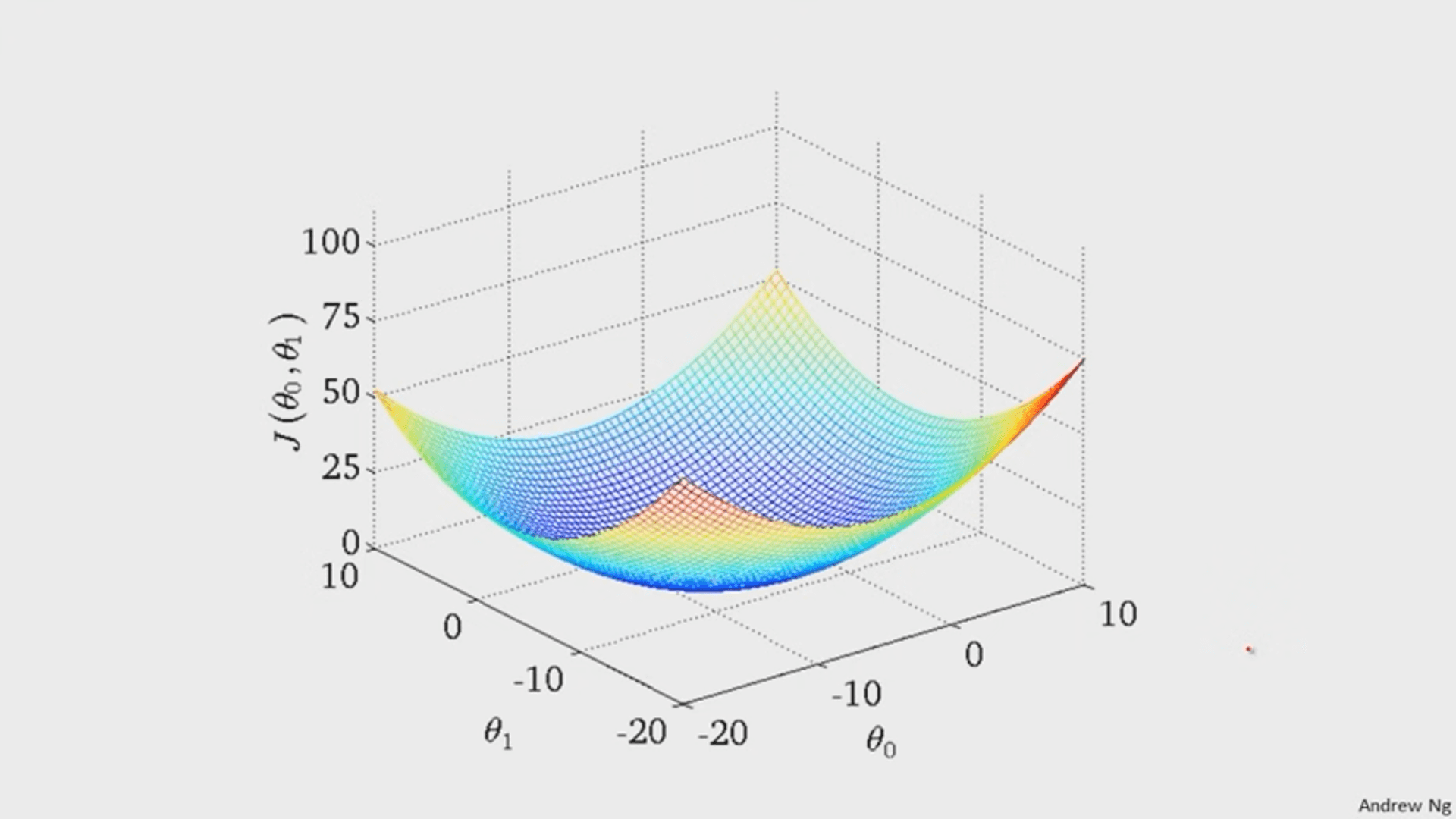
(image from Andrew Ng)
Since the cost function represents total (average) error, the bottommost point of the graph is where the total (average) error is smallest.
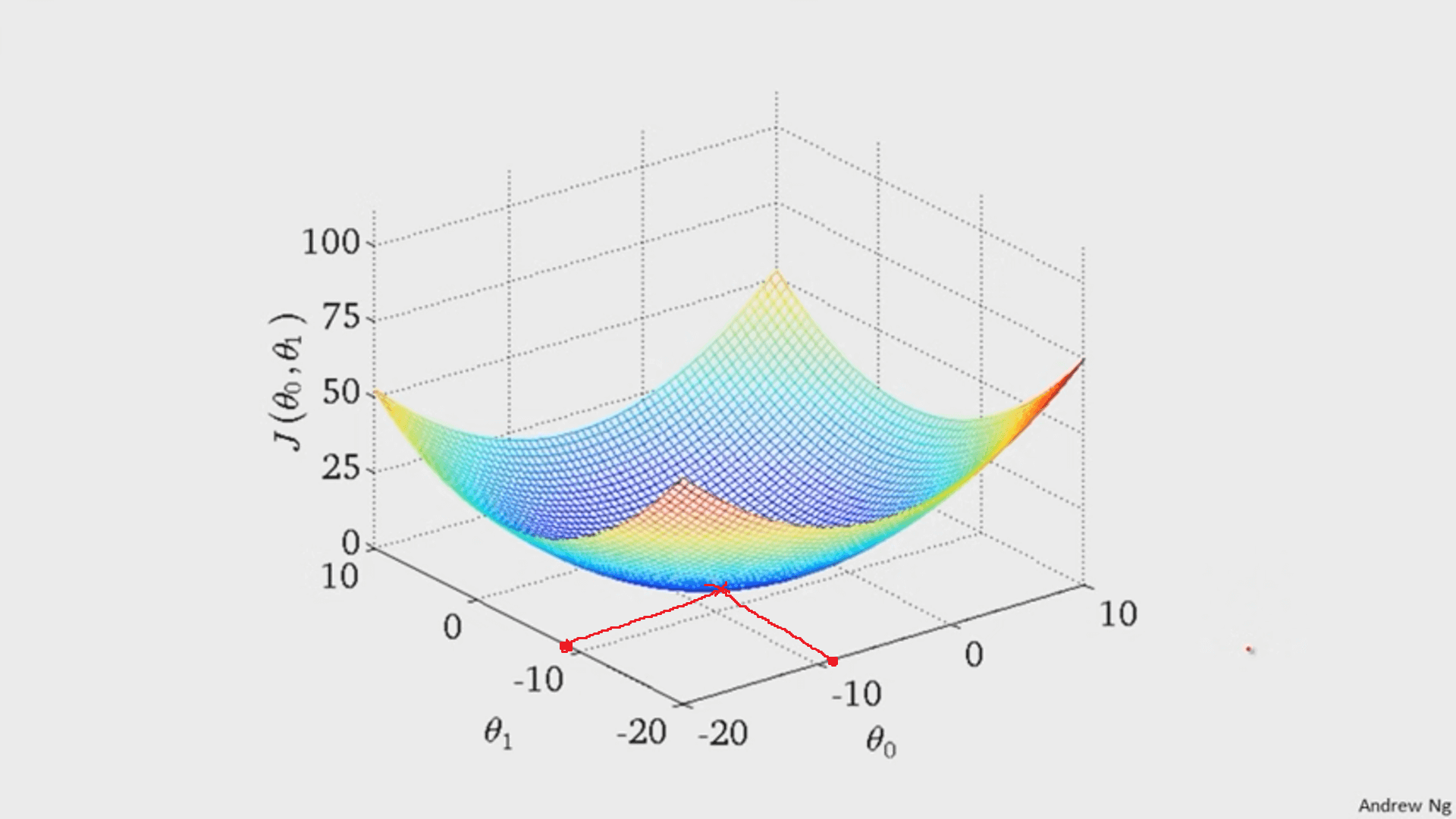
Whatever `theta_0` and `theta_1` are at that point are the values that create the line `h_theta(x)=theta_0+theta_1x` that best fits the data.
To find the minimum of `J(theta_0,theta_1)`, we have to perform gradient descent. The idea of gradient descent is that we start at a random point and take small steps towards the lowest point of the graph until we reach it.
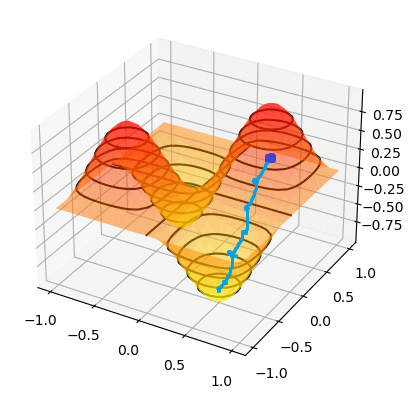
So if we start at the dark blue point, the path it might take to get to the bottommost point might look like the above. And if we start at a different point, it could take a different path and reach a different point.
A gradient is the vector version of slope. Its magnitude is the slope (scalar value).
Mathematically, we find the vector that points in the most negative direction and take a step in that direction.
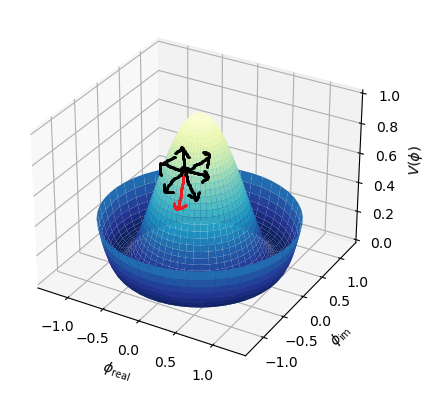
This is called the negative gradient, which points in the direction of the greatest rate of reduction. Taking a step in this direction is the fastest way in which the function decreases.
The gradient is a generalization of the concept of the derivative for functions of several variables.
Since the cost function is bowl shaped, there is only one minimum (the global minimum) so starting gradient descent at any point will always result in ending up at the same point (the minimum).
Starting at a random point `(theta_0, theta_1)`, taking a step means updating `theta_0` and `theta_1` by doing:
`theta_j = theta_j - alphadel/(deltheta_j)J(theta_0, theta_1)`
for `j=0,1`
Programmatically, there are two ways to implement this. The first way is to take both steps simultaneously:
`text(temp)0 = theta_0 - alphadel/(deltheta_0)J(theta_0, theta_1)`
`text(temp)1 = theta_1 - alphadel/(deltheta_1)J(theta_0, theta_1)`
`theta_0 = text(temp)0`
`theta_1 = text(temp)1`
The second way is to take one step at a time:
`text(temp)0 = theta_0 - alphadel/(deltheta_0)J(theta_0, theta_1)`
`theta_0 = text(temp)0`
`text(temp)1 = theta_1 - alphadel/(deltheta_1)J(theta_0, theta_1)`
`theta_1 = text(temp)1`
The first way is more efficient because it steps in the direction of `theta_0` and `theta_1` at the same time while the second way takes one step in `theta_0`, then in `theta_1`.
This is what it looks like from a 2D perspective.
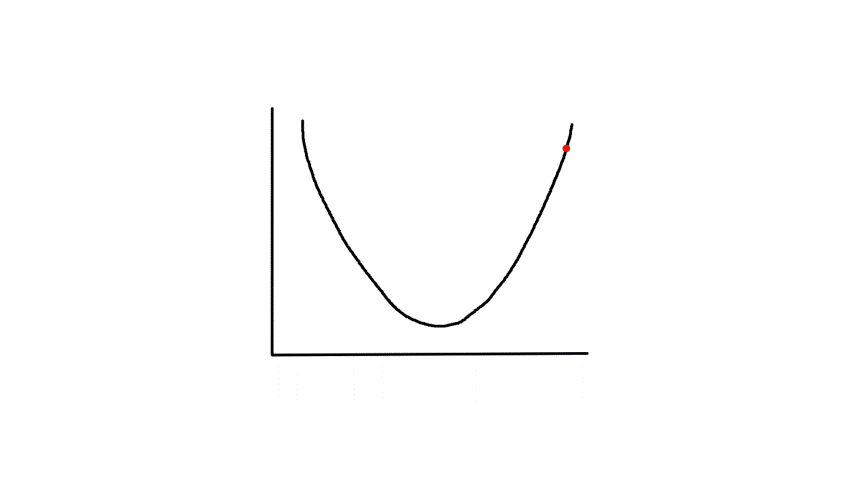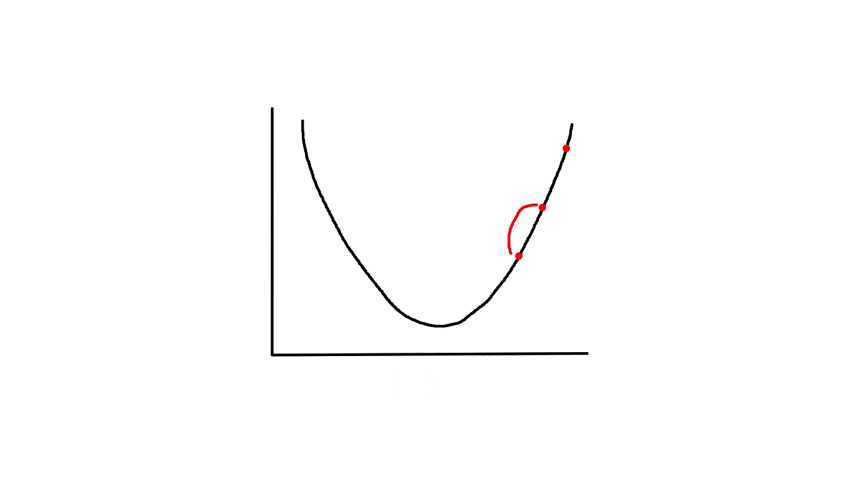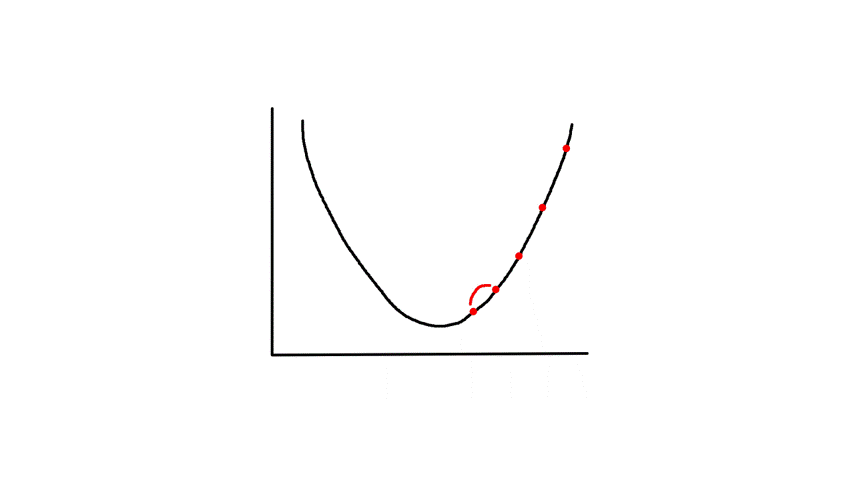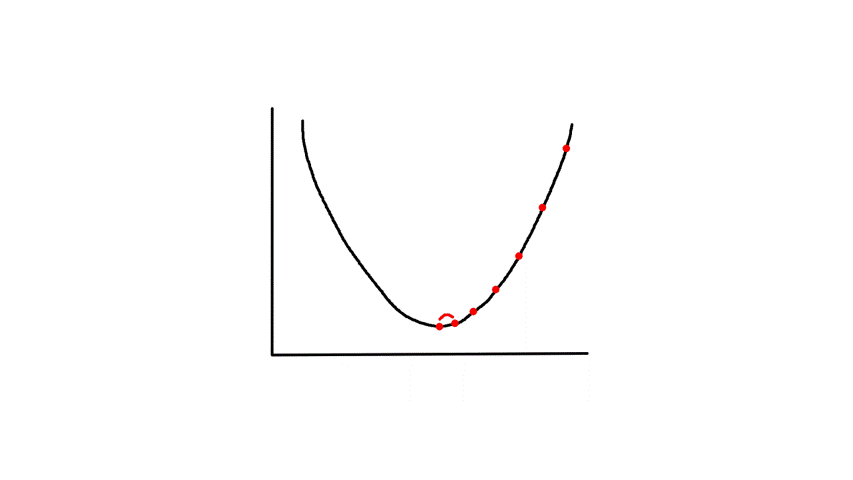
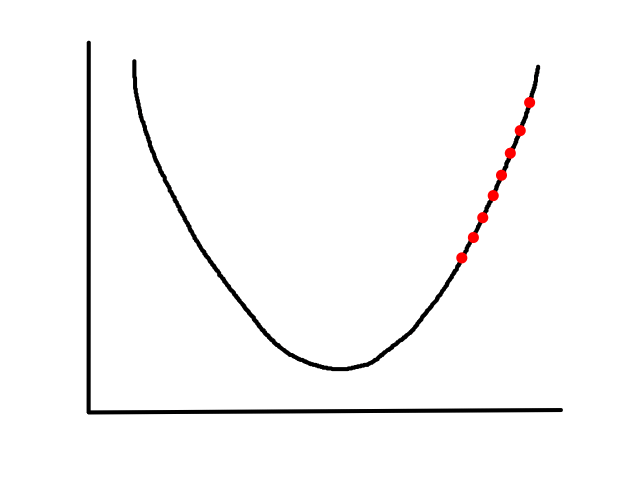
Gradient descent starts from a random point and keeps moving down until it reaches the bottom. The bottom is where the slope is zero, so gradient descent will naturally stop (note how `theta_j`'s updated value is dependent on the slope). Each step naturally gets smaller as it moves further down because the slope gets smaller as it moves down (note how `theta_j`'s updated value is dependent on the slope).
`alpha` is called the learning rate, which controls how big of a step to take. Choosing a value that's too small will take a long time.
(no animation)
Choosing a value that's too big may result in overstepping the minimum. (And in some cases, it may diverge.)

So far we have the equation of a line that best fits the data:
`h_theta(x)=theta_0+theta_1x`
the cost function that represents the total (average) error of a line:
`J(theta_0,theta_1)=1/(2m)sum_(i=1)^m(h_theta(x^((i)))-y^((i)))^2`
and the formula for gradient descent:
`theta_j=theta_j-alphadel/(deltheta_j)J(theta_0,theta_1)`
After plugging everything in we get:
`theta_j=theta_j-alphadel/(deltheta_j)J(theta_0,theta_1)`
`=theta_j-alphadel/(deltheta_j)1/(2m)sum_(i=1)^m(h_theta(x^((i)))-y^((i)))^2`
`=theta_j-alphadel/(deltheta_j)1/(2m)sum_(i=1)^m(theta_0+theta_1x^((i))-y^((i)))^2`
`implies`
`theta_0=theta_0-alpha1/msum_(i=1)^mh_theta(x^((i)))-y^((i))`
`theta_1=theta_1-alpha1/msum_(i=1)^m(h_theta(x^((i)))-y^((i)))cdotx^((i))`
Basically, with gradient descent, we start at a random `theta_0` and `theta_1` and keep moving until we hit the minimum. The values of `theta_0` and `theta_1` at that minimum point are the values that create the line that best fits the data. From a line-drawing perspective, we start with a random line, see how good it is, then use the calculations to find a better line.
All of this is only for one feature though (that's why it's a line). To do linear regression with more than one feature, we need to extend the idea to higher dimensions.
Multiple Features
Let's say we had two features to look at: square footage and number of bedrooms.
| size in square feet | number of bedrooms | price |
| 1000 | 1 | 410,000 |
| 1200 | 2 | 600,000 |
| 1230 | 2 | 620,000 |
| 1340 | 3 | 645,000 |
If we were to graph this, it would be in 3D.
So the equation we would be looking for is:
`h_theta(bb x)=theta_0+theta_1x_1+theta_2x_2`
where `x_1` and `x_2` represent square footage and number of bedrooms
Instead of looking for the best line that fits the data, we would be looking for the best plane that fits the data.
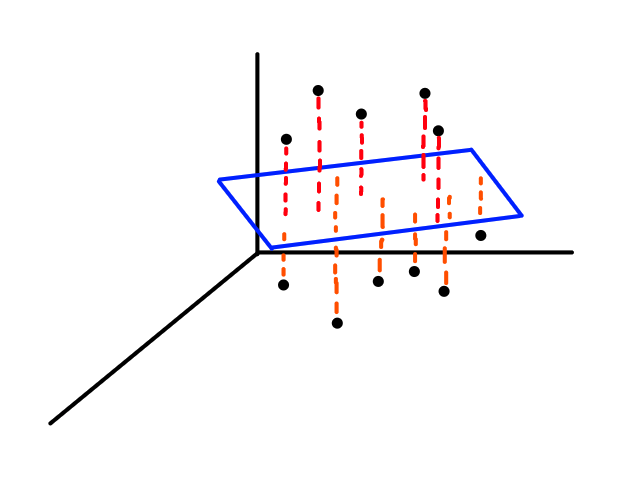
As we work with more features, the object that best fits the data increases in dimensionality.
For `n` features, the equation of the object that best fits the data would be:
`h_theta(bb x)=theta_0+theta_1x_1+theta_2x_2+...+theta_nx_n`
We could define `bb x` to be a vector that contains the values for each feature:
`bb x=[[x_0],[x_1],[vdots],[x_n]]`
and `x_0=1`
and define `theta` to be a vector:
`bb theta=[[theta_0],[theta_1],[vdots],[theta_n]]`
so that the generalizable equation that best fits the data would be:
`h_theta(bb x)=bb theta^Tbb x`
The cost function is mostly the same:
`J(bb theta)=J(theta_0,theta_1,...,theta_n)=1/(2m)sum_(i=1)^m(h_theta(bb x^((i)))-y^((i)))^2`
and so is gradient descent:
`theta_j=theta_j-alpha1/msum_(i=1)^m(h_theta(bb x^((i)))-y^((i)))cdotx_j^((i))`
Notation: `bb x` (bold `x`) and `bb theta` (bold `theta`) are vectors.
If the data isn't normalized, then gradient descent could take a long time. For example, if `theta_1` represented number of bedrooms and `theta_2` represented square footage, then the (contour) graph of the cost function could look like this:
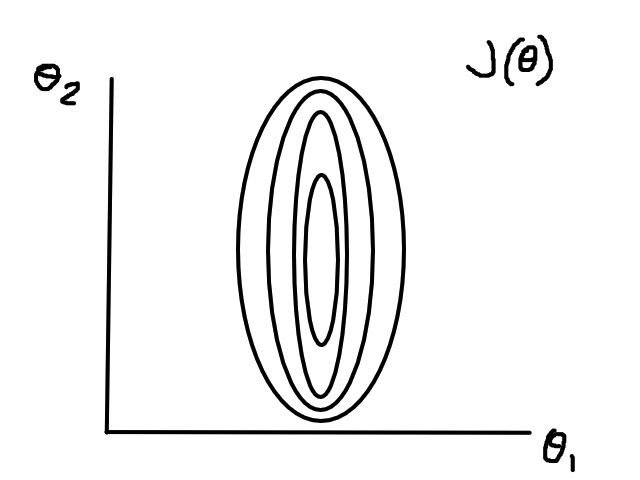
Normalizing would make the (contour) graph of the cost function more circular.
Logistic Regression
Although linear regression is used to predict continuous values, the ideas behind it can be used to build a classifier. Logistic regression is a classification technique that uses linear regression.
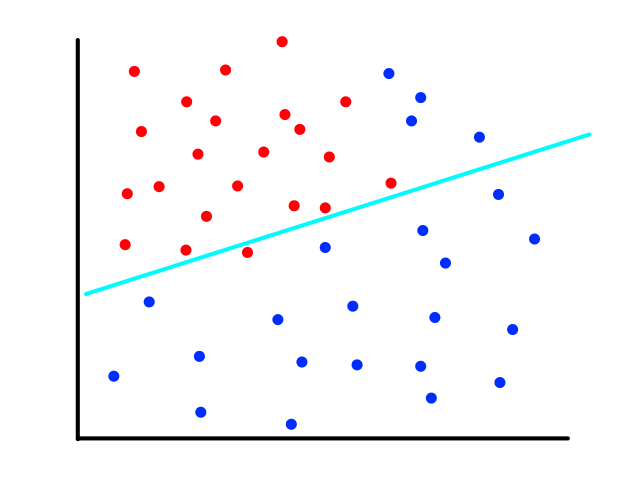
Let's say we had data where the labels can only be 0 or 1. For example, the `x`-axis could be tumor size and the `y`-axis could be whether or not the tumor is malignant (1 means yes and 0 means no).
We could theoretically draw a line that best fits the data like so:
However, since the output can only be 0 (not malignant) or 1 (malignant), the values on the line below `y=0` and above `y=1` are not relevant. For example, if the tumor size is 14, the output is 2. But what does 2 mean? In this simple example, we're assuming that large tumors are malignant, so we would want a size 14 tumor to output to 1 somehow. So we need something other than a straight line for this.
Sigmoid Function
Fortunately, there is a function called the sigmoid function that takes in any input and outputs a value between 0 and 1.
`g(z)=1/(1+e^(-z))`
As `z` moves towards `oo`, the function approaches `1` (since `e^(-z)` approaches `0`). As `z` moves towards `-oo`, the function approaches `0` (since `e^(-z)` approaches `oo`).
We can apply the sigmoid function to our line to effectively transform our line to a curve.
`h_theta(bb x)=bb theta^T bb x`
`g(z)=1/(1+e^(-z))`
`implies`
`g(bb theta^T bb x)=1/(1+e^(-bb theta^T bb x)`
This is what the graph looks like when we apply the sigmoid function to the line that best fit the tumor data:
(It looks like a straight line, but I promise it's "sigmoidy".)
The line that best fit the tumor data was `h_theta(x)=1/6x-1/3`. Applying the sigmoid function to that line, we get:
`g(1/6x-1/3)=1/(1+e^(-(1/6x-1/3)))`
So after applying the sigmoid function to `h_theta`, the new `h_theta` will only output values between 0 and 1. The values should be interpreted as probabilities that inputs will have an output of 1 (e.g., `h_theta(x)=0.7` means that `x` has a 70% chance of being 1). Since we're building a classifier, we should define a threshold to convert those probabilities into categories. For example, if an input has a probability greater than 0.5, then we can classify it as 1.
The threshold doesn't have to be fixed at 0.5. It can change depending on the situation. If we're predicting earthquakes, we want to minimize false alarms, so the threshold should be pretty high (e.g., greater than 0.8). We can reduce the threshold to make the model more sensitive or increase the threshold to make it less sensitive.
All of This for Nothing?!
This process of training a linear regression model, applying the sigmoid function to it, and then discretizing the output is generally not a good idea though as it can lead to poor results since the line that best fits the data (and thus the curve generated from that line) won't generally fit the data well to begin with.
So instead of turning a line into a curve, we should just make a good curve. The setup is still the same:
`h_theta(x)=g(bb theta^T bb x)=1/(1+e^(-bb theta^T bb x))`
where `bb theta=[[theta_0],[theta_1],[vdots],[theta_n]]` and `bb x=[[x_0],[x_1],[vdots],[x_n]]`
To make the curve, we need to find the values of `bb theta`. And just like in linear regression, to find the values of `bb theta`, we need gradient descent!
A New Cost Function
We also need a new cost function. The cost function from before was:
`J(bb theta)=J(theta_0,theta_1,...,theta_n)=1/(2m)sum_(i=1)^m(h_theta(bb x^((i)))-y^((i)))^2`
Before, `h_theta(bb x^((i)))` was linear, so the cost function was a convex bowl. Now, `h_theta(bb x^((i)))` is not linear anymore since we're applying the sigmoid function to it. As a result, the cost function looks something like this:

It is not guaranteed that starting at any point will converge to the global minimum (it might hit one of the other local minimums instead). This is why we need a new cost function, which actually turns out to be:
`J(bb theta)=J(theta_0,theta_1,...,theta_n)=-1/msum_(i=1)^m[y^((i))logh_theta(bb x^((i)))+(1-y^((i)))log(1-h_theta(bb x^((i))))]`
Gradient descent stays the same:
`theta_j=theta_j-alpha1/msum_(i=1)^m(h_theta(bb x^((i)))-y^((i)))cdotx_j^((i))`
Why does this cost function work?
Let's suppose for a single data point, `y=1`. Then the cost function will be:
`-[y^((i))logh_theta(bb x^((i)))+(1-y^((i)))log(1-h_theta(bb x^((i))))]`
`=-[1*logh_theta(bb x^((i)))+(1-1)log(1-h_theta(bb x^((i))))]`
`=-logh_theta(bb x^((i)))`
and the graph of it will look something like:
If we also predicted 1 (i.e., `h_theta(bb x^((i)))=1`), then the cost/error is 0 (i.e., `J(bb theta)=0`). But if we predicted 0, then the cost/error is infinite.
Now let's suppose for a single data point, `y=0`. Then the cost function will be:
`-[y^((i))logh_theta(bb x^((i)))+(1-y^((i)))log(1-h_theta(bb x^((i))))]`
`=-[0*logh_theta(bb x^((i)))+(1-0)log(1-h_theta(bb x^((i))))]`
`=-log(1-h_theta(bb x^((i))))`
and the graph of it will look something like:
If we also predicted 0 (i.e., `h_theta(bb x^((i)))=0`), then the cost/error is 0 (i.e., `J(bb theta)=0`). But if we predicted 1, then the cost/error is infinite.
Polynomial Regression
Sometimes using a line isn't the best fit for the data.
In this case, using a quadratic model would fit the data better.

The same can happen for classification.
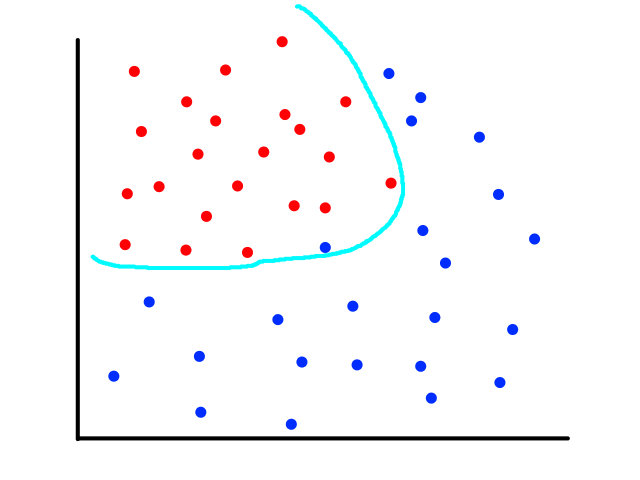
This is usually the case because the output does not always have a linear relationship with the features.
Some examples:
Linear regression with one feature:
`h_theta(x)=theta_0+theta_1x`
Polynomial regression with one feature and order `2`:
`h_theta(x)=theta_0+theta_1x+theta_2x^2`
Logistic regression with two features:
`h_theta(x)=g(theta_0+theta_1x_1+theta_2x_2)`
Polynomial classifier with two features and order `2`:
`h_theta(x)=g(theta_0+theta_1x_1+theta_2x_2+theta_3x_1^2+theta_4x_2^2+theta_5x_1x_2)`
Increasing the order of the model essentially involves adding a new feature to the dataset. If we have a feature `x`, we could multiply each value by itself and put the results in a new column to have `x^2`.
Training a polynomial model is no different than training a linear model. This is because we can encode a polynomial equation as a linear equation. For example, if we have `h_theta(x)=theta_0+theta_1x+theta_2x^2`, we can let `x_2=x^2` so that the new equation becomes:
`h_theta(x)=theta_0+theta_1x+theta_2x_2`
Random Forest
(See "A9) Ensemble Learning" for more background.)
Back to classification! More specifically, back to decision trees! But this time instead of just one tree, there's a whole forest of them. It's an ensemble learning method, so it builds several decision trees and combines their results to make a prediction. Having one big and deep tree usually leads to poor results (since it's usually the result of overfitting), so having many small trees prevents that. It's like having more people solving a problem rather than just one.
In order for all of the trees to work well together, each tree should be different from each other. So each tree will train on a different randomly-generated subset of the training dataset and on a different randomly-generated subset of features.
After each tree makes a prediction, the results are tallied up and the category with the most votes wins.
A random forest is not the same as a bunch of decision trees. A decision tree uses the whole dataset when training, while each decision tree in a random forest uses a subset of the dataset and features when training. All the trees in a bunch of decision trees will look the same (each node will have the same feature), so they will all make the same mistakes. On the other hand, in a random forest, each tree is different so if one tree makes a mistake, the other trees will likely not make the same mistake.
Let's say we had a random forest with two trees:
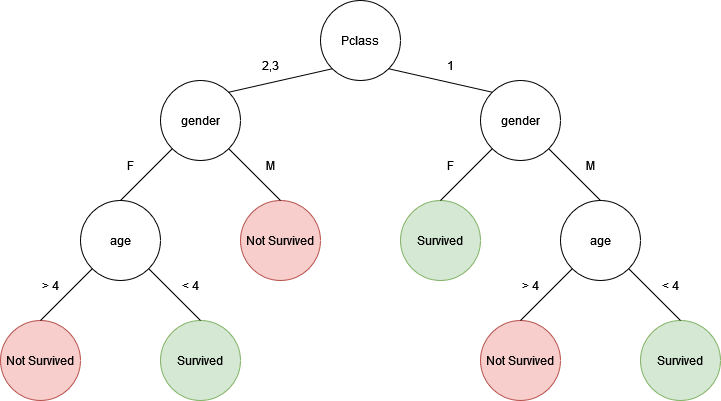
If we predict the fate of an adult female with a 2nd class ticket, the top/left tree would predict that the person did not survive. However, the bottom/right tree would predict that the person did survive. If I wasn't lazy enough to make a third three, the majority of the results would determine the final prediction of the random forest.
Advantages of Random Forest
- one of the most accurate classification algorithms
- very robust to noise and overfitting
- can handle big data with hundreds of features
- can handle missing values
K-Means Clustering
Up to this point, all the datasets we've been looking at have been labeled, i.e., each sample in the training dataset had a classification (e.g., rainy/sunny, survived/not survived) or a value (e.g., price). In some situations, the dataset will be unlabeled (see "A10) Unsupervised Learning" for more background), so it would be more helpful to put similar samples together in groups to see what we can learn from the groupings.
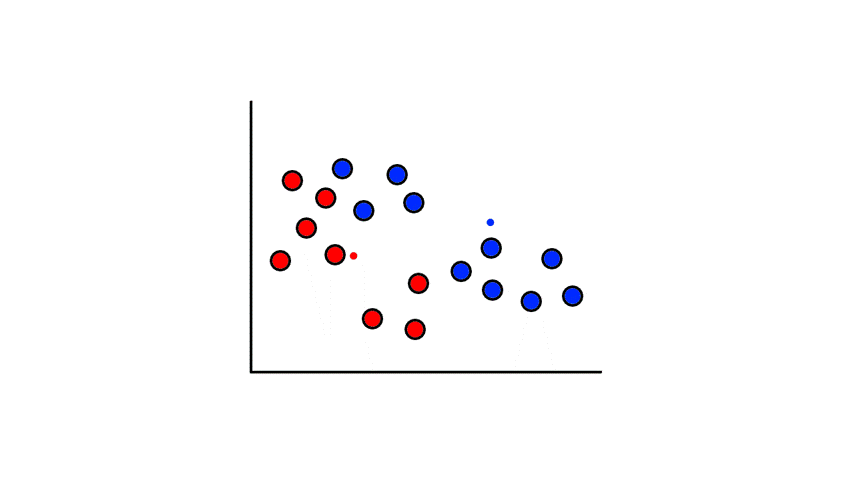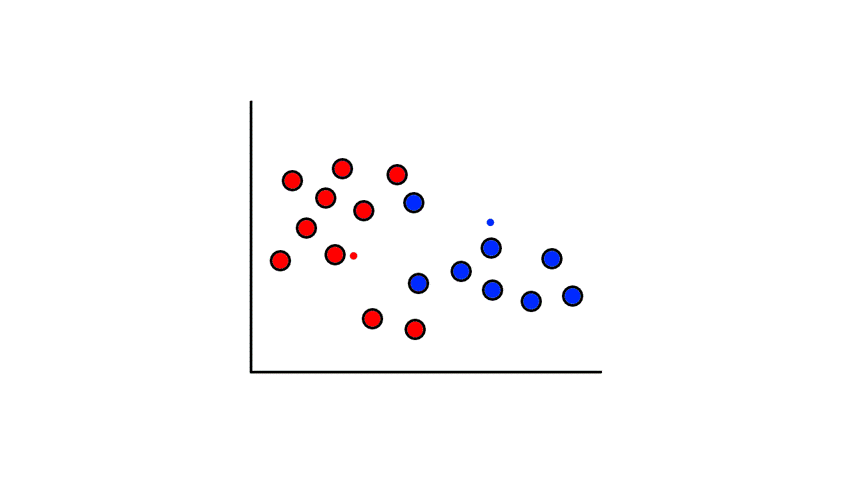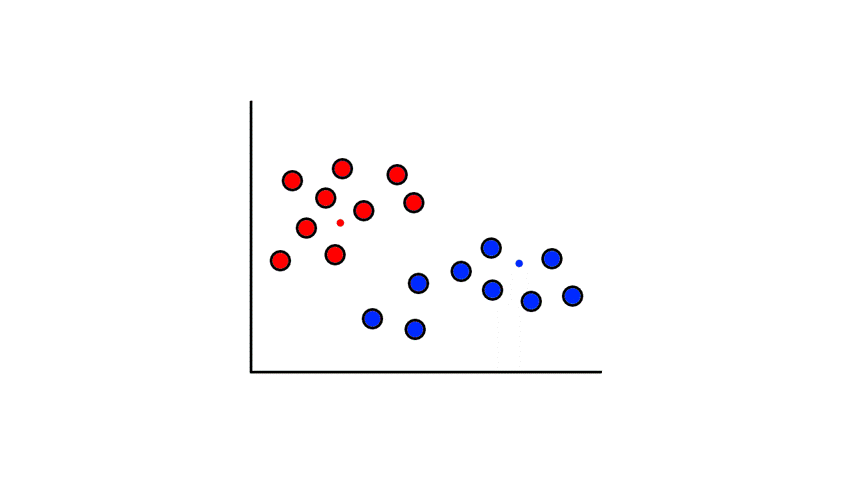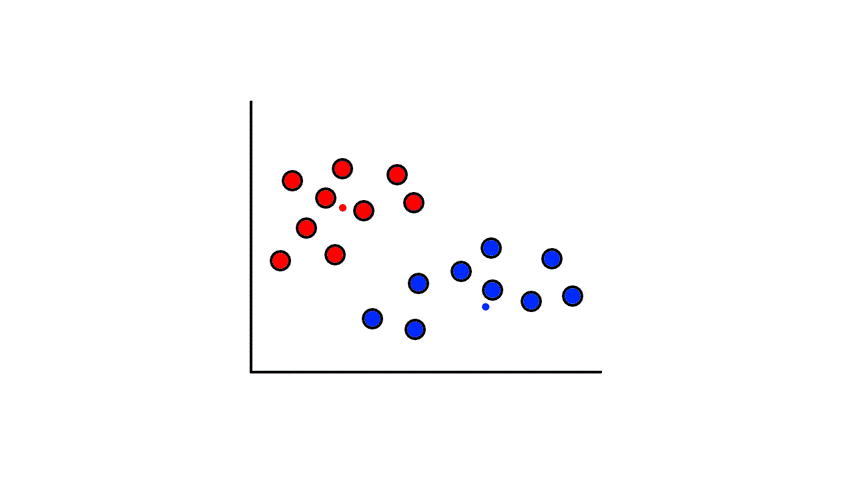
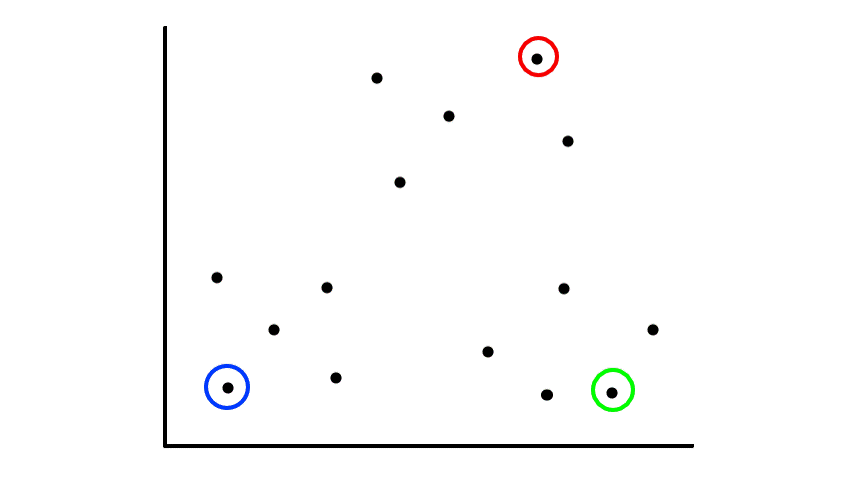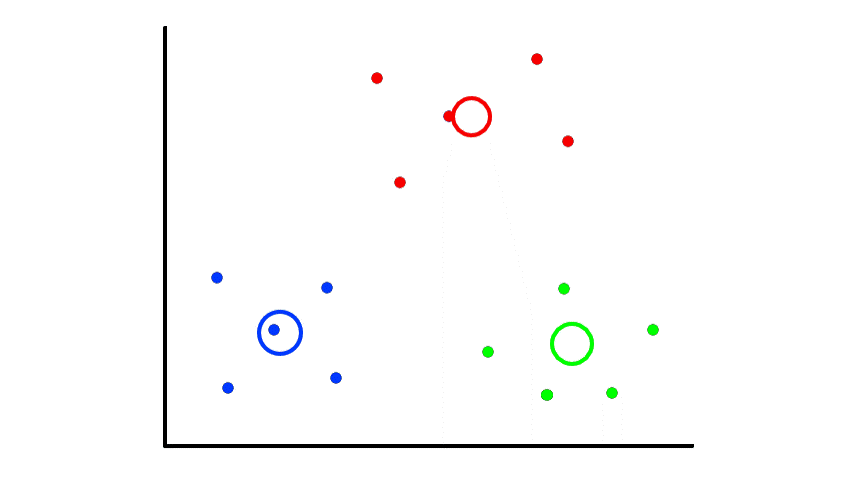
Let's say we had some unlabeled data plotted:
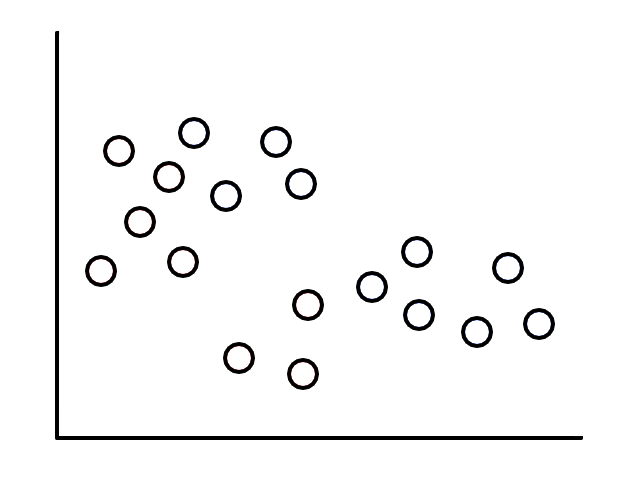
To start, we pick 2 random points (centroids) and group all the points that are closest to that point:
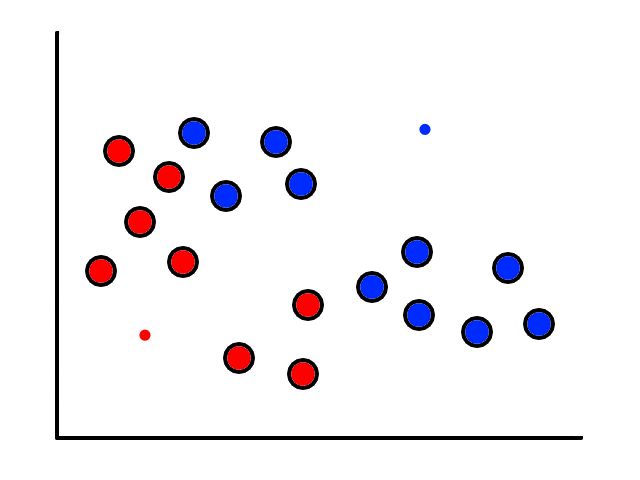
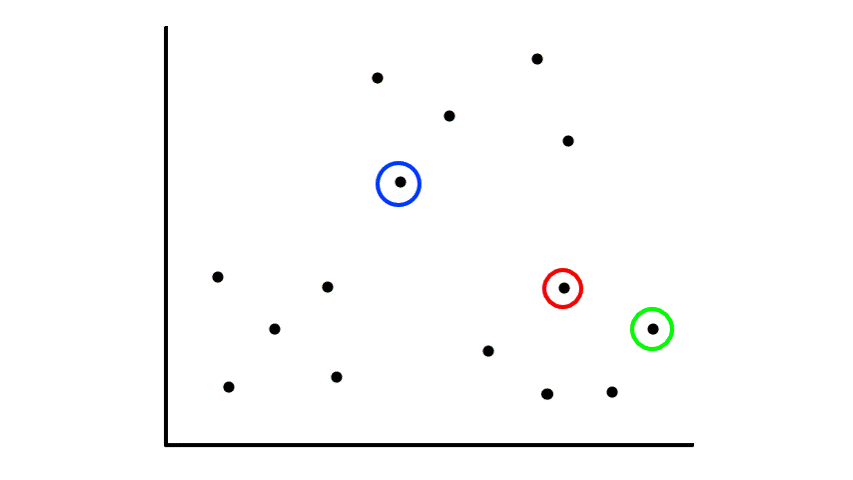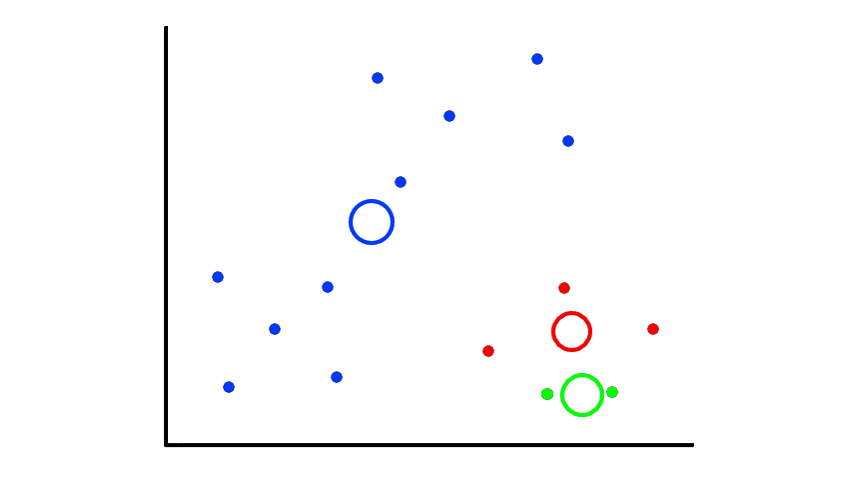
Then we find the center of those points for each group and make them the new centroids. Then we repeat the process until things no longer change.
So now we've divided the data into 2 clusters.
K-Means Clustering algorithm:
- Set `K` random points as initial centroids
- Assign each data sample to the cluster of the nearest centroid point
- Update centroid locations to the mean/average location of the members of the cluster
- Repeat until samples and centroids are stable
Pseudocode:
Let `x^((i))` be the data sample at index `i`. Let `c^((i))` be the index of the cluster to which `x^((i))` is assigned. Let `mu_k` be the centroid of cluster `k`.
(If `x^((1))` is in cluster 5, then `c^((1))=5`)
Randomly initialize `K` cluster centroids `mu_1, mu_2, ..., mu_k`
Cluster assignments: assign `c^((i))` the index of the cluster centroid closest to `x^((i))`, i.e., `c^((i))=min_k||x^((i))-mu_k||^2`
Move centroids: assign `mu_k` the average of points assigned to cluster `k`
Picking random points as the starting centroid can make the process of clustering too long if the random points happened to be far away from the data points. So the data points themselves are usually chosen as the initial centroids to make sure they are close to the data.
If we are lucky, then the results will be good:
But if we are unlucky, then the results will be bad:
So picking random points can lead to random results. The best way to deal with this is to repeat the whole thing several times and select the best clustering results. But what does "best" mean?
Another Cost Function
In this case, "best" means that the total average distance from each data point to its cluster centroid is minimized. Each point should be pretty close to its cluster centroid. We can define the cost function to be:
`J=1/msum_(i=1)^m||x^((i))-mu_(c^((i)))||^2`
where `mu_(c^((i)))` is the cluster centroid for `x^((i))`
So each time perform clustering, we calculate `J` and pick the clustering with the lowest `J`.
Divide and Cluster
Sometimes the data won't be so easily separable, but it would still be helpful to group the data into clusters. For product segmentation, it would be useful to categorize clothing into sizes, like small, medium, large:
Every Cluster Begins With K
In some situations, like product segmentation, we already know how many clusters we want to have. But for situations which we're not familiar with, the ideal number of clusters may vary depending on the situation. To see what the ideal value for `K` is, we could plot the number of clusters against the cost function to see the tradeoff.
In the orange case, there is not much reduction in error after 3 clusters, so we can apply the elbow rule and say 3 clusters is ideal.
Artificial Neural Networks
Since we're training machines to learn from data, why not model them based on the best learning tool around? The human brain. Our brains are able to learn so many different things and respond to so many different inputs that it may seem impossible to try to replicate such a sophisticated system. Do we have to come up with different algorithms for each single thing the human body is capable of doing? After all, seeing an object and hearing sounds are completely different actions from each other, so why would a model that knows how to "see" necessarily know how to "hear"? Well, it turns out that only one general algorithm can be used to learn many different things.
In the 90s, some experiments were done on rats where scientists disconnected the nerves from the rats' ears to their auditory cortex (the part of the brain responsible for processing audio signals) and connected the nerves from their eyes to their auditory cortex instead. (So the part of the brain that "listens" no longer received sounds, but received light instead.) For the first few days, the rats couldn't see or hear anything. But over time, the rats started reacting to light, which meant that the auditory cortex had learned to see. The same results occurred for the somatosensory cortex (the part of the brain responsible for processing things we feel physically) which had also learned to see. This suggested that there is a general structure to the brain that can process different types of data and that learning was more about what type of data is provided.
The way we try to mimic the brain is to try to simulate a neuron (nerve cell) and expand upon that to build a network of neurons. A neuron receives input through dendrites, processes the input in the nucleus, and transmits its output through axon terminals, which are connected to other neurons' dendrites. So the output of one neuron is the input to another neuron.
Artificially, it looks something like:

`x_1`, `x_2`, `x_3` are the inputs to the neuron, which are passed to the model along with the weights `w_1`, `w_2`, `w_3`. The model calculates the linear combination of the inputs (`w_1x_1+w_2x_2+w_3x_3`) and passes it to the activation function `f`, which generates some output `y`. (So `y=f(w_1x_1+w_2x_2+w_3x_3)`.)
In addition to the weighted inputs, we can add another input that repesents bias.
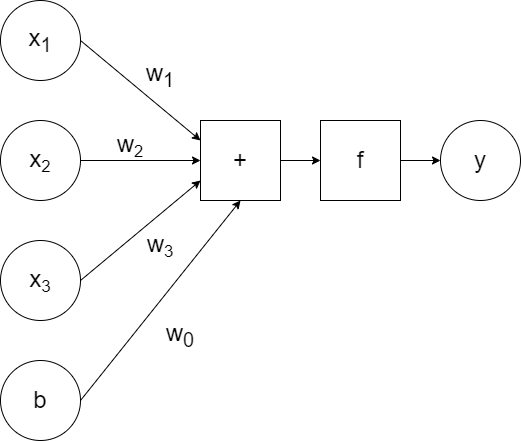
For simplicity, a generic `a` can be used to represent the activation function and the bias can be excluded visually (but included when training):
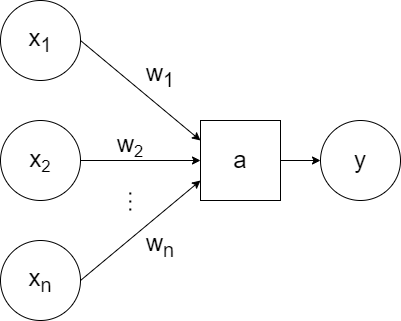
So that represents one neuron. A neural network consists of layers of neurons.

The input layer (also referred to as layer 0) receives and transfers the inputs without doing any computations on them. The last layer is called the output layer. All the layers in between are called the hidden layers. (In this example, there is only one hidden layer.) The connections from one node to another node are weighted connections, where the weight is represented by `w`. The notation reads:
`w_(ij)^((l))`
where `i` is the node it's going to, `j` is the node it's coming from, and `l` is the layer it's going to.
If we were to write out mathematically the value of each node, it would look like this:
`a_1^((1))=g(w_(10)^((1))b^((1))+w_(11)^((1))x_1+w_(12)^((1))x_2+w_(13)^((1))x_3)`
`a_2^((1))=g(w_(20)^((1))b^((1))+w_(21)^((1))x_1+w_(22)^((1))x_2+w_(23)^((1))x_3)`
`a_3^((1))=g(w_(30)^((1))b^((1))+w_(31)^((1))x_1+w_(32)^((1))x_2+w_(33)^((1))x_3)`
`y=a_1^((2))=g(w_(10)^((2))b^((2))+w_(11)^((2))a_1^((1))+w_(12)^((2))a_2^((1))+w_(13)^((2))a_3^((1)))`
assuming `g` is the activation function
And this is just a network with 1 hidden layer. It gets messy quickly, so representing things using vectors keeps things compact.
`bb a^((1))=[[a_1^((1))],[a_2^((1))],[a_3^((1))]]`
`bb W^((1))=[[w_(10)^((1)),w_(11)^((1)),w_(12)^((1)),w_(13)^((1))],[w_(20)^((1)),w_(21)^((1)),w_(22)^((1)),w_(23)^((1))],[w_(30)^((1)),w_(31)^((1)),w_(32)^((1)),w_(33)^((1))]]`
`bb x=[[b],[x_1],[x_2],[x_3]]`
So now the value of each node looks like this:
`bb a^((1))=g(bb W^((1))bb x)`
`y=bb a^((2))=g(bb W^((2))bb a^((1)))`
A neural network with one node in the output layer will output just one thing (e.g., rainy or sunny). But a network can have multiple nodes in the output layer.

This means the network will have multiple outputs. If we give a picture of a tree as input, the outputs can be whether the picture is of a tree or not, where the tree is, and the size of the tree. Or the outputs can be probabilities. If we have four possible types of outputs (e.g., cat, dog, horse, bird), each output can be the probability that it is each of those classes. So an output of `[[0.6],[0.4],[0],[0]]` would mean that there is a 60% chance that the image is of a cat and 40% chance that it is a dog.
You've Activated My Function!
The activation function should be nonlinear. (I believe using a linear function would be like making a line out of a line, i.e., there is no effect.) The simplest function to use is a step function.
Some popular choices include the logistic sigmoid function (yes, the same one back in logistic regression), the rectified linear unit (ReLU) function:
`RELU(x) = {(0 if x lt 0),(x if x >= 0):}`
and Softplus, which is the smooth approximation of ReLU:
`text(Softplus)(x) = log(1+e^x)`
Building Logical Operators
As a reminder, here's the sigmoid function:
Using this as the activation function (represented by `g`), we can simulate all of the binary operators, like logical not, and, or, nor, xor, etc.
The negation (logical not) operator outputs 1 for an input of 0 and outputs 0 for an input of 1. We can simulate the negation operator with the following neural network:
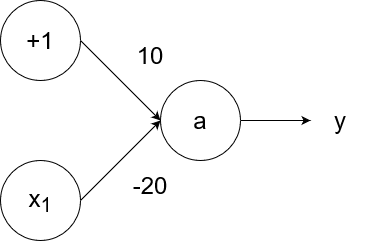
So `y=g(10-20x_1)`.
- If `x_1=1`, then the output is `y=g(10-20*1)=g(10-20)=g(-10)=0`.
- If `x_1=0`, then the output is `y=g(10-20*0)=g(10-0)=g(10)=1`.
The logical and operator takes in two inputs. If both of them are 1, then the output is 1. If at least one of the inputs is 0, then the output is 0.
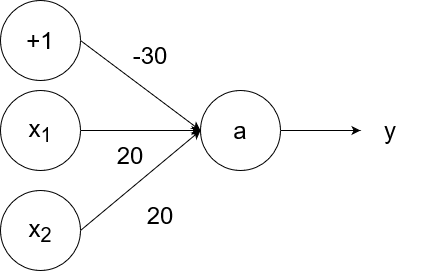
So `y=g(20x_1+20x_2-30)`.
- If `x_1=1` and `x_2=1`, then the output is `y=g(20*1+20*1-30)=g(40-30)=g(10)=1`.
- If `x_1=1` and `x_2=0`, then the output is `y=g(20*1+20*0-30)=g(20-30)=g(-10)=0`.
- If `x_1=0` and `x_2=1`, then the output is `y=g(20*0+20*1-30)=g(20-30)=g(-10)=0`.
- If `x_1=0` and `x_2=0`, then the output is `y=g(20*0+20*0-30)=g(0-30)=g(-30)=0`.
The logical or operator takes in two inputs. If both of them are 0, then the output is 0. If at least one of the inputs is 1, then the output is 1.
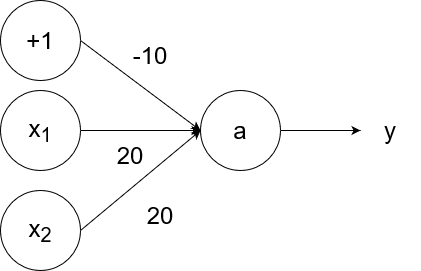
So `y=g(20x_1+20x_2-10)`.
- If `x_1=1` and `x_2=1`, then the output is `y=g(20*1+20*1-10)=g(40-10)=g(30)=1`.
- If `x_1=1` and `x_2=0`, then the output is `y=g(20*1+20*0-10)=g(20-10)=g(10)=1`.
- If `x_1=0` and `x_2=1`, then the output is `y=g(20*0+20*1-10)=g(20-10)=g(10)=1`.
- If `x_1=0` and `x_2=0`, then the output is `y=g(20*0+20*0-10)=g(0-10)=g(-10)=0`.
The logical nand (not and) operator takes in two inputs. If both of them are 1, then the output is 0. If at least one of the inputs is 0, then the output is 1.
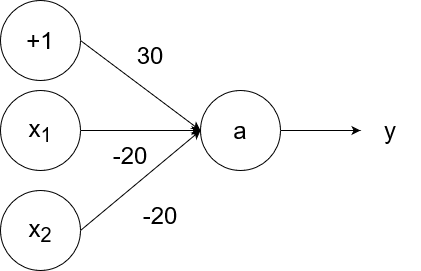
So `y=g(-20x_1-20x_2+30)`.
- If `x_1=1` and `x_2=1`, then the output is `y=g(-20*1-20*1+30)=g(-40+30)=g(-10)=0`.
- If `x_1=1` and `x_2=0`, then the output is `y=g(-20*1-20*0+30)=g(-20+30)=g(10)=1`.
- If `x_1=0` and `x_2=1`, then the output is `y=g(-20*0-20*1+30)=g(-20+30)=g(10)=1`.
- If `x_1=0` and `x_2=0`, then the output is `y=g(-20*0-20*0+30)=g(0+30)=g(30)=1`.
The logical nor (not or) operator takes in two inputs. If both of them are 0, then the output is 1. If at least one of the inputs is 1, then the output is 0.
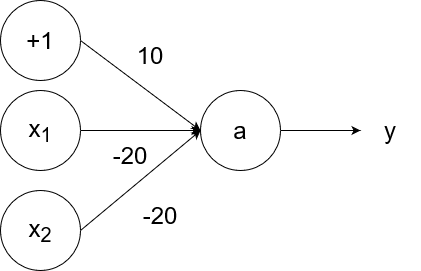
So `y=g(-20x_1-20x_2+10)`.
- If `x_1=1` and `x_2=1`, then the output is `y=g(-20*1-20*1+10)=g(-40+10)=g(-30)=0`.
- If `x_1=1` and `x_2=0`, then the output is `y=g(-20*1-20*0+10)=g(-20+10)=g(-10)=0`.
- If `x_1=0` and `x_2=1`, then the output is `y=g(-20*0-20*1+10)=g(-20+10)=g(-10)=0`.
- If `x_1=0` and `x_2=0`, then the output is `y=g(-20*0-20*0+10)=g(0+10)=g(10)=1`.
Being able to simulate logical operators can come in handy for some classification problems. Consider this dataset:
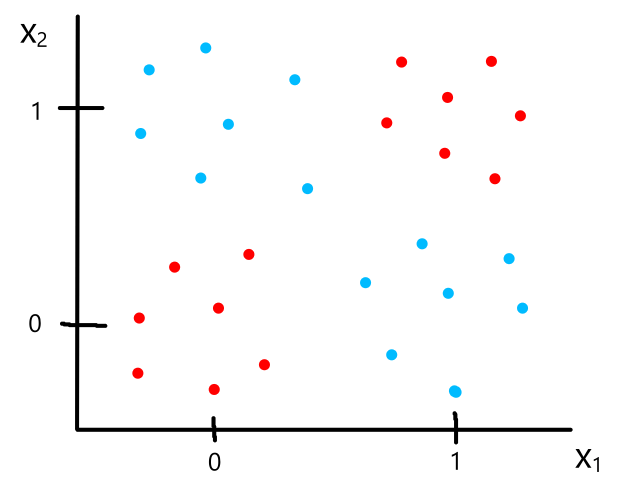
where we can interpret red being 1 and blue being 0.
It would be impossible to use a linear model to perform classification. It's possible to use a higher-order model, but it is much cleaner to use a logical operator in this case. Notice that when both inputs are the same number, then the output is 1. When both inputs are different numbers, then the output is 0. This is actually how the xnor (exclusive not or) operator works.
So `y=x_1text( XNOR )x_2`, which is equivalent to `(x_1text( AND )x_2)text( OR )(x_1text( NOR )x_2)`. We have the neural networks to simulate and, or, and nor already, so we can combine them to simulate xnor.
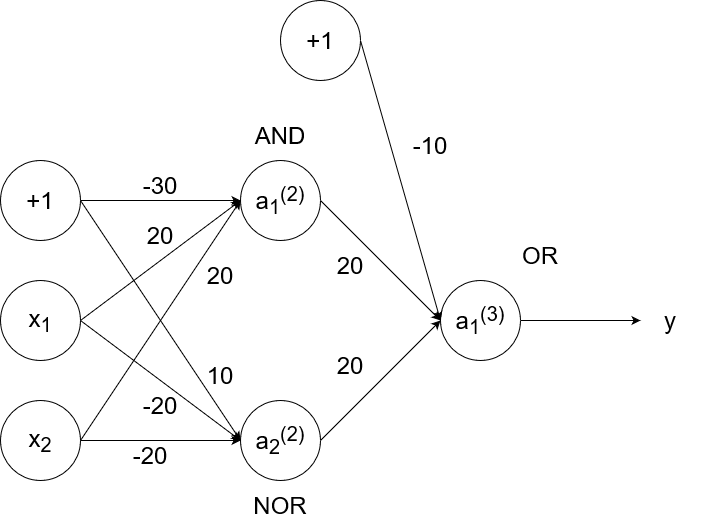
- If `x_1=1` and `x_2=1`, then `a_1^((2))=1`, `a_2^((2))=0`, and `a_1^((3))=y=1`.
- If `x_1=1` and `x_2=0`, then `a_1^((2))=0`, `a_2^((2))=0`, and `a_1^((3))=y=0`.
- If `x_1=0` and `x_2=1`, then `a_1^((2))=0`, `a_2^((2))=0`, and `a_1^((3))=y=0`.
- If `x_1=0` and `x_2=0`, then `a_1^((2))=0`, `a_2^((2))=1`, and `a_1^((3))=y=1`.
The Cost Function Is Back!
When a neural network is trained, it tries to find the best structure. This means it tries to find the best weights to use to connect each of the nodes. To determine what is "best", we need to bring back the cost function that represents the error and minimize the function.
The cost function for neural networks turns out to be very similar to the cost function for logistic regression. This is because neural networks can be seen as an advanced version of logistic regression.
If we look at just the output layer of a neural network, we can see that it receives some inputs multiplied by some weights. Using the sigmoid function as the activation function, this is the same as logistic regression where the inputs are the features and the weights are the `theta`s.
The inputs to logistic regression are the features themselves, while the inputs to the output layer of a neural network are the outputs from the previous layers, which aren't equal to the features at that point. In fact, the inputs to the output layer are new "features" that the neural network created to best learn and represent the data. So the hidden layers of a neural network can be seen as a feature learning process.
It's kind of like seeing a person with our eyes. The raw light that first reaches our eyes is like the input layer. Then as the light signals move through our brain, it processes them so that we see the silhouette of a person. Then they move on to the next layer so that we see a face. Then they move on to the final layer so that we recognize that the face belongs to our friend (or enemy if you roll that way).
The cost function for logistic regression is:
`J(bb theta)=-1/msum_(i=1)^m[y^((i))logh_theta(bb x^((i)))+(1-y^((i)))log(1-h_theta(bb x^((i))))]`
The cost function for neural networks is:
`J(bb W)=-1/msum_(i=1)^msum_(k=1)^K[y_k^((i))logh_W(bb x^((i)))_k+(1-y_k^((i)))log(1-h_W(bb x^((i))))_k]`
where `y^((i))` is the actual label for the `i^(th)` sample,
`h_W(x^((i)))` is the predicted label for the `i^(th)` sample,
`m` is the number of training samples,
`K` is the number of outputs
Overfitting can happen if the network is too complex. So we can add a regularization term to the cost function so that the weights are minimized as well:
`lambda/(2m)sum_(l=1)^(L-1)sum_(i=1)^(s_l)sum_(j=1)^(s_l+1)(w_(ij)^((l)))^2`
The result is usually that some of the weights get minimized to zero, which removes a connection between nodes. So a neural network could end up looking like this:

A neural network that is overfit is like a brain that overthinks. Having too many connections between neurons results in the brain being less effective and efficient, so the brain also does regularization to make it simpler. This is called synaptic pruning.
Backpropagation: I put my inputs, flip it and reverse it
When building a neural network, we decide how many layers and nodes per layer to use. The part that gets learned by the machine is what weights to use. Backpropagation is a systematic way to train a neural network so it can learn the weights.
In the beginning, we start with random weights. One training sample is used as input and the generated output (denoted as `o`) is compared with the actual output (denoted as `y`). Using the cost function, the error is calculated between the generated output and the actual output, and this error is propagated backwards through the network to update the weights. And then this process is repeated for all training samples.
For simplicity, we can assume that the cost function is `J=1/2(y-o)^2`. Also, we can assume that the activation function being used is the sigmoid function: `g(z)=1/(1+e^(-z))`. Then the gradient error would be
`delta=(partialJ)/(partialz)=(y-o)o(1-o)`
(the `o(1-o)` term comes from the derivative of the sigmoid function)
Then we use that gradient error to update the weights:
`w_(ij)^((l))(text(new))=w_(ij)^((l))(text(old))+alphadeltaa_i^((l-1))`
where `alpha` is the learning rate*
All of this was just for the output layer. To calculate the gradient error for the hidden layers, we use a different equation:
`delta_i^((l-1))=[sumw_(ji)^((l))delta_j^((l))]a_i^((l-1))(1-a_i^((l-1)))`
And to update the weights:
`w_(ij)^((l))(text(new))=w_(ij)^((l))(text(old))+alphadelta_i^((l))a_i^((l-1))`
*this learning rate is similar to the learning rate in gradient descent. In fact, backpropagation is a sort of different version of gradient descent (much like the output layer is a different version of logistic regression).
In gradient descent, we had this:
`theta_j = theta_j - alphadel/(deltheta_j)J(theta_0, theta_1)`
where that formula was used to take steps towards the minimum of the cost function `J`.
In backpropagation, we have this:
`w_(ij)^((l))(text(new))=w_(ij)^((l))(text(old))+alphadelta_i^((l))a_i^((l-1))`
It looks similar to taking steps, except we're tuning the weights. It's more like baking/cooking where we're adjusting how much of each ingredient is being added. We nudge the weights in the direction that minimizes error, so that's why we use the gradient error to update the weights.
Backpropagation can be seen as an implementation of the chain rule for derivatives. We can view each layer of a neural network as a function:

So the output would be:
`o=f(g(h(x)))`
Since we used random weights, there will be some error. For simplicity, let's use `(o-y)^2` to calculate error. If we want to minimize this error, then we take the derivative of it, which turns out to be:
`2(o-y)o'`
This means that in order to minimize error, we have to calculate the derivative of the output `o`. Since `o=f(g(h(x)))`, the derivative of `o` (by the chain rule) is:
`f'(g(h(x)))cdotg'(h(x))cdoth'(x)`
Well it turns out that when we calculate the gradient error and backpropagate it to the previous layers, it is similar to computing the derivative above.
This is an example of backpropagation in action. We will use the sigmoid function `g(z)=1/(1+e^(-z))` as the activation function and use the learning rate `alpha=1`. Suppose we had this neural network with these weights: (biases excluded for simplicity)
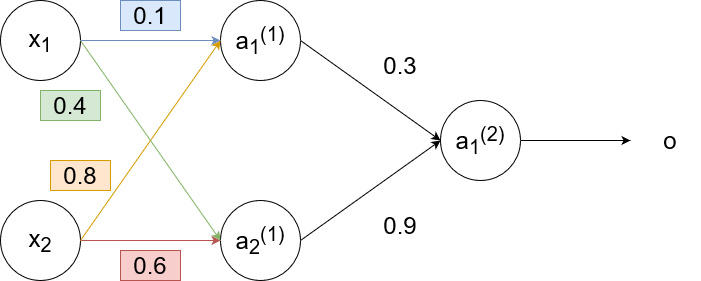
For the training sample, suppose we have `x_1=0.35`, `x_2=0.9`, and `y=0.5`. Then
`a_1^((1))=g(w_(11)^((1))x_1+w_(12)^((1))x_2)=g(0.1cdot0.35+0.8cdot0.9)~~0.68`
`a_2^((1))=g(w_(21)^((1))x_1+w_(22)^((1))x_2)=g(0.6cdot0.9+0.4cdot0.35)~~0.6637`
`o=a_1^((2))=g(w_(11)^((2))a_1^((1))+w_(12)^((2))a_2^((1)))=g(0.3cdot0.68+0.9cdot0.6637)~~0.69`
There is some error in the generated output (0.69) since the actual output should be 0.5. We calculate the gradient error to get:
`delta=(y-o)o(1-o)=(0.5-0.69)cdot0.69cdot(1-0.69)=-0.0406`
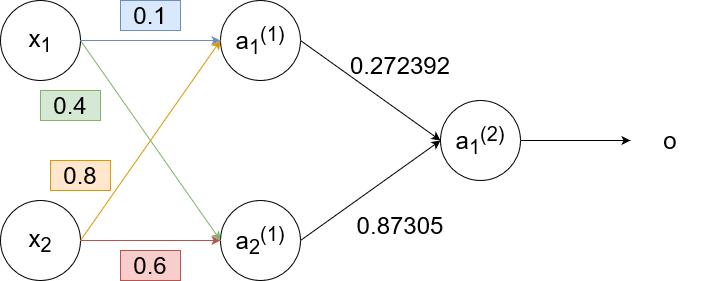
Now we backpropagate the error to the second layer. We update the weights using the gradient error:
`w_(11)^((2))(text(new))=w_(11)^((2))+alphadeltaa_1^((1))=0.3+1cdot-0.0406cdot0.68=0.272392`
`w_(12)^((2))(text(new))=w_(12)^((2))+alphadeltaa_2^((1))=0.9+1cdot-0.0406cdot0.6637=0.87305`
and calculate the gradient error to use for the next (previous? 🤔) layer:
`delta_1^((1))=[w_(11)^((2))delta]a_1^((1))(1-a_1^((1)))=[0.3cdot-0.0406]cdot0.68cdot(1-0.68)=-0.00265`
`delta_2^((1))=[w_(12)^((2))delta]a_2^((1))(1-a_2^((1)))=[0.9cdot-0.0406]cdot0.6637cdot(1-0.6637)=-0.00815`
So now the neural network looks like this:
Now we backpropagate to the first layer:
`w_(11)^((1))(text(new))=w_(11)^((1))+alphadelta_1^((1))x_1=0.1+1cdot-0.00265cdot0.35=0.099`
`w_(12)^((1))(text(new))=w_(12)^((1))+alphadelta_1^((1))x_2=0.8+1cdot-0.00265cdot0.9=0.7976`
`w_(21)^((1))(text(new))=w_(21)^((1))+alphadelta_2^((1))x_1=0.4+1cdot-0.00815cdot0.35=0.3971`
`w_(22)^((1))(text(new))=w_(22)^((1))+alphadelta_2^((1))x_2=0.6+1cdot-0.00815cdot0.9=0.5926`
So the neural network finally looks like this:
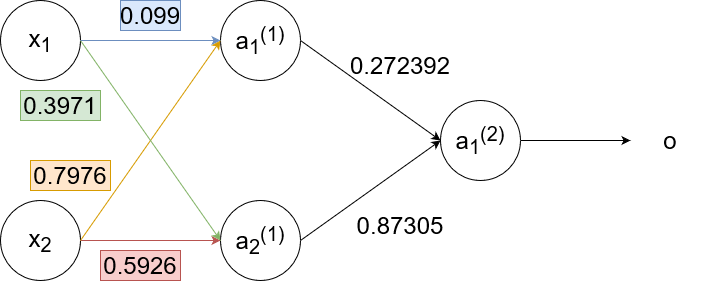
Notice how `delta_1^((1))` and `delta_2^((1))` are smaller than `delta`. The further we backpropagate, the smaller the `delta`s become, which results in the weights staying pretty much the same. This effect is called the "vanishing gradient".
Deep Learning
The very simple explanation of deep learning is that it is a wide and deep neural network, meaning that it has many many neurons and layers. While deep learning does use neural networks, the main characteristic of deep learning is that it tries to learn what features are important, instead of us giving the neural network the features. Sometimes, the features that the network learns are better than the features we provide to it. And in some cases, it can be time expensive to create the features ourselves (e.g., for unsupervised learning).
Because the neural network is often wide and deep, there are a lot of weights for it to learn, so it needs a lot of data to train with. In fact, deep learning generally outperforms other machine learning algorithms only when the dataset is large enough.
Vanishing Gradient: Do You See It? Now You Don't
Neural networks are trained using backpropagation, which is the process of calculating the error and using that calculation to update the weights in each layer. The issue with backpropagation is that usually the `delta`s are very very small, which results in very very little impact on the weights. Furthermore, the `delta`s get smaller as backpropagation continues, so the first few layers remain virtually unchanged. The first few layers are important because their outputs are used for the rest of the layers, so the first few layers need to be on point. This problem is greatly exacerbated by the fact that deep learning uses wide and deep neural networks.
Activation Function
The `delta`s are determined by the activation function, so using a different activation function could help. The sigmoid function is not that great of a function to use because it returns a value between 0 and 1. Multiplying a weight by a number between 0 and 1 isn't going to change it much. A better function to use is ReLU, since it returns a value greater than 1.
Restricted Boltzmann Machines
Another way to solve the vanishing gradient problem is to use a different type of structure that isn't so wide and deep. RBM only uses two layers, but they are bidirectional, meaning they pass their inputs and outputs back and forth to each other. The first layer is the "visible layer" and the second layer is the "hidden layer".

The inputs are passed through the layers, which will produce some output. The output is then fed backwards through the network to try and reproduce the original input as close as possible. After repeating this process several times, the network will learn what the best weights are to represent the input data.
Deep Belief Networks
So an RBM can optimize a pair of layers. What if we apply this RBM idea to every layer in a deep neural network? Would that mean that we would have optimized layers? Yes, actually. A deep belief network (DBN) is a deep neural network where its layers are RBMs.
Instead of starting with random weights, we are now starting with optimized weights. So backpropagation will be much faster.
Deep Autoencoder
#dimensionalityreduction
We can combine RBMs to get a DBN. We can also combine DBNs to get a deep autoencoder. A deep autoencoder is an unsupervised deep neural network that is useful for extracting the most important part of data. It is made up of two DBNs: one used for encoding data and the other used for decoding data. The encoding network learns the best way to compress the input and the decoding network is used to reconstruct the data. Minimizing the difference between the original input data and the reconstruction results in a network that knows how to compress the data in the best way without significant data loss.

Convolutional Neural Networks
Convolutional neural networks are a type of deep neural network that is commonly used for image classification and object recognition. Regular neural networks don’t work well with images because images have high dimensionality. Each pixel is considered a feature, so an image that is 100 x 100 pixels already has 30,000 features. This means that there are at least 30,000 weights to train in the first layer, which is not ideal.
CNNs are designed to reduce dimensionality by extracting patterns from images, so that all the pixels don’t need to be processed. Some of the layers in a CNN are called convolutional layers, which are used for feature extraction. There are also pooling layers, which are used for dimensionality reduction.
Edge Detection
In order to identify objects in images, we need to be able to detect edges. Convolution is a process that allows us to do this. In convolution, a filter (a.k.a. kernel) is applied to each pixel of the image. Applying the filter puts a weight on each pixel, and these weights are used to determine whether there is an edge at that pixel or not.
Let's suppose we have this image:
| 1 | 1 | 1 | 0 | 0 |
| 0 | 1 | 1 | 1 | 0 |
| 0 | 0 | 1 | 1 | 1 |
| 0 | 0 | 1 | 1 | 0 |
| 0 | 1 | 1 | 0 | 0 |
and this filter:
| 1 | 0 | 1 |
| 0 | 1 | 0 |
| 1 | 0 | 1 |
In the first step of convolution, we start with the top-left pixels. Applying the filter means multiplying each pixel by the corresponding square in the filter:
| 1*1 | 1*0 | 1*1 | 0 | 0 |
| 0*0 | 1*1 | 1*0 | 1 | 0 |
| 0*1 | 0*0 | 1*1 | 1 | 1 |
| 0 | 0 | 1 | 1 | 0 |
| 0 | 1 | 1 | 0 | 0 |
And then adding the products together:
`1xx1+1xx0+1xx1+0xx0+1xx1+1xx0+0xx1+0xx0+1xx1=4`
| 4 | ||
Then we move the filter over to the next set of pixels and repeat the same process:
| 1 | 1*1 | 1*0 | 0*1 | 0 |
| 0 | 1*0 | 1*1 | 1*0 | 0 |
| 0 | 0*1 | 1*0 | 1*1 | 1 |
| 0 | 0 | 1 | 1 | 0 |
| 0 | 1 | 1 | 0 | 0 |
`1xx1+1xx0+0xx1+1xx0+1xx1+1xx0+0xx1+1xx0+1xx1=3`
| 4 | 3 | |
After applying the filter to the whole image, we get the convolved image:
| 4 | 3 | 4 |
| 2 | 4 | 3 |
| 2 | 3 | 4 |
The example above was just some random filter, but using a specific filter allows us to detect edges. Consider this black and white image which has an edge right down the middle:
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
And this filter:
| 1 | 0 | -1 |
| 1 | 0 | -1 |
| 1 | 0 | -1 |
For the first step of convolution:
| 5*1 | 5*0 | 5*-1 | 5 | 0 | 0 | 0 | 0 |
| 5*1 | 5*0 | 5*-1 | 5 | 0 | 0 | 0 | 0 |
| 5*1 | 5*0 | 5*-1 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
The result is:
| 0 | |||||
The second step of convolution will be the same since the pixel values are the exact same.
| 0 | 0 | ||||
For the third step of convolution:
| 5 | 5 | 5*1 | 5*0 | 0*-1 | 0 | 0 | 0 |
| 5 | 5 | 5*1 | 5*0 | 0*-1 | 0 | 0 | 0 |
| 5 | 5 | 5*1 | 5*0 | 0*-1 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
The result is:
| 0 | 0 | 15 | |||
In the end, we will have this result:
| 0 | 0 | 15 | 15 | 0 | 0 |
| 0 | 0 | 15 | 15 | 0 | 0 |
| 0 | 0 | 15 | 15 | 0 | 0 |
| 0 | 0 | 15 | 15 | 0 | 0 |
Notice how the nonzero values are right down the middle, exactly where the edge was at in the original image.
There are many different types of filters that can detect different types of edges. Here are a few:
| 1 | 0 | -1 |
| 1 | 0 | -1 |
| 1 | 0 | -1 |
Vertical Edge Filter
| 1 | 1 | 1 |
| 0 | 0 | 0 |
| -1 | -1 | -1 |
Horizontal Edge Filter
| 0 | 1 | 0 |
| 1 | 0 | -1 |
| 0 | -1 | 0 |
Diagonal Edge Filter (top right to bottom left)
| 0 | 1 | 0 |
| -1 | 0 | 1 |
| 0 | -1 | 0 |
Diagonal Edge Filter (top left to bottom right)
We don't manually choose which filters to apply. We let the neural network learn what the most important edges are and it will automatically come up with the best set of filters to detect those edges. The values for the filters can be thought of as weights of a neural network that are learned.
Notice that the output of convolution is a smaller image. In fact, after convolution, the size of the result will be
(size of original image) - (size of filter) + 1
Going back to the black and white edge example, the original image was `6xx8`. The filter was `3xx3`. So the result is `(6-3+1)xx(8-3+1)=4xx6`.
The examples so far have been simplified to use only one color channel. For color images there will be three channels, so the filter will also have three channels (each layer of the filter will be applied to each color layer). For example, a 6 x 6 color image will have dimensions `6xx6xx3`. A 3 x 3 filter applied to that image will have dimensions `3xx3xx3`. However, the result of applying the filter is 2D, not 3D. This can be confirmed with the math. The dimensions of the result will be `(6-3+1)xx(6-3+1)xx(3-3+1)=4xx4xx1=4xx4`.
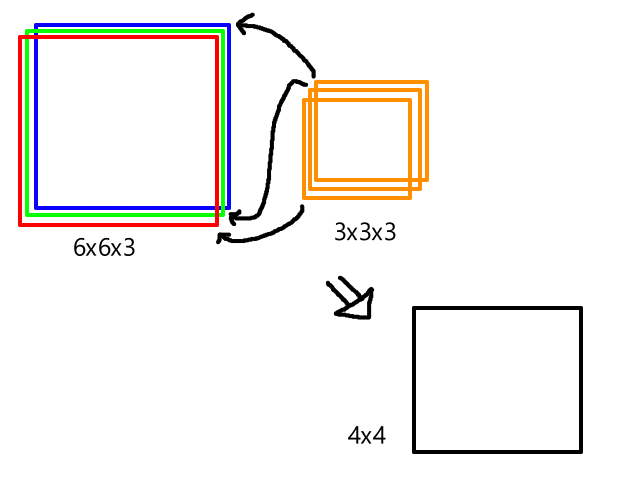
This size reduction presents several problems. Applying convolution too many times will shrink the image to the point where it is too small to work with. Also, there will naturally be more focus on the middle pixels and less focus on the edge pixels.
Back to the black and white edge example again, the top-left corner pixel is only used in one round of convolution:
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
But the pixel in red is used in four different rounds of convolution:
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
| 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 |
So the pixel in red has more influence than the edge pixel does.
To fix both these problems, the original image can be modified by zero padding, which is adding zeros (essentially white space) to the border of the image:
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | ||||||
| 0 | 0 | ||||||
| 0 | 0 | ||||||
| 0 | 0 | ||||||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
An image that was originally 4 x 6 is now 6 x 8. Applying a 3 x 3 filter to the zero-padded image will result in a 4 x 6 image, which is the same size as the original image. Also, the edge pixels move more toward the center, so they get used in more rounds of convolution.
If we want to preserve the original size of the image, the size of the padding to use is `(text(size of filter)-1)/2`. In the above example, the size of the filter was `3`. So `(3-1)/2=1` row of padding was needed.
Several filters are always used to detect different edges.
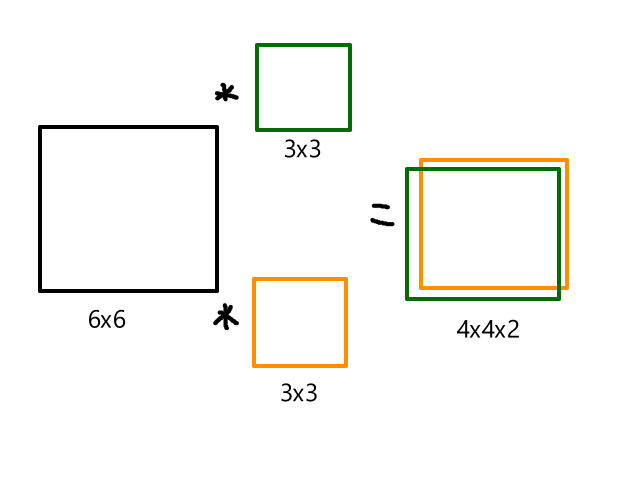
The `2` in the `4xx4xx2` comes from using 2 filters.
Pooling
#dimensionalityreduction
Pooling is used for dimensionality reduction. In the case of images, it compresses an image while keeping most of the important information. Pooling is also called subsampling. One type of pooling is 2 x 2 max pooling, which keeps the maximum pixel value in each 2 x 2 block of the image.
| 1 | 3 | 2 | 9 |
| 0 | 5 | 3 | 1 |
| 0 | 1 | 7 | 8 |
| 0 | 3 | 11 | 2 |
For the above, the result of max pooling is:
| 5 | 9 |
| 3 | 11 |
Pooling is applied to each channel individually. So if the input is 6 x 6 x 10 (10 filters were applied), then applying 3 x 3 pooling will produce an output of 2 x 2 x 10.
CNNs Are Like Onions
One layer of a CNN consists of 3 components: a convolutional layer, a nonlinear layer, and a pooling layer.
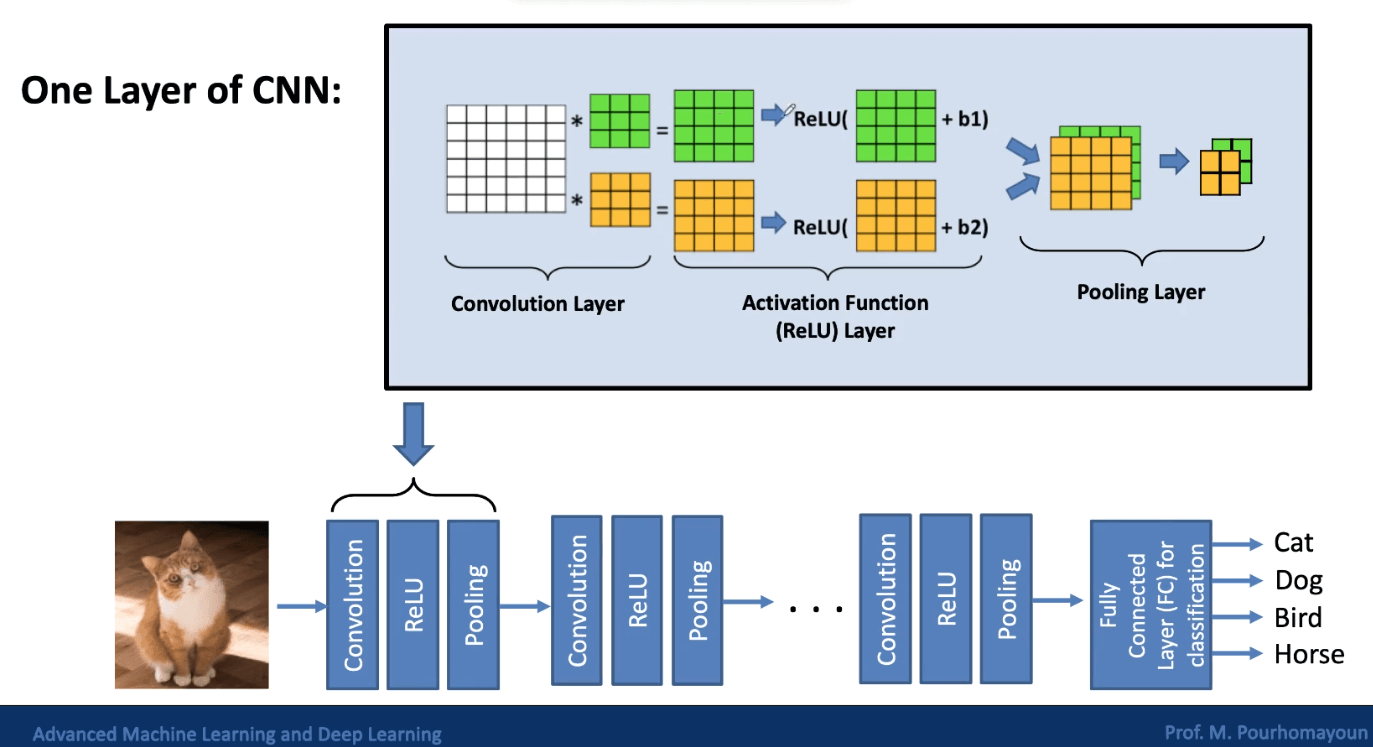
I'm going to borrow this picture from my professor since it is late and too complicated to draw on my own.
The ReLU layer is used for "nonlinearity". I'm not sure what that means exactly though.
Each layer gets increasingly complex in the patterns they detect. The first few layers look for very simple patterns, like edges. The middle layers combine those simple patterns to find more complex patterns, like eyes or noses. The last few layers combine the previous patterns to find high-level patterns, like a face. We don't tell the network what patterns to look for; it learns by itself what patterns to look for.
LeNet-5
LeNet-5 is a classic CNN first proposed by Yann LeCun.
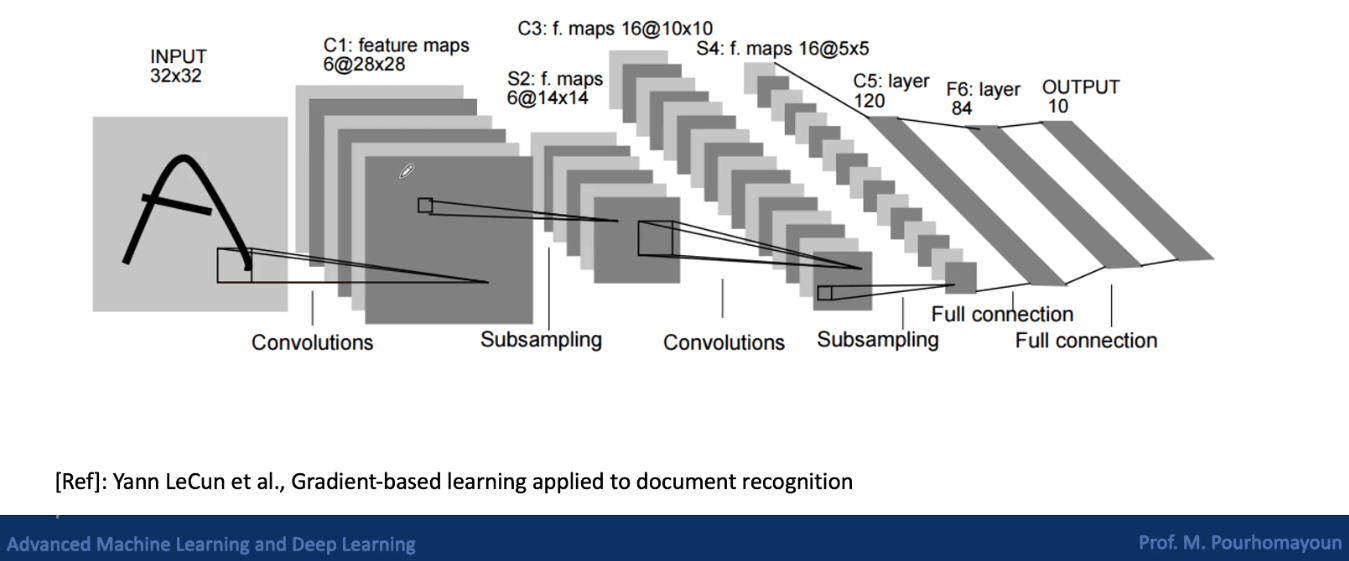
Again, borrowing another picture from my professor.
The first convolutional layer applies 6 filters that are each 5 x 5 (`32-5+1=28`). The first subsampling layer uses 2 x 2 max pooling (`28/2=14`).
The second convolutional layer applies 16 filters that are each 5 x 5 (`14-5+1=10`). The second subsampling layer uses 2 x 2 max pooling (`10/2=5`).
Support Vector Machine
Let's suppose we had some data like below and we wanted to build the best classifier. There are infinitely many classifiers that would work (some examples shown below). Which one would be the best?
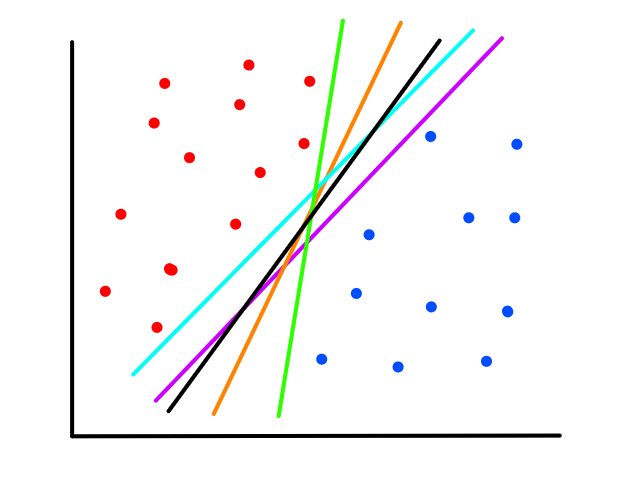
It may seem like the black line is the best classifier since it is in the middle. And in fact, it is, but to frame this a little more formally, let's take a look at the data point that is closest to the classifier and measure its distance to the classifier.
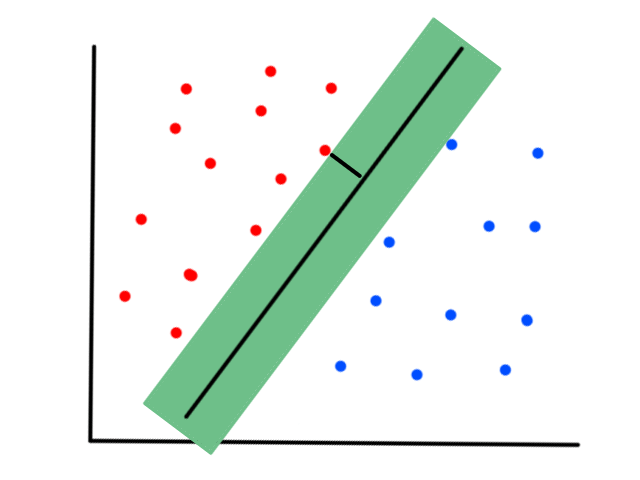
If we take that distance and double it on the other side, we create an area around the classifier where there are no data points inside. This "safe zone" is referred to as the margin. So we can say that the black line is the best classifier because it has the widest margin.
If we do this for the pink line, we see that the margin is very narrow:
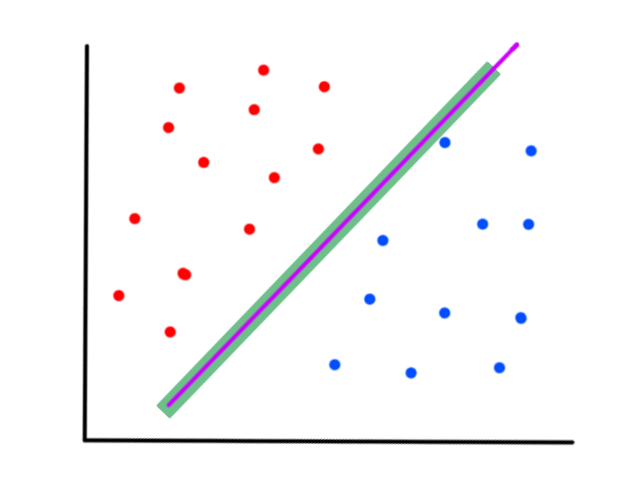
It is not good to have data points very close to the classifier because that means that there is some uncertainty about which class it belongs to.
Each data point can be represented as a vector. The vectors closest to the classifier determine how wide the margin will be. This is why it is called a "support vector" machine.
Since the dataset only has two features, the classifier is a line. With three features, the classifier would be a plane. With more features, the classifier would be a "hyperplane".
So the best classifier is the one that has the widest margin. How do we go about building it? (To keep things simple, we will just stay in the 2D world.)
Lining Them Up (Again)
We can represent a line using this equation:
`w_1x_1+w_2x_2+b=0`
where `x_1` and `x_2` represent the features
Storing the weights in a vector `bb w=[[w_1],[w_2]]` and the features in another vector `bb x=[[x_1],[x_2]]`, we get a vectorized representation of a line:
`bb w^T bb x+b=0`
Let's say we have some arbitrary line whose equation is `-3x_1+2x_2+4=0`.
Any points on the line when plugged into the equation will be equal to zero. Any points above the line will be positive and any points below the line will be negative.
`-3(4)+2(4)+4=-12+8+4=0`
`-3(6)+2(3)+4=-18+6+4=-8<0`
`-3(2)+2(5)+4=-6+10+4=8>0`
This is true for any line. So how can we use this fact to build a classifier?
Maximizing the Margin
We want to find a line such that all the samples that should be above the line are positive when plugged into the equation of the line. And all the samples that should be below the line are negative when plugged into the equation of the line.
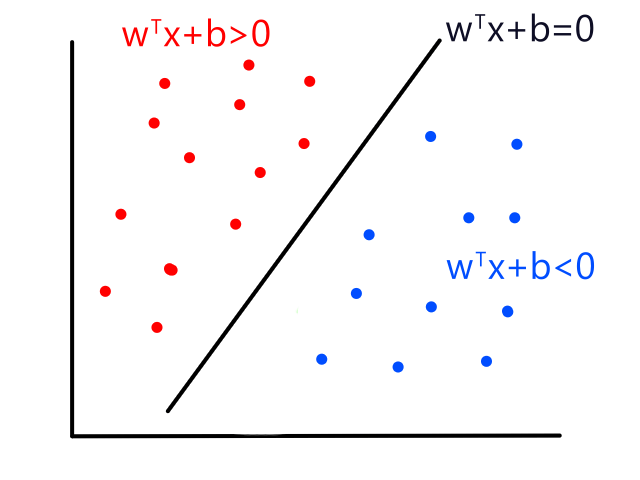
Let's say we draw some random line. If it satisifes the aforementioned requirements, then it is a working classifier. But we can do better.
Let's say we draw some random line that satisifes the requirements. In addition, let's draw two more lines — one on each side of the classifier — that are parallel and equidistant to the classifier.
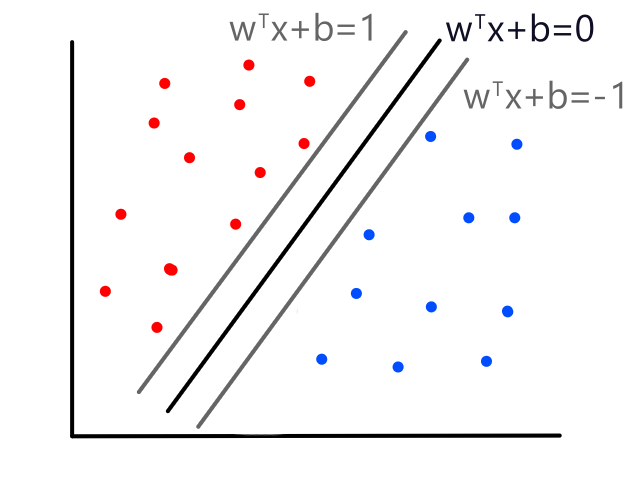
This forms the margin. So now we can be a little bit stricter and say that our classifier is working (and better) if all the data samples above the margin are positive and all the data samples below the margin are negative. Mathematically,
`bb w^T bb x+b>=1`
`bb w^T bb x+b<=-1`
But we can do better. Those two lines that we drew? What if we drew them such that the margin was as wide as possible?
The margin is the distance between the two lines `bb w^T bb x+b=1` and `bb w^T bb x+b=-1`. It is also equal to `2/(||bb w||)`, which will be proved here.
First, it is necessary to show that the vector `bb w` is normal to the hyperplane (in this case, the hyperplane is `bb w^T bb x+b=0`). In order for a vector to be normal to the hyperplane, the dot product of that vector with another vector on the hyperplane must be equal to zero. So let's get a vector on the hyperplane and take the dot product.
Let `bb x_1` and `bb x_2` be vectors pointing to points on the hyperplane. `bb x_1` and `bb x_2` are not necessarily on the hyperplane, but `bb x_1 - bb x_2` is on the hyperplane. I'm sure there's some mathematical proof for this, but here's some visual intuition instead.
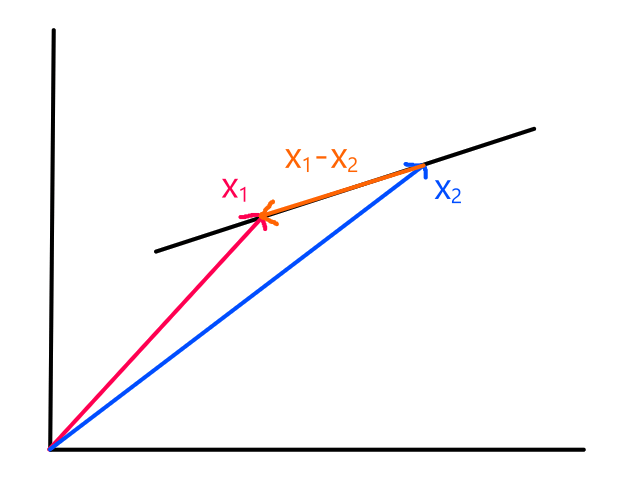
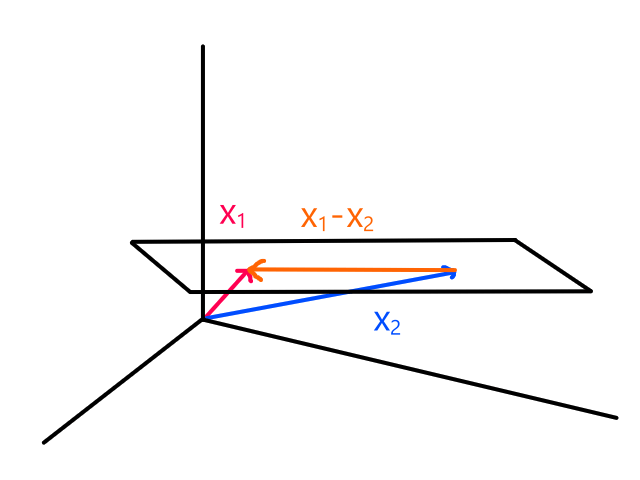
(this is what it would look like for the 3D case)
If we take the dot product of `bb w` and `bb x_1-bb x_2`, which is equivalent to `bb w^T (bb x_1-bb x_2)`, we get:
`bb w^T (bb x_1-bb x_2)=bb w^T bb x_1 - bb w^T bb x_2 = -b - (-b) = -b + b = 0`
(`bb w^T bb x_1=bb w^T bb x_2=-b` since `bb w^T bb x+b=0`)
So `bb w` is in fact normal to the hyperplane.
Now let's suppose we have the two lines `bb w^T bb x+b=1` and `bb w^T bb x+b=-1`. Let's pick two points, one on each line, and call them `x_+` and `x_-`. If we draw vectors to those points and subtract them, then we get the distance between `bb w^T bb x+b=1` and `bb w^T bb x+b=-1`. Well, almost.
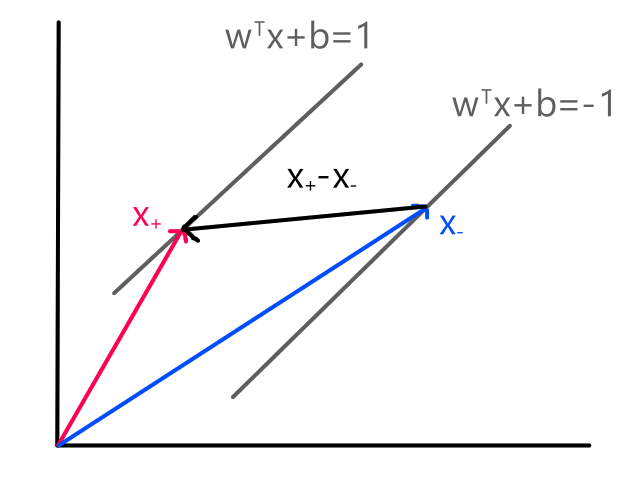
The actual distance between `bb w^T bb x+b=1` and `bb w^T bb x+b=-1` is `M` as shown below:
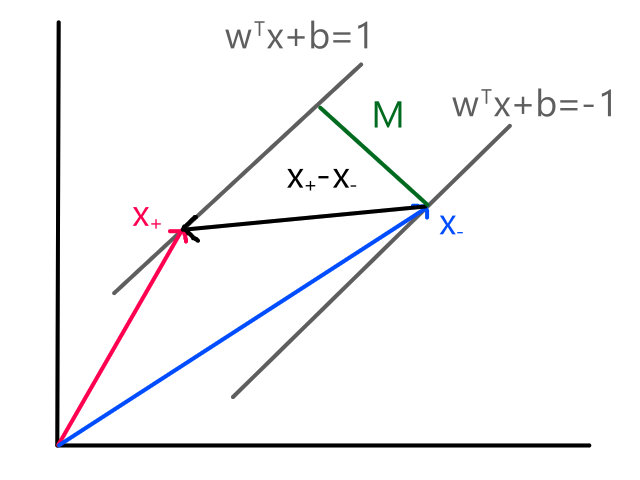
The vector `bb x_+ - bb x_-` is pointing in a different direction than the direction of the distance. If we could figure out how much to rotate `x_+ - x_-` by, then we could get them pointing in the same direction. Now we can use the fact that `bb w` is normal to the hyperplane. Since `bb w` is normal to the hyperplane, it is pointing in the same direction as the distance.

So if we rotate `bb x_+ - bb x_-` by some angle `theta`, then `bb x_+ - bb x_-` will be pointing in the same direction as `bb w`. However, if we simply rotate it, then the length of `bb x_+ - bb x_-` will remain larger than `M`. We have to scale down the length at the same time we are rotating it, and we do this by multiplying the length of `bb x_+ - bb x_-` by the amount we are rotating, which is `costheta` (good ol' SOHCAHTOA). So we have
`M=||bb x_+ - bb x_-||costheta`
It turns out that `costheta` is equal to the dot product of the two vectors divided by the product of their lengths. So:
`costheta=((bb x_+ - bb x_-).bb w)/(||bb w|| cdot ||bb x_+ - bb x_-||)`
Which allows us to simplify:
`M=||bb x_+ - bb x_-||costheta`
`=||bb x_+ - bb x_-||((bb x_+ - bb x_-).bb w)/(||bb w|| cdot ||bb x_+ - bb x_-||)`
`=((bb x_+ - bb x_-).bb w)/(||bb w||)`
`=(bb w^T bb x_+ - bb w^T bb x_-)/(||bb w||)`
`=((1-b)-(-1-b))/(||bb w||)`*
`=2/(||bb w||)`
*Since `x_+` was a point on the line `bb w^T bb x+b=1`, `bb w^T bb x_+ +b=1`. Similarly for `x_-`.
So now our goal is to correctly classify samples and maximize the margin. In other words, we want to satisfy three conditions:
maximize `2/||bb w||`
if the sample is positive (which we will denote as `y=+1`), then it will satisfy `bb w^T bb x + b >= 1`
if the sample is negative (which we will denote as `y=-1`), then it will satisfy `bb w^T bb x + b <= -1`
Maximizing `2/||bb w||` is the same as minimizing `||bb w||`. This is because maximizing `2/||bb w||` means making the denominator as small as possible. To make it a convex function, we can make it `||bb w||^2`. And let's throw a `1/2` in there to make derivatives simpler. So maximizing `2/||bb w||` is the same as minimizing `1/2||bb w||^2`.
We can also convert the two equations into one:
`y(bb w^T bb x + b) >= 1`
(notice that if `y=1` or `y=-1`, then both equations are achieved)
So finally, our goal is to satisify these two conditions:
minimize `1/2||bb w||^2`
`y_i(bb w^T bb x_i + b) >= 1`
for a dataset `{(bb x_1, y_1), (bb x_2, y_2), ..., (bb x_n, y_n)}`
Finding the best line that satisfies those two conditions involves Lagrange multipliers, which I won't talk about here (cuz I have no idea what they are), so the math torture can stop here.
The TLDR is
`bb w=sum_(i=1)^n alpha_iy_i bb x_i`
`b=y_k-bb w^T bb x_k` for any `bb x_k` such that `alpha_k ne 0`
and the classifier is the equation
`y=text(Sign)(bb w^T bb x + b)`
`Cut Me Some Slack!
So far we have been assuming that all the data points are nicely separable. (In fact, the situation with those two conditions for linearly separable data is referred to as "hard margin".) However, it is much more likely for our dataset to have some points mixed with each other.
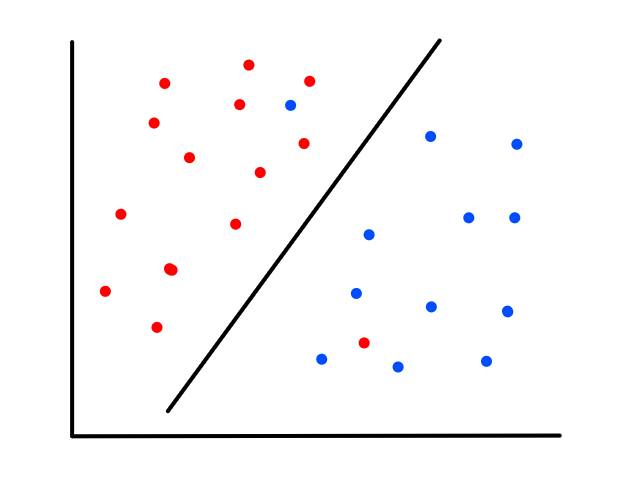
Finding a classifier that satisifies the condition `y_i(bb w^T bb x_i + b) >= 1` becomes impossible. Can you draw a straight line that puts all the red samples on one side and all the blue samples on the other side? We need a way to keep all our work from before, but also be able to handle non-separable samples. This is referred to as "soft margin".
We can allow those non-separable samples to be on the wrong side of the line, as long as they are not too far on the other side. This distance will be defined by slack variables (denoted by `xi_i`).

Of course, some samples will be misclassified, but now those samples will not prevent us from drawing a line that mostly works pretty well. We can't allow the slack variables to be too large though, otherwise everything could be misclassified. So the slack variables need to be minimized as well. The conditions for soft margin become:
minimize `1/2||bb w||^2+Csumxi_i`
`y_i(bb w^T bb x_i + b) >= 1-xi_i`
`C` is similar to the regularization parameter in gradient descent (See "A7.2) Regularization") and in neural networks. In a nutshell, having a large value for `C` forces the `xi_i`s to be really small, which means there is little tolerance for misclassification, which means the model will be prone to overfitting. Having a small value for `C` allows the `xi_i`s to be larger, which means there is some tolerance for misclassification, which means the model could be prone to underfitting.
Multi-class Classification
So far we have only been working with two classes (red/blue, positive/negative). It is possible to extend SVM (and other classifiers for that matter) to multi-class situations using a one-vs-all method. We pick one group and treat the other groups as one other group. Then we build a classifier:
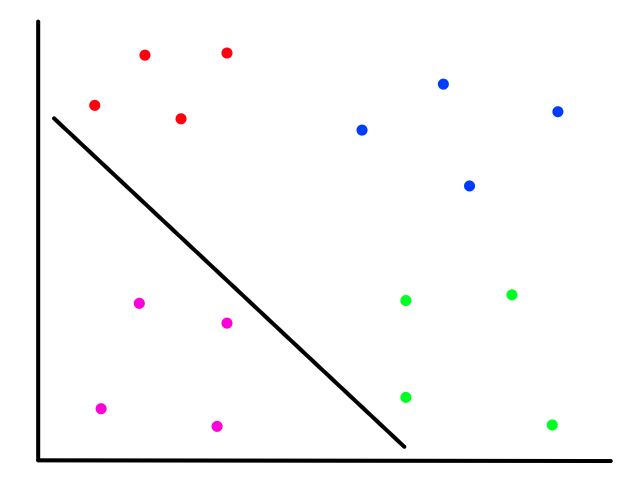
We repeat this for all of the classes:
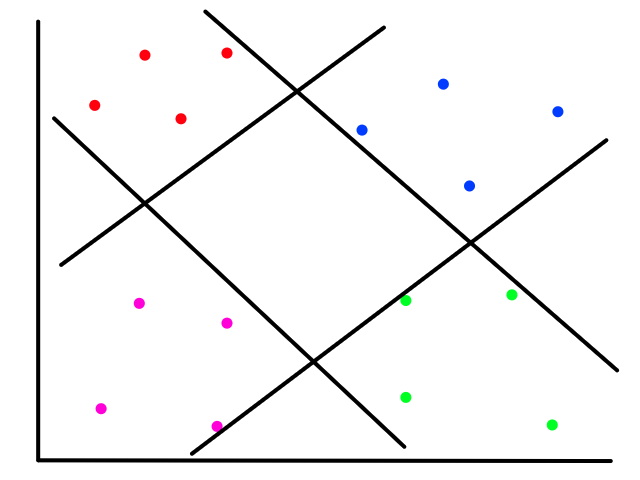
Nonlinear SVM
Like for polynomial regression, what if the data is not linearly separable? Let's take a step back and look at an example in 1D. Suppose we have linearly separable data:
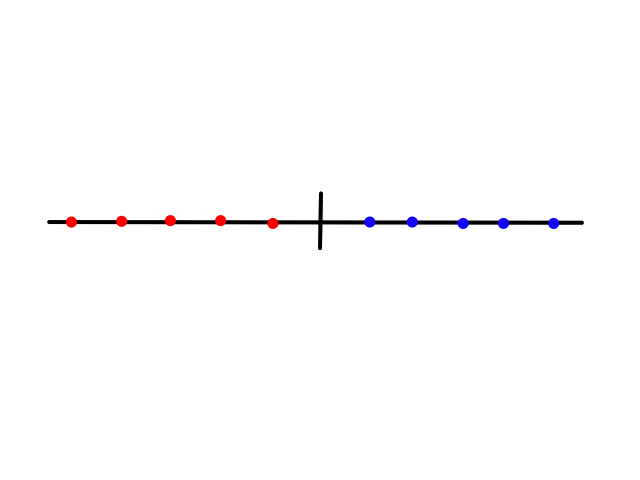
It's pretty easy to separate the data with a classifier right down the middle. Now let's suppose we have data that is not linearly separable.

It turns out we can still use a straight line to neatly separate the data 🤯. We just have to "bend the space".
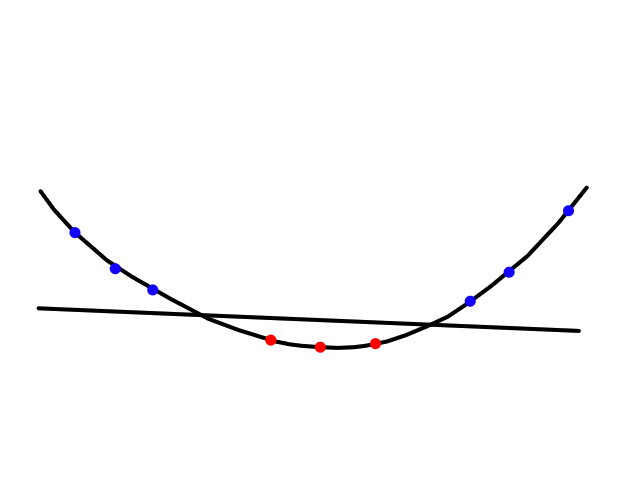
By bending the space, we are moving the data into a higher-dimensional space to make it linearly separable. In this example, we are moving the data from 1D to 2D.
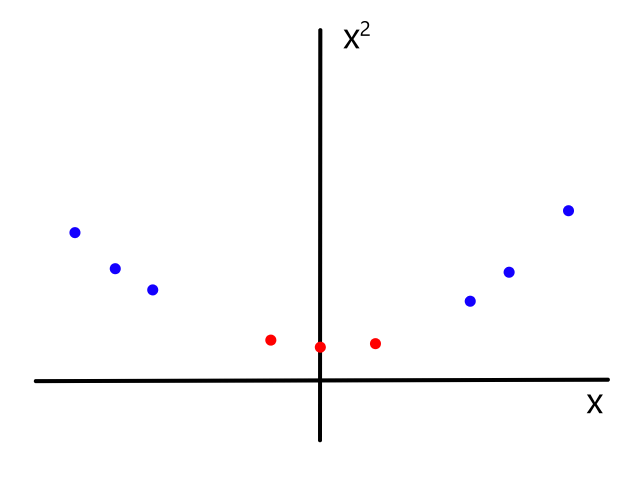
In 2D, the two features are `x` and `x^2`.
Let's see what bending 2D space looks like.
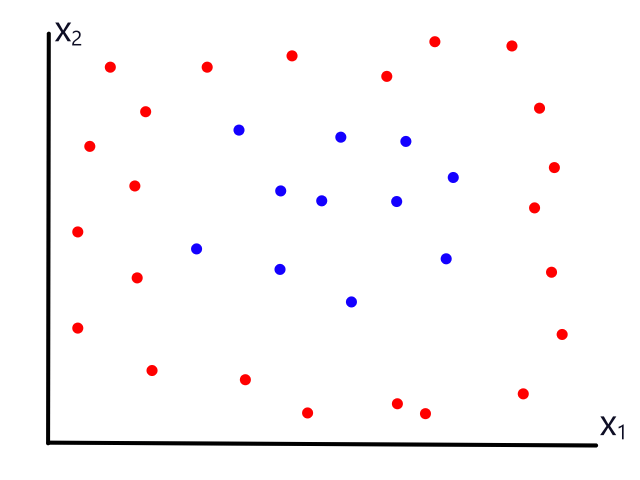
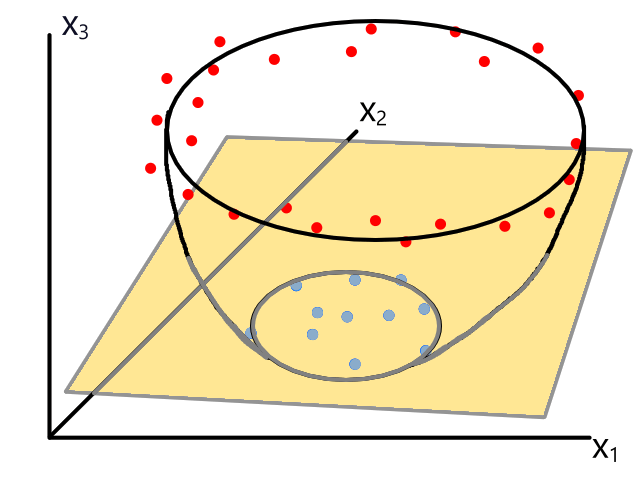
The function that transforms the data into a higher-dimensional space is denoted as `Phi:x rarr varphi(x)` where `varphi(x)` is the higher-dimensional space. In the 1D `rarr` 2D example, the function `Phi` is defined as `Phi:x rarr [[x],[x^2]]`. In the 2D `rarr` 3D example, the function is `Phi:[[x_1],[x_1]] rarr [[x_1],[x_2],[x_1^2+x_2^2]]`.
So the main idea for non-linear SVMs is to transform the data into a higher-dimensional feature space where the data is linearly separable. However, there are several problems we have to deal with.
- What is the best new space?
- What is the best function `Phi`?
- Working in higher dimensions results in higher computational complexity
The Kernel Trick
The original space is
`y=text(Sign)(sum_(i=1)^nalpha_iy_i bb x_i^T bb x+b)`
Using `Phi` to transform the data, the new space is
`y=text(Sign)(sum_(i=1)^nalpha_iy_ivarphi(bb x_i)^Tvarphi(bb x)+b)`
In transforming the data, we calculate the inner product `varphi(bb x_i)^Tvarphi(bb x)`. We don't actually need to know what `varphi(x)` is; we just need to know what `varphi(bb x_i)^Tvarphi(bb x)` is. What this means is that we don't actually need to know what the higher-dimensional space looks like.
We can define a kernel function `K` such that
`K(bb x_i, bb x_j)=varphi(bb x_i)^Tvarphi(bb x_j)`
The kernel function performs the inner product in the higher-dimensional space.
So now the classifier is the equation
`y=text(Sign)(sum_(i=1)^nalpha_iy_iK(bb x_i, bb x)+b)`
Some commonly-used kernel functions:
Polynomial kernel: `K(bb x_i, bb x_j)=(r+gammabb x_i^T bb x_j)^d`
Gaussian Radial-Basis Function (RBF): `K(bb x_i, bb x_j)=exp(-(||bb x_i-bb x_j||^2)/(2sigma^2))`
Hyperbolic Tangent: `K(bb x_i, bb x_j)=tanh(r+gammabb x_i^T bb x_j)`
Appendix
A1) Accuracy: Is It Accurate?
When the data is unbalanced, then no.
Suppose we had data where 99% of it had a "no" label. Let's say we built a classifier that always labels every input as "no". Technically, that classifier would have an accuracy of 99%.
One solution to this is to balance the data first. If there are a good amount of "yes" data, then some of the "no" data can be removed until the amount of each are roughly equal. If there are very few "yes" data, then the "yes" data can be duplicated.
A2) Model Evaluation
Generally, accuracy should be used to evaluate the correctness of a classification model (the higher the better) and error should be used to evaluate the correctness of a regression model (the lower the better).
A2.1) Binary Classification
However, as shown in the section above, accuracy is not always the best metric to use.
In binary classification, the data has two labels (1/0, true/false, etc.). One of the labels represents an event that is happening (e.g., an email is spam, a patient has cancer, it is raining). This is a positive label. The other label represents an event not happening (e.g., an email is not spam, a patient doesn't have cancer, it is not raining). This is a negative label.
Suppose we had some positive data (red) and negative data (blue) and a classifier that predicts everything on the left to be positive and everything on the right to be negative.
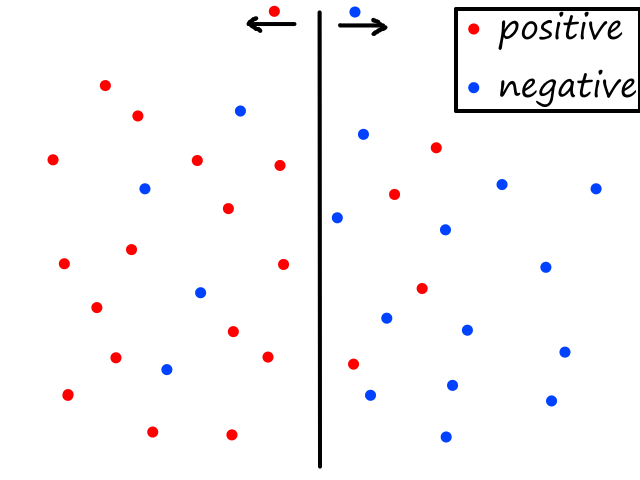
On both sides, there are some data that are misclassified. The misclassified ones on the left are negative samples that were predicted to be positive. These are called false positives (false alarms).
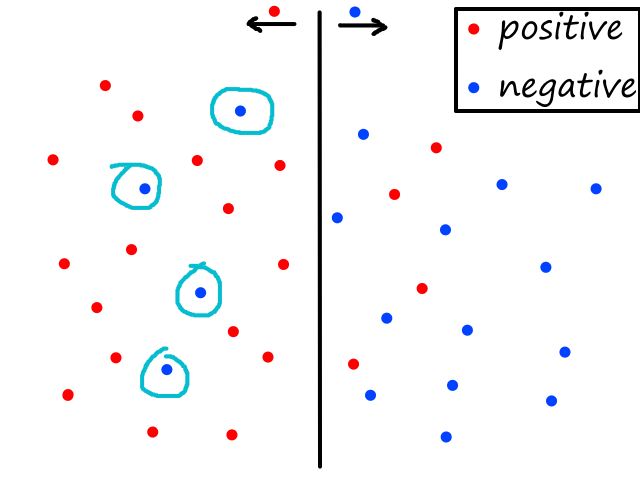
false positives
The misclassified ones on the right are positive samples that were predicted to be negative. These are called false negatives.
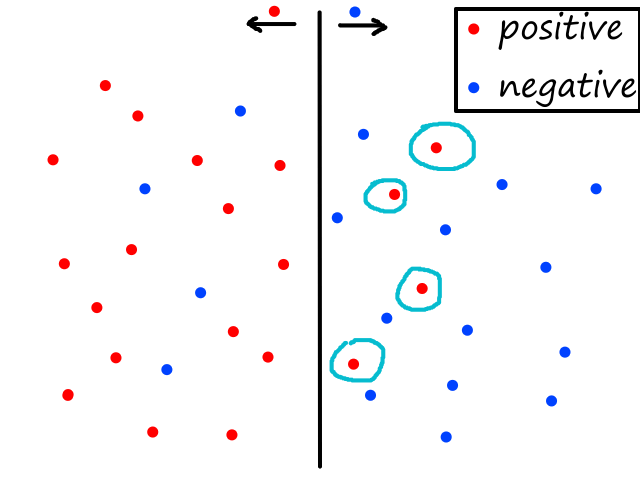
false negatives
And of course, the ones that are correctly classified are called true positives and true negatives.
This can be succinctly represented in a confusion matrix:
| Predicted Label | |||
| Positive | Negative | ||
| Actual Label | Positive | TP | FN |
| Negative | FP | TN | |
With these new terms, we can define accuracy as:
`text(accuracy)=(TP+TN)/(TP+TN+FP+FN)`
(number of correct)/(total number of samples)
But as mentioned earlier, we are interested in other metrics besides accuracy.
A2.1.1) Sensitivity
True positive rate (TPR), aka sensitivity, is the percent of correct predictions for positive samples:
`TPR=(TP)/(TP+FN)`
(number of correct positives)/(total number of positives)
Sensitivity is a measure of how well a model can detect something is happening.
A2.1.2) Specificity
True negative rate (TNR), aka specificity, is the percent of correct predictions for negative samples:
`TNR=(TN)/(TN+FP)`
(number of correct negatives)/(total number of negatives)
Specificity is a measure of how well a model can rule out an event happening.
A2.1.3) False Alarm Rate
False positive rate (FPR), aka false alarm rate, is the percent of wrong predictions for negative samples:
`FPR=(FP)/(TN+FP)`
(number of wrong negatives)/(total number of negatives)
It is also defined as:
`FPR=1-text(specificity)`
A2.1.4) Evaluation
Let's go back to our classifier
and move it to the right a bit.
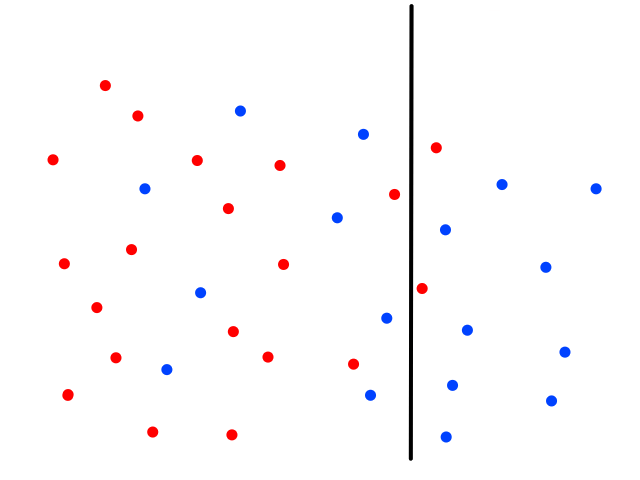
Now, more positive samples will be correctly classified, so sensitivity will increase (the model will be more sensitive). But at the same time, more negative samples will be incorrectly classified, so specificity will decrease. As a result, there will also be more false alarms.
`uarr text(sensitivity)=(TP)/text(all positives)`
`darr text(specificity)=(TN)/text(all negatives)`
`uarr text(false alarm rate)=(FP)/text(all negatives)`
In medical applications, it is usually preferred to have more sensitive models. If our model was predicting whether or not a patient cancer, it is important that the model is good at detecting positive samples. It is also very dangerous to have false negatives (i.e., the patient has cancer, but our model predicted no), so having a more sensitive model reduces the number of false negatives. While there will be more false alarms, more tests can be done to see if the patient actually has cancer.
Now let's move the classifier to the left a bit.
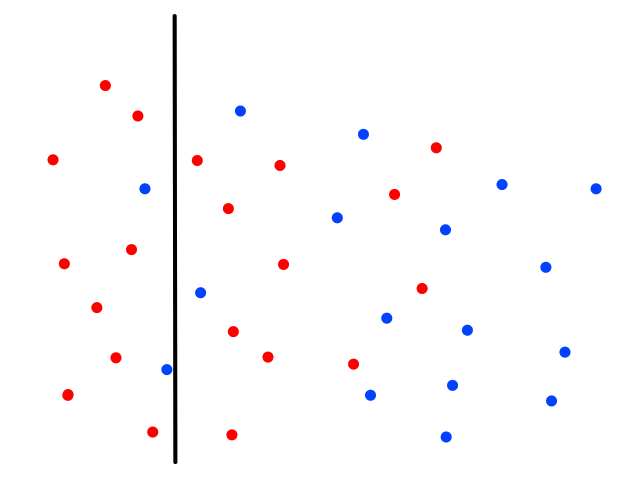
This time, fewer positive samples will be correctly classified, so it will be less sensitive. And more negative samples will be correctly classified, so specificity will be higher.
`darr text(sensitivity)=(TP)/text(all positives)`
`uarr text(specificity)=(TN)/text(all negatives)`
`darr text(false alarm rate)=(FP)/text(all negatives)`
A less sensitive model is useful in situations where false alarms are very costly, like predicting natural disasters (we don't want to evacuate people when there's no need to).
A2.1.5) ROC Curves
ROC stands for "receiver operating characteristic". A ROC curve is basically a visual representation of a model's TPR and FPR.
This is an example of a model's ROC curve. As the model's TPR increases, so does the model's FPR.
With ROC curves, we can compare different models. Let's say each line represented the ROC curves of three classifiers (e.g., KNN, decision tree, and random forest).
The model with the blue ROC curve is better because for a fixed FPR, it has the highest TPR.
Generally, the closer to the top-left corner, the better. In fact, a perfect model (100% accuracy) would have a ROC curve like this:
When the model has a 100% TPR, it has a 0% FPR.
The worst case would be like this:
In this case, the model's TPR is equal to its FPR, which means it is just like random guessing.
It is possible for a model to perform worse than random guessing (if this happens, you know you done messed up). The ROC curve would look something like this:

It is also possible for two models to have ROC curves like this:

Which model would be considered better in this case?
Another metric that is used to evaluate models (in the context of ROC curves) is Area Under Curve (AUC). It measures how much space is under the curve (the more the better). The AUC of a perfect model would be 1 (100%) and the AUC of the worst case would be 0.5 (50%).
A2.2) Regression
For regression, root-mean-square error (RMSE) is usually used as the metric for error.
`text(RMSE)=sqrt(1/nsum_(i=1)^n(y_i-hat y_i)^2`
where `y_i` is the actual value and `hat y_i` is the predicted value
(the errors are squared so the square root returns it to the original unit)
RMSE is the average error in prediction. So if a predicted value was 100,000 and we got an RMSE of 2300, then the actual value could be somewhere between 97,700 and 102,300.
A3) Cross Validation
When training/testing machine learning models, we split the data randomly into training and testing sets. The problem with this is that the results may be influenced by the split. For example, a model could have achieved high accuracy because the testing set happened to have a lot of easily predictable data.
To make sure this doesn't happen, we should split the data several times in different ways each time. Cross validation repeats the splitting procedure `k` times such that every data sample will be in the testing set at least one time (which means every data sample will be in the training set `k-1` times).
The steps are:
- Split the dataset randomly into `k` same-sized, non-overlapping sections, called "folds".
- using `k=10` is a common value
- Use one of the folds as a testing set (the other `k-1` folds will be used for training).
- Repeat step 2 until all `k` folds have been used for testing.
- Calculate the average of all the accuracies/errors.
- `text(accuracy)=(text(accuracy)_1 + ... + text(accuracy)_k)/k`
- `text(RMSE)=(text(RMSE)_1 + ... + text(RMSE)_k)/k`
A4) Normalization
One type of normalization is to divide by the max for the feature (we did this in the KNN section). The result is that all the values get put in the range of 0 to 1. This type of normalization essentially makes one unit of distance in one feature equal to one unit of distance in the other feature.
Another type of normalization is to make the dataset have zero mean and unit standard deviation (z-score normalization). We can do this by subtracting each data point by the mean and dividing the difference by the standard deviation. (Disclaimer: the rest of this paragraph consists of claims based on my intuition, so I may be wrong.) This means that each data point now represents the number of standard deviations it is from the mean. While each feature can range from different values, all the data points essentially have the same units: distance from the mean. It's like having two sets of measurements, one in inches and one in centimeters, and converting both of them into "number of thumbs".
No matter which type of normalization is used, normalization should be done only on the training data. This is because testing data is considered "future data", so we theoretically don't have the data yet. The effects of normalizing the whole dataset can be seen below.
For z-score normalization, we would perform the following on each training data point `x`:
`z=(x-m)/s`
where `m` and `s` are the mean and standard deviation of the training data
to obtain the normalized value `z`. Then for each testing data point `x'`, we use the same mean and standard deviation obtained from the training data to do the same thing
`z'=(x'-m)/s`
to obtain the normalized value `z'`.
If we normalize the whole dataset before splitting, then information from the testing data will leak to the training data. Including the testing data will influence the mean and standard deviation, which will influence the training, i.e., the model will learn from both the training and testing data.
A5) Feature Selection
When training our models, we sometimes want to use only the important/relevant features to reduce training time and/or increase correctness.
One way is to find the features manually. We choose one feature and calculate accuracy using only that feature. Repeat for every feature until all features have been used. The features with the highest accuracies are the important features.
Another way is to use a decision tree. When building the decision tree, information gain is used to decide which features go on which levels of the tree. The features at the top of the tree are the important features.
Another way is to use linear/polynomial regression. Reminder: `h_theta(bb x)=theta_0+theta_1x_1+...+theta_nx_n`. The values for `theta_i` are the weights for each feature, i.e., they represent how much impact a feature has on the outcome. The features with the highest weights (with respect to absolute value) are the important features.
A6) Feature Extraction
Feature extraction transforms the data from a high-dimensional space to a lower-dimensional space by compressing the features. For example, if a dataset has five features, feature extraction will create — let's say — three new uncorrelated features that contain all the information from the original five features.
Let's look at the 2D `rarr` 1D case. We have two features `x_1` and `x_2`.
We can compress the two features into one new feature, which we can call `z`, by projecting the data points onto a diagonal line:
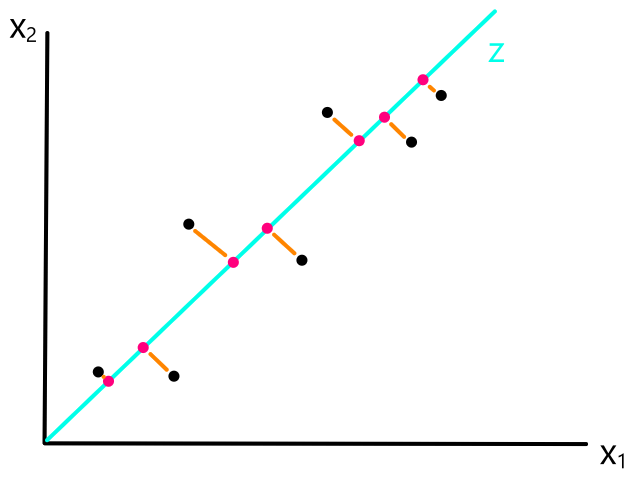
There is some error between the projection and the original data, but notice how the relative positions of the original data points can be represented by the new projection onto `z`, i.e., by looking at only the points on `z`, we can get a general idea of where the original points were. This means we've compressed the information from two features into just one feature. In this case, this is possible because there is some redundancy/correlation between the two features. As `x_1` increases, so does `x_2`, so there is a linear relationship between the two features.
This is what it looks like for the 3D `rarr` 2D case:
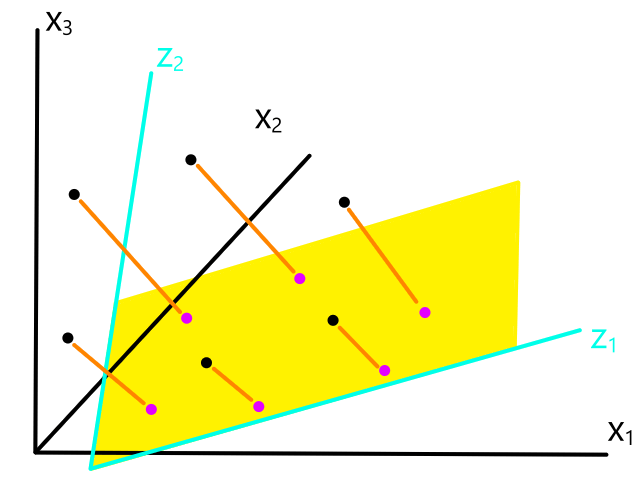
A6.1) Principal Component Analysis
#dimensionalityreduction
Of course, there are infinitely many projections that can be used, so which one is the best? When we project the data points onto a new line, there is some projection error (indicated in orange):
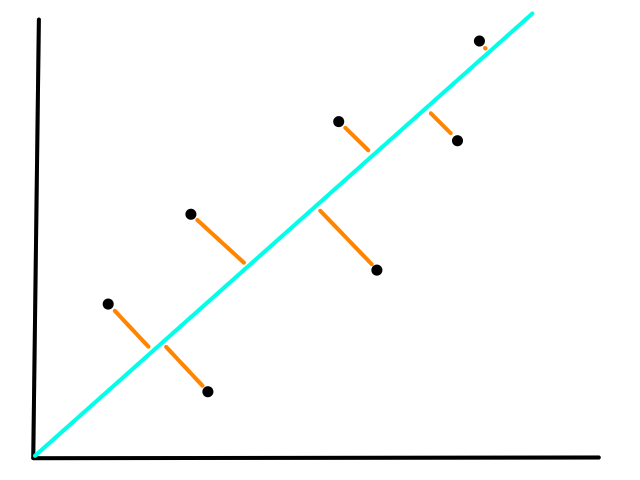
The best projection is the one that minimizes this error.
This is very similar to linear regression, where we draw a line that best fits the data points. The difference between linear regression and PCA is the type of error we want to minimize.
The above is linear regression and the error that is being minimized is the error between the predicted value and the output.
The above is PCA and the error that is being minimized is the projection error.
To minimize projection error, we fit an n-dimensional ellipsoid to the data. The axes of the ellipsoid are the new features that contain the information from the original features. These new features are called "principal components".
If an axis is very small, then it can be omitted since there won't be too much variance in that direction, which means there won't be too much information loss if we omit that axis.
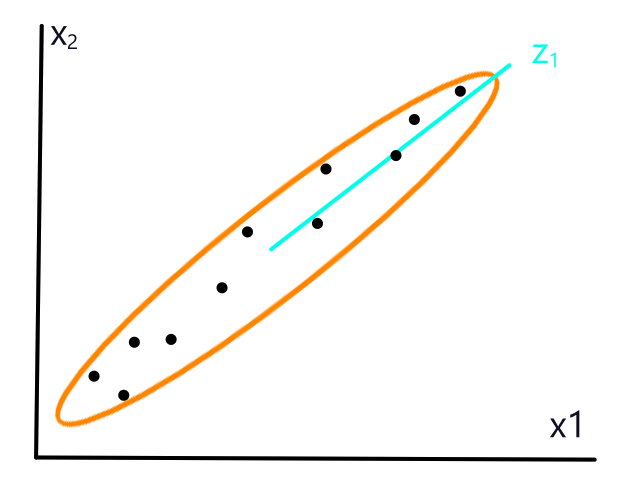
This means that PCA works better when the data is more "compressible". Being more compressible means that there is an obvious pattern/trend/redundancy in the data. In the narrower ellipsoid, as `x_1` increases, `x_2` generally increases too. But in the wider ellipsoid, `x_1` increasing doesn't always result in `x_2` increasing.
Finding the axes of the ellipsoid involves linear algebra.
Matrix multiplication is an operation that transforms the dimensionality of a vector. For example, if we multiply a `3xx1` vector `x` by a `2xx3` matrix `A`, we end up with a `2xx1` vector `y`. We've essentially turned a 3D vector into a 2D vector.
`Ax=y`
`[[1,2,-1],[3,-2,4]][[1],[3],[9]]=[[-2],[33]]`
Sometimes multiplying a vector by a matrix only changes the vector's length and/or makes it point in the opposite direction. What this means is that multiplying the vector by a matrix is exactly the same as multiplying the vector by a scalar number.
`Av=lambdav`
All vectors `v` that satisify the equation are called "eigenvectors". All the `lambda`s for each `v` are called "eigenvalues".
Covariance is a measure of how similarly two things change together. Let's say we have two variables `a=1` and `b=100`. If we add 15 to `a` and `b` also increases by 15, then `a` and `b` have high covariance. However, if we add 15 to `a` and `b` increases by 100, then `a` and `b` have low covariance.
A covariance matrix contains the covariance values between all the data points. So it contains the variance of each feature.
It turns out that the best axes for the ellipsoid are the eigenvectors of the covariance matrix of the dataset. So we have to find the covariance matrix and then the eigenvectors of that matrix to get the axes.
Since a covariance matrix is symmetric, the eigenvectors of a covariance matrix are orthonormal. They point in the direction of max variance and the eigenvalues are the measure of variance in that direction.
To find the eigenvectors of the covariance matrix, decompose (using eigendecomposition) the covariance matrix into the form `C=ULambdaU^T` where `U` is a matrix with `C`'s eigenvectors as columns and `Lambda` is a diagonal matrix with eigenvalues on the main diagonal and `0`s everywhere else.
Once we have the eigenvectors, we can put them in a matrix and multiply it with the original dataset to get the new features.
Suppose we have a dataset with `n` samples and `d` features. Let `X` be an `nxxd` matrix that represents the original data. Let `P` be a `d xx k` matrix where `k lt d` that contains the eigenvectors of the covariance matrix. Then the matrix multiplication of `X` and `P` will result in an `nxxk` matrix `Z` that represents the new features after extraction.
`Z=XP`
[new features] = [original data][principal components]
We have a choice in deciding how many new features we want to generate, the number of which is denoted as `k`. The new features should include most (95%-99%) of the variance in the original data. Since the eigenvalues represent the variance in the direction of their corresponding eigenvectors, we can choose a `k` such that
`(sum_(i=1)^klambda_i)/(sum_(i=1)^dlambda_i)>95%`
A7) Overfitting
Overfitting happens when the model learns too much. For example, it can learn from bad data (noise/randomness/outliers) that aren't representative of the data and become overly complex. This happens when
- there are too many features
- the model is too complex (e.g., very high order polynomial or high `k` for KNN)
These are some examples of overfitting:
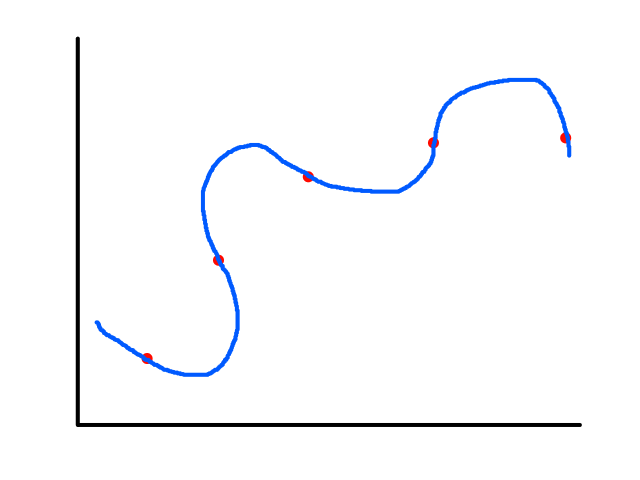
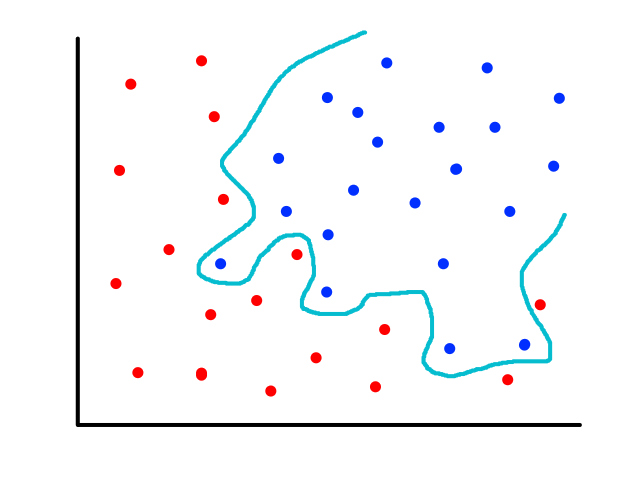
When overfitting happens, the model will have a really high accuracy on the training data, but have a low accuracy on the testing data. This is because it is very unlikely that the (testing) data will be distributed in such weird shapes.
A7.1) Dimensionality Reduction
If there are too many features, then we can reduce the number of features by keeping only the important features (see "A5) Feature Selection"). For example, if there are 20 features, we can keep 3 of them.
`theta_0+theta_1x_1+...+theta_20x_20 rarr theta_0+theta_1x_1+theta_2x_2+theta_3x_3`
Some features may be redundant (e.g., size of house and number of bedrooms) or irrelevant (e.g., number of tiles), so including them increases the complexity of the model for no real benefit.
A7.2) Regularization
If we want to keep all the features, we can instead simplify the model by reducing the magnitude/values of `theta_i`. For example:
`theta_0+theta_1x_1+theta_2x_2+theta_3x_3+theta_4x_1^2+theta_5x_2^2+theta_6x_2x_3+theta_7x_2x_3^2`
`rarr`
`theta_0+theta_1x_1+theta_2x_2+theta_3x_3+theta_4x_1^2+theta_6x_2x_3`
In the first overfitting example, we could set the `theta`s to zero for any terms of order 3 and order 4 so that it is a quadratic equation, which would fit the data and be a good model. Suppose the equation of the overfitting squiggle was:
`h_theta(x)=theta_0+theta_1x+theta_2x^2+theta_3x^3+theta_4x^4`
We want to set `theta_3` and `theta_4` to zero (or as close to zero as possible). Since we want to minimize these values, we could include them in the cost function so that they are minimized as well.
`J(theta)=1/(2m)sum_(i=1)^m (ubrace(h_theta(x^((i)))-y^((i)))_("error"))^2+ubrace(theta_3^2+theta_4^2)_("regularization")`
By minimizing the cost function, we are minimizing the error while also simultaneously minimizing the values of `theta_3` and `theta_4`.
More generally, we want to minimize all the `theta`s. The important ones will remain while the unimportant ones will be minimized.
`J(theta)=1/(2m)sum_(i=1)^m (h_theta(x^((i)))-y^((i)))^2+lambdasum_(j=1)^ntheta_j^2`
`lambda` is the regularization parameter that controls the tradeoff between accuracy and simplicity. A higher `lambda` makes the model simpler by adding more penalty for bad values of `theta` (similar to the way squaring the errors adds more penalty). Larger values of `lambda` force the `theta`s to be really really small in order to keep the cost at a minimum. But if `lambda` is too large, then all of the `theta`s will be close to zero, which means the equation will become a straight line (`h_theta=theta_0`) and have low accuracy (underfitting). Lower values of `lambda` make the model more complex, but increases accuracy (if `lambda rarr 0`, then the only thing we're minimizing is error).
Gradient descent:
`theta_0=theta_0-alpha1/msum_(i=1)^m(h_theta(x^((i)))-y^((i)))x_0^((i))`
`theta_j=theta_j(1-alphalambda/m)-alpha1/msum_(i=1)^m(h_theta(x^((i)))-y^((i)))x_j^((i))`
for `j=1,2,...,n`
For linear regression, `h_theta(bb x)=theta^T bb x`.
For logistic regression, `h_theta(bb x)=1/(1+e^(-theta^T bb x))`.
A8) Bias and Variance
A model can be characterized by its bias and its variance. Bias is the error due to an inaccurate model that misses the relationship between the features and the outputs. A model with high bias is highly inaccurate (underfit). Variance is the error due to the sensitivity of the model to the training dataset. (Note: "Sensitivity" here is not referring to true positive rate. It is referring to the fact that the model is so specifically trained that slightly changing the training dataset will drastically change the model.) A model with high variance is really accurate with the training dataset, but really inaccurate with the testing dataset (overfit).
A9) Ensemble Learning
In ensemble learning, a group of models (base learners) are used to make predictions, then the results from all of them are combined together to get the final result. Each base learner may have poor performance on their own, but when combined together, they could be very strong. #StrengthInNumbers.
It is very important that each learner is different from each other, i.e., they produce different results. If they were all the same, then it would be equivalent to just using one model and there would be no point in using a group of models. But more importantly, they can cover each other's mistakes by being different. For example, if one learner misclassified something but another learner correctly classified it, then the second learner would have the first learner's back.
There are several ways to ensure that each base learner is different from each other. Each one could use a different algorithm. Or they could all use the same algorithm but with different parameters (e.g. different values of `k` for KNN) and/or different features and/or different subsets of the dataset (e.g. random forest).
A9.1) Bootstrapping
Bootstrapping (or bootstrap sampling) generates training subsets by randomly sampling from the training dataset with replacement. For example, from a dataset `S`, three subsets of size 8 can be created like below:
| Dataset `S` | `S_1` | `S_2` | `S_3` |
| 1 | 7 | 9 | 4 |
| 2 | 4 | 3 | 1 |
| 3 | 5 | 9 | 1 |
| 4 | 5 | 9 | 10 |
| 5 | 8 | 10 | 8 |
| 6 | 9 | 7 | 3 |
| 7 | 2 | 4 | 7 |
| 8 | 8 | 6 | 6 |
| 9 | |||
| 10 |
Each of the training subsets may overlap with each other (because of randomness) and may have duplicates (because of replacement). Having duplicates can be a good thing though because one learner will be very good at predicting the duplicates while another learner will be very good at predicting different duplicates. For example, a learner trained on `S_1` will be good at predicting 5s, `S_2` will be good at predicting 9s, and `S_3` will be good at predicting 1s. A learner trained on `S_2` might misclassify a 1 because it never learned it, but `S_3` will cover it.
A9.2) Combining the Results
So after each base learner makes a prediction, how do we make a final decision based on each learner's prediction?
A9.2.1) Voting
Majority wins.
A9.2.1.1) What About Regression?
There won't really be a concept of a "majority" for regression, so the average of the predictions can be used. In some cases, a bad prediction (bad classifier! bad!) can ruin the average, so the median can be used instead.
A9.2.2) Bagging
Bagging is an amalgamation of "bootstrap" and "aggregating". Each base learner trains on a different subset of the dataset, where each subset is generated by bootstrapping. After they make their predictions, the final prediction is made based on voting. Basically, bagging = bootstrapping + voting.
Since many learners are used, bagging is used to reduce variance and deal with overfitting. Typically, bagging is used with high variance algorithms like decision trees and neural networks.
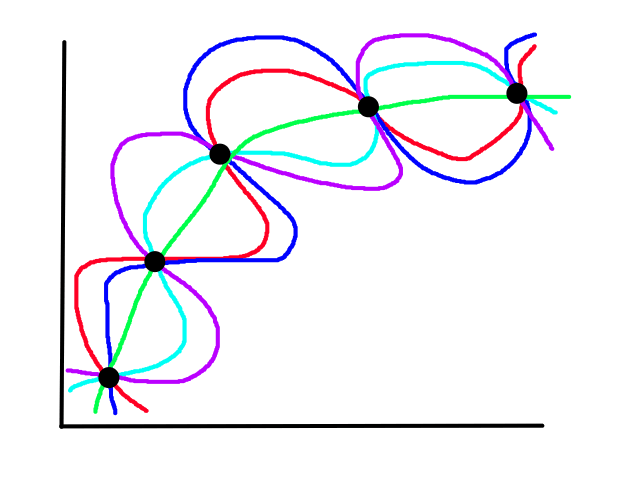
If we have four overfit base learners (red, blue, cyan, purple), "taking the average" of each base learner produces an ideal fit model (green).
A9.2.3) Stacking
In this scenario, there are base learners and a separate upper-level model. The base learners make their predictions and send them to the upper-level model, which makes a final prediction based on the base learners' predictions. A new dataset is created where the base learners' predictions are treated as features and the target is the target from the base learners' dataset. The upper-level model is trained on this new dataset, so over time it will know which base learner is better and give that learner's prediction more weight.
A9.2.4) Cascading
In this scenario, the base learners are combined iteratively. On each iteration, the training dataset is modified based on the results of previous iterations and used to train the next base learner.
A9.2.4.1) Boosting
Boosting also uses several base learners that each train on a different dataset, but the dataset is built iteratively based on the performance of each learner. The process starts with training one learner on the dataset and seeing which samples were misclassified. Those misclassified samples are duplicated so that more of them appear in the dataset. Also, some of the correctly classified samples are taken out so the training dataset can include more of the problematic samples. So the distribution of the dataset is changed to include more of the misclassified samples and less of the correctly classified samples.
After the new training dataset is built, the next learner is trained on this new dataset, which should theoretically be able to correctly classify the misclassified samples from the first learner. However, it is not necessarily better than the previous learner because it can still misclassify other samples (the proportion of correctly classified samples was reduced so this learner may not learn them as well as the previous learner).
When all the learners are finished training and making their predictions, weighted voting is used to make the final decision, where more weight is given to the better performing learners.
Boosting is the opposite of bagging in the sense that boosting is used to increase variance.
Suppose we have a training dataset with positive (blue) and negative (red) samples. In the first round of training, all samples have equal weights (indicated in these examples by their sizes).
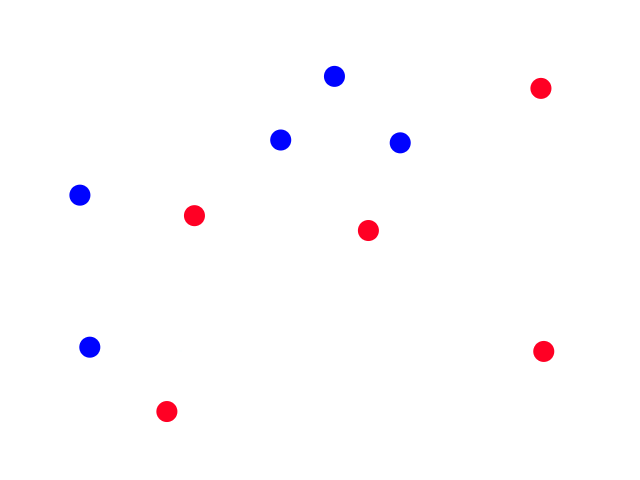
Let's say the classifier is a simple line that predicts everything left to be positive and everything right to be negative.

Some of the positive samples were misclassified, so for the next iteration, the weights of those will be increased. And the weights of the correctly classified samples will be decreased.

Let's say the second classifier predicts like this:

Now the previously misclassified positive samples are now correctly classified, but some of the negative samples are incorrect. So we readjust the weights for the third classifier:

And suppose it predicts like this:

So after three iterations, we have three classifiers that roughly look like this:
With the combinination of them achieving perfect accuracy:
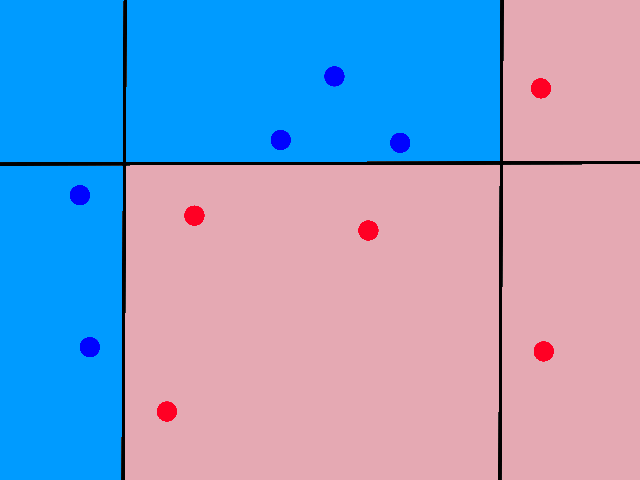
If we have three underfit base learners (red, blue, purple), "combining" all the base learners produces an ideal fit model (green).
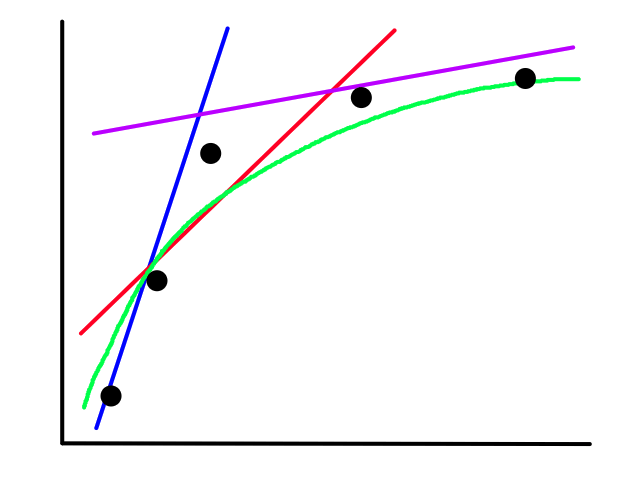
A9.3) Why does Ensemble Learning Work?
Let's say we have 3 independent classifiers each with an accuracy of 70%. Let's also decide that the final prediction will be based on voting. If we give them a positive sample to predict, then the final prediction will be correct if at least 2 of the classifiers predict positive. What are the chances of this happening?
Having at least 2 classifiers predict positive means that either 1) exactly 2 of the classifers predict positive or 2) all 3 of the classifiers predict positive. The possibility of all 3 classifiers predicting positive is `0.7\cdot0.7\cdot0.7=0.7^3=0.343`. The possibility of exactly 2 of the classifiers predicting positive is `(0.7\cdot0.7\cdot0.3+0.7\cdot0.3\cdot0.7+0.3\cdot0.7\cdot0.7)=0.441` (binomial theorem anyone?). So the possibility of both events happening, i.e., making a correct prediction, is `0.343+0.441=0.784`.
Each classifier alone has a 70% chance of getting it right, but when we combine them, they now have a 78% chance of getting it right.
Theoretically, using 101 indpendent classifiers achieves a final voting accuracy of 99.9%. So if combining classifiers and using voting increases accuracy, why don't we always use more (and more!) classifiers? Because in reality, the classifiers will never be independent (we assumed the classifiers were independent).
A9.4) Advantages and Disadvantages of Ensemble Learning
Advantages:
- improves prediction performance and accuracy
- robust to overfitting
Disadvantages:
- combined classifier is not so transparent
- not compact
A10) Unsupervised Learning
In unsupervised learning, the data is unlabeled. This could be because the data is unfamiliar to us or there is too much data to label or we are just more interested in finding patterns among the data.
One of the goals of the world's largest radio telescope is to detect alien life. In collecting the data, we wouldn't know which signals are from aliens and which are just whatever is out there since we've never seen alien signals before. This would be an example of anomaly detection, where we want to identify things that do not conform to an expected pattern.
If we were working with images, we could download hundreds of millions of images, but some of them may or may not be labeled. In this case, it would be way too much work to go through each picture and label them manually (if only there was something that would automatically do this for us!)
Sometimes, applying an unsupervised algorithm before applying a supervised algorithm can improve prediction results. Let's say we were trying to classify digits and we came across some digits that looked like this:
To us, it's obvious which ones are the 3s and which one is the 8, but a computer might think that the left 3 and the 8 are more similar to each other since they are only several pixels different from each other. To avoid this, we can categorize the data first like so:
And then apply a supervised algorithm on each category to make classification more accurate.
A11) Big Data
Data science is currently a hot topic 🔥 because we have:
- new sources of data that did not exist before
- social media, sensors, internet
- new capabilities to acquire, store, and process data
- small and cheap sensors
- cost of storage has dropped significantly
- new techniques in data analytics and processing
Big data is any data that is expensive to manage or difficult to process. The three Vs of big data are volume, velocity, and variety. Volume: big data is usually large in size. Velocity: processing big data is time consuming. Variety: big data can come from different sources and in different formats.
A11.1) Scalability
In order to handle all this data, the machines and processes involved should be scalable, which means they should continue working as the amount of data grows.
A11.1.1) Scaling Up
Scaling up means increasing the resources (memory, CPU, disk size) for one machine. It can be very fast for medium-scale problems, but it requires expensive, specialized hardware and the resources will eventually hit a limit in the amount they can be upgraded.
A11.1.2) Scaling Out
Scaling out means adding more computers. All of them work in parallel so that the work is distributed among them. It is usually cheaper than scaling up and works for massive-scale problems, but network communication and the software to work with each other need to be handled properly.
A11.2) Sampling
If we have too much data to handle, the easy way out is to only use part of the data, but this isn't ideal because we are throwing away a large part of the data. Let's say we want to randomly sample the dataset anyway. How many samples would be enough?
We could plot the size of the training dataset against the error (see learning curve and bias-variance tradeoff), which might look something like this:
The error for the training dataset will always be lower than the error for the testing dataset because the model has already seen the data in the training dataset. Adding more data makes the training data more complex (less generalizable), so the training error will increase as the training dataset size increases. But more data also makes the model more experienced in predicting future data, so the testing error will decrease as the training dataset size increases.
Sometimes we could get something like this:
This suggests that using more data samples won't help, so we could find out how many samples to use based on this.
A11.3) MapReduce
MapReduce is a programming model for processing big data with a parallel, distributed algorithm. It involves a map function, which processes the data and generates intermediate data that gets sent to a reduce function that takes in the intermediate data and produces the final output.
A11.3.1) Word Counting
To see this in action, let's suppose we have millions of documents and we want to find the most common word across all of them. First, we distribute the documents among a bunch of computers to split the work.
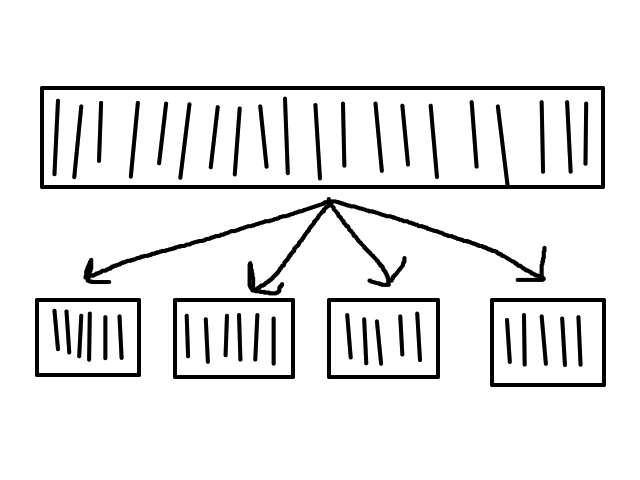
Then each computer runs a map function that returns a list of all the words and the number of times each word appears.
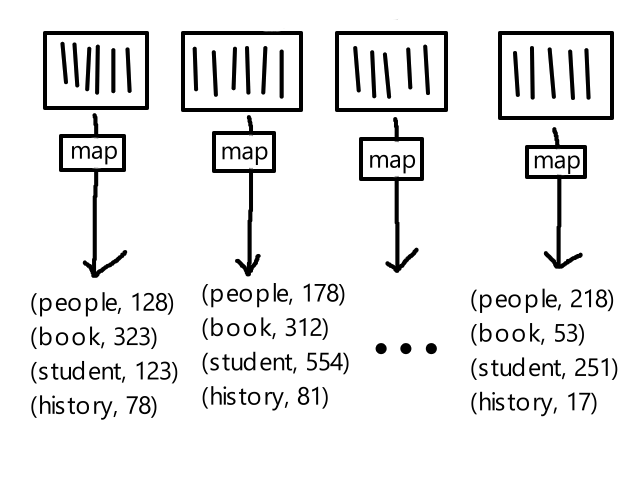
Now we need to combine the results from all the documents so we add more computers and each one will be responsible for adding the counts for a single word. (With actual big data, each computer would be responsible for a set of words instead of just one word.) This step is also called shuffling.

Finally, each of these computers runs a reduce function that returns the word count of each word.
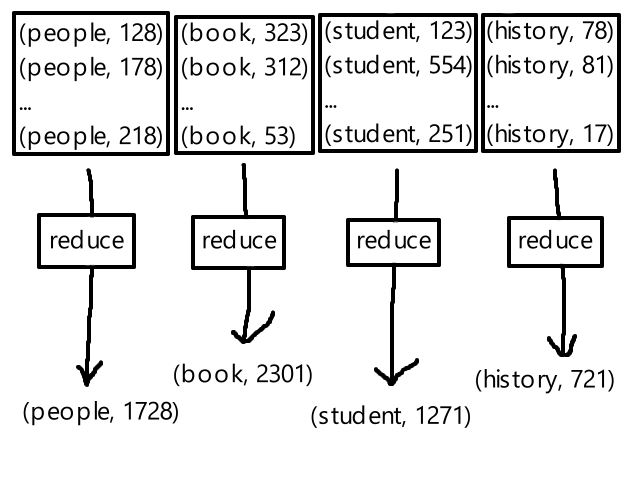
This is the general format of map and reduce functions.
function map(in_key, in_value) {
return [(out_key, intermediate_value)];
}
function reduce(out_key, [intermediate_values]) {
return [(out_key, out_value)];
}
In the above word-counting example:
- in_key: document id
- in_value: document contents
- intermediate_value(s): word counts before documents are combined
- out_key: word
- out_value: word count after documents are combined
`text(documents) ubrace(rarr)_(text(map)) (text(word), text(count)_i) ubrace(rarr)_(text(shuffle)) (text(word), [text(count)_1, text(count)_2, ...]) ubrace(rarr)_(text(reduce)) (text(word), text(count))`
A11.3.2) General Notes
For MapReduce, all the data processed and produced is in the form of key-value pairs.
In the mapping stage, parallelism is achieved by using different computers to process the data simultaneously. These computers are called mappers. In the reducing stage, parallelism is achieved by using different computers to handle multiple keys simultaneously. These computers are called reducers.
Mappers create the keys and reducers don't (reducers only work with the keys).
All the mappers need to finish before the reducers can start doing their thing.
The general flow is:
- Split big data into chunks and distribute among `n` computers
- Each computer runs a map function to convert each entry into a key-value pair
- Shuffle the key-value pairs so that pairs with common keys are combined
- (common key, [value1, value2, ...])
- Distribute the shuffled results among `m` computers
- Each computer runs a reduce function to convert each key-value pair into a single output
A11.3.3) SQL Inner Join
Suppose we had two databases `R` (with columns `A`, `B`) and `S` (with columns `B`, `C`):
| `A` | `B` |
|---|---|
| 6 | 2 |
| 12 | 2 |
| 7 | 5 |
| `B` | `C` |
|---|---|
| 2 | 9 |
| 5 | 11 |
| 5 | 3 |
| 9 | 5 |
If we were to inner join `R` and `S`, the result would be:
| `A` | `B` | `C` |
|---|---|---|
| 6 | 2 | 9 |
| 12 | 2 | 9 |
| 7 | 5 | 11 |
| 7 | 5 | 3 |
Performing an inner join on two large tables can be very computationally intensive, so MapReduce can be used to parallelize the process. For each table, it can be divided up among several mappers and each mapper would do the following:
`(a,b) rarr (text(key)=b,text(value)=(T,a))`
where `(a,b)` is a row in the table
and `T` represents which table the row is from
So after all the mappers are done, the result is:
`(2, (R, 6))`
`(2, (R, 12))`
`(5, (R, 7))`
`(2, (S, 9))`
`(5, (S, 11))`
`(5, (S, 3))`
`(9, (S, 5))`
And they are shuffled to get:
`(2, {(R, 6),(R, 12),(S, 9)})`
`(5, {(R, 7),(S, 11),(S, 3)})`
`(9, {(S, 5)})`
Now these shuffled key-value pairs get sent to reducers and each reducer would do the following:
`(b, {(T,a_1),(T,a_2),...,(T',c_1),(T',c_2),...}) rarr (a,b,c)`
where `a in {a_1,a_2,...}` and `c in {c_1,c_2,...}`
So after all the reducers are done, the result is:
`(6,2,9)`
`(12,2,9)`
`(7,5,11)`
`(7,5,3)`
which is the result of performing an inner join on `R` and `S`.
`text(tables) ubrace(rarr)_(text(map)) (b,(T,a_i)) ubrace(rarr)_(text(shuffle)) (b,{(T,a_1),(T,a_2),...(T',c_1),(T',c_2)}) ubrace(rarr)_(text(reduce)) (a_i,b,c_j)`
A11.3.4) Matrix-Vector Multiplication
Suppose we had an `mxxn` matrix `M` and an `nxx1` vector `V` where `m=2,n=3`:
`M=[[2,3,6],[6,10,7]]`
`V=[[5],[9],[2]]`
If we were to multiply `M` with `V`, the result would be an `nxx1` vector:
`[[49],[134]]`
If `M` is very large, then multiplying `M` with `V` can be very computationally intensive, so MapReduce can be used to parallelize the process. `M` is divided up among `n` mappers so that each mapper gets one column of `M`. Each mapper multiplies each element in the column with the corresponding element in `V` and produces the intermediate output:
`((i,j),a_(i,j)) rarr (i,a_(i,j)cdotv_j)`
So after all the mappers are done, the result is:
Mapper 1:
`(1, 2cdot5)`
`(2, 6cdot5)`
Mapper 2:
`(1, 3cdot9)`
`(2, 10cdot9)`
Mapper 3:
`(1, 6cdot2)`
`(2, 7cdot2)`
And they are shuffled to get:
`(1, {2cdot5,3cdot9,6cdot2})`
`(2, {6cdot5,10cdot9,7cdot2})`
Now these shuffled key-value pairs get sent to `m` reducers and each reducer adds all the values together. So after all the reducers are done, the result is:
Reducer 1: `(1, 49)`
Reducer 2: `(2, 134)`
which is the result of multiplying `M` by `V`.
`text(rows of matrix) ubrace(rarr)_(text(map)) (i,a_(i,j)cdotv_j) ubrace(rarr)_(text(shuffle)) (i,{a_(1,1)cdotv_1,a_(1,2)cdotv_2,...}) ubrace(rarr)_(text(reduce)) (i,a_(1,1)cdotv_1+a_(1,2)cdotv_2+...)`
A11.4) Gradient Descent
Let's bring back the formula for gradient descent:
`theta_j=theta_j-alpha1/msum_(i=1)^m(h_theta(bb x^((i)))-y^((i)))cdotx_j^((i))`
If we had a dataset with 100 million samples, then that means we need to perform a summation over 100 million samples for each iteration of gradient descent, which can take a long time. So we can make some modifications to gradient descent to make it faster.
A11.4.1) Stochastic Gradient Descent
Instead of waiting for the summation over 100 million samples to finish before taking a step towards the minimum, stochastic gradient descent takes a step after calculating the cost for each data sample.
`theta_j=theta_j-alpha(h_theta(bb x^((i)))-y^((i)))cdotx_j^((i))`
So it calculates the error for one data sample and takes a step. Then it moves on the next data sample and takes a step. And so on until all the data samples have been used.
While regular gradient descent (aka batch gradient descent) takes a lot of time to make one good step, stochastic gradient descent takes little time to make one suboptimal step. And even though it's faster, it may never reach the minimum, but it can get close enough.
A11.4.2) Mini-Batch Gradient Descent
Batch gradient descent uses all the data samples to take a step and stochastic gradient descent uses only one data sample to take a step. Mini-batch gradient descent is something in between these two and uses `b` samples to take a step.
`theta_j=theta_j-alpha1/bsum_(i=k)^(k+b-1)(h_theta(bb x^((i)))-y^((i)))cdotx_j^((i))`
A11.4.3) MapReduce for Gradient Descent
Yep, MapReduce is back. If we really want to use all the data samples with no modifications to gradient descent, then we can use MapReduce.
Let's say we had a dataset of 400,000 samples. We could distribute them among 4 mappers so that each mapper processes 100,000 samples when calculating the cost. Then a reducer would combine the results and add the costs together to get the overall cost.
Mapper 1: `text(temp)_j^((1))=sum_(i=1)^(100000)(h_theta(bb x^((i)))-y^((i)))cdotx_j^((i))`
Mapper 2: `text(temp)_j^((2))=sum_(i=100001)^(200000)(h_theta(bb x^((i)))-y^((i)))cdotx_j^((i))`
Mapper 3: `text(temp)_j^((3))=sum_(i=200001)^(300000)(h_theta(bb x^((i)))-y^((i)))cdotx_j^((i))`
Mapper 4: `text(temp)_j^((4))=sum_(i=300001)^(400000)(h_theta(bb x^((i)))-y^((i)))cdotx_j^((i))`
Reducer: `theta_j=theta_j-alpha1/400000(text(temp)_j^((1))+text(temp)_j^((2))+text(temp)_j^((3))+text(temp)_j^((4)))`